BatchRendererGroup のサンプル:低予算デバイスでも高フレームレートを実現




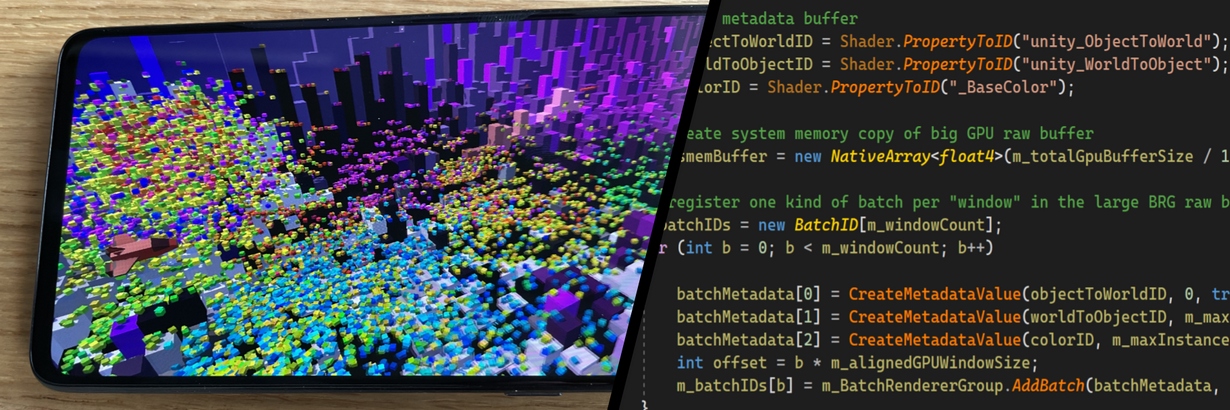

この記事では、いくつかのインタラクティブなオブジェクトをアニメーション化してレンダリングする、小規模なシューティングゲームのサンプルについて説明します。多くのデモはハイエンド PC 専用に作成されていますが、ここでの目標は、GLES 3.0 を使用して低予算なスマートフォンで高フレームレートを実現することです。このサンプルでは、BatchRendererGroup、Burst コンパイラー、および C# Job System を使用しています。Unity 2022.3 で動作し、entities および entities.graphics の DOTS パッケージは必要ありません。
それでは、始めましょう。
サンプルのご紹介
早速、サンプルの中身を見てみましょう。このサンプルは、2019 年に発売された低予算な Samsung Galaxy A51(Mali G72-MP3 GPU を使用)で 60fps で安定動作しています。グラフィックス API は GLES 3.0 に設定されています。
GitHub からプロジェクトをダウンロードすることにより、コードについて学習し、好きなプラットフォームで試すことができます。手元に必要なものは Unity 2022.3 だけです。
この記事では、主に BatchRendererGroup とサンプルクラス BRG_Container.cs に注目します。また、BRG_Background.cs および BRG_Debris.cs クラスでのアニメーションと物理演算コードについて学習することもできます。
シーンの設定
作成方法の詳細を知る前に、見てわかることを確認してみます。
- 背景のフロアは、多数のキューブで構成されています。ボックスはすべてアニメーション化されており、上下に移動しています。
- メインの戦闘機は画面上を水平に移動し、色の付いた球体に向けてミサイルを撃ち込んでいます(画面をタップすると、さらに高速でミサイルを撃ち込むことができます)。
- ミサイルがフロアの上を飛行すると、磁場でフロアセルがわずかに浮き上がり、ハイライトされます。また、地面の破片が空中に飛ばされたりもします。
- ミサイルが球体に命中すると、爆発して色の付いた破片になります。
- 破片がフロアに衝突すると、フロアに衝突したセルが白く点滅します。セルに衝突する破片の数が多くなると、セルの色はより濃くなります。さらに、破片の重みで地面にくぼみができます。
レンダリング
フロアセルも破片もキューブで構成されています。各キューブは、位置と色が異なっています。フロアと破片の間のインタラクションをより簡単にするために、CPU を使用してすべてのものをアニメーション化し、管理します(破片は単なる表面的な画像ではないため、GPU のみでは表現できません)。
レンダリングについては、ローエンドのモバイルデバイスで不必要なパフォーマンスヒットを回避するために、要素ごとにゲームオブジェクトを作成してはいません。代わりに、新しく導入された BatchRendererGroup API を使用しています。
従来の Graphics.DrawMeshInstanced を使用しない理由
Graphics.DrawMeshInstanced は、異なる位置で多数の類似したメッシュをレンダリングするための便利で高速な方法です。ただし、BatchRendererGroup API と比較して、以下の制限があります。
- 行列を含むマネージメモリ配列を提供する必要があるため、ガベージコレクションが発生する可能性があります。また、シェーダーが必要としない場合でも(例えば、URP/unlit の場合)、反転行列は CPU で計算されます。
- obj2world 行列以外のプロパティをカスタマイズする場合(インスタンスごとに 1 つの色を持つような場合)、最初から記述するか、またはシェーダーグラフを使用して、独自のカスタムシェーダーを提供する必要があります。
- 描画のたびに、行列またはカスタムデータを GPU メモリにアップロードする必要があります。Graphics.DrawMeshInstanced により GPU メモリデータを永続化することはできません。コンテキストによっては、これが大きなパフォーマンスヒットになる可能性があります。
BatchRendererGroup とは
BatchRendererGroup(または BRG)は、C# から描画コマンドを効率的に生成し、GPU インスタンス化ドローコールを生成する API です。マネージメモリを使用しないため、Burst コンパイラーを使用してコマンドを生成することもできます。
| メリット | デメリット |
| Burst ジョブから DrawInstanced コマンドを即座に生成する機能がある | 最適な描画コマンドのバッチを自分で生成する必要がある |
| インスタンスごとにカスタムプロパティを保存するために、永続化された大きな GPU バッファを使用している | GPU メモリとカスタムプロパティのオフセット割り当てを、自分で管理する必要がある |
| OpenGLES 3.0 以降を含む、幅広いプラットフォームでサポートされている | |
| 標準の SRP シェーダー(lit および unlit)と互換性がある。カスタムシェーダーを記述する必要はない |
ヒント:entities.graphics パッケージは、エンティティ(ECS パッケージ)をレンダリングするために作成されており、BRG を活用して構築されています。entities.package は、すべての GPU メモリを管理し、最適な描画コマンドを作成します。このサンプルでは ECS を使用していないため、BRG を直接使用します。
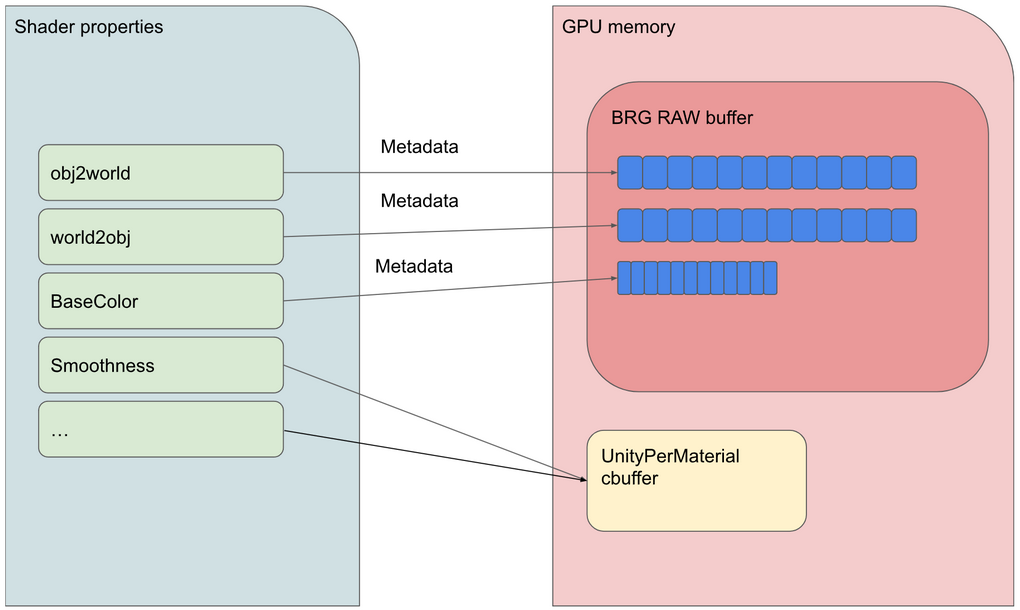
BRG シェーダーデータモデル
BRG では、特定の GPU データレイアウトと専用のシェーダーバリアントを使用します。シェーダーバリアントは、標準の定数バッファ(UnityPerMaterial)またはカスタムの大きな GPU バッファ(BRG Raw バッファ)からデータをフェッチできます。シェーダーストレージバッファオブジェクト(SSBO、バイトアドレスバッファ)である Raw バッファにデータをどのように保存するかは、ユーザーが決定して管理します。デフォルトの BRG データレイアウトは、配列の構造体(SoA)タイプです。
インスタンスごとのプロパティ
カスタムシェーダーを作成しなくても、マテリアルのすべてのプロパティをインスタンス化できます。サンプルでは、obj2world 行列(キューブの配置用)、world2obj 行列(ライト用)、ボックスインスタンスごとの BaseColor をインスタンス化しています(各フロアセルや破片が独自の色を持っているため)。
他のすべてのプロパティはすべてのキューブで同じであり(滑らかさ値など)、メタデータを使用して、インスタンスごとにカスタム値を持つプロパティを記述できます。
BRG メタデータ
BRG メタデータは、シェーダープロパティごとに設定できる任意の 32 ビット値です。これにより、GPU メモリからプロパティ値をロードする方法と場所をシェーダーコードに伝えます。ビット 0~30 は、BRG Raw バッファ内のプロパティのオフセットを定義し、ビット 31 は、プロパティ値がすべてのインスタンスで同じであるか、またはオフセットがインスタンスごとに 1 つの値を持つ配列の先頭であるかを示します。
BRG メタデータの正確な意味は、シェーダープロパティタイプにも依存します。以下に、すべての可能性をまとめて示します。
| シェーダープロパティ | BRG メタデータ未定義 | BRG メタデータ定義済み、ビット 31 はクリア | BRG メタデータ定義済み、ビット 31 はセット |
| 「マテリアルごとの」任意のプロパティ(「BaseColor」など) | 標準の UnityPerMaterial 定数バッファ | 標準の UnityPerMaterial 定数バッファ | BRG Raw バッファ、配列(インスタンスごとに 1 つの値) |
| obj2world、world2obj、 MatrixPreviousM、 MatrixPreviousM | 未定義。シェーダーバリアントがこれらのプロパティを使用する場合は、メタデータを定義する必要がある | BRG Raw バッファ、すべてのインスタンスで同じ値 | BRG Raw バッファ、配列(インスタンスごとに 1 つの値) |
| LODFade、RenderingLayer、MotionVectorsParams、WorldTransformParams |
| ||
| SHAx、SHBx、SHC ProbesOcclusion | グローバル SH は Unity により自動的に指定、すべてのインスタンスで同じ値 | BRG Raw バッファ、すべてのインスタンスで同じ値 | BRG Raw バッファ、配列(インスタンスごとに 1 つの値) |
| 重要:ライトグレーのセルはインスタンスごとに異なる 1 つの値を表し、青のセルはすべてのインスタンスで同じ 1 つの値を表します。 | |||

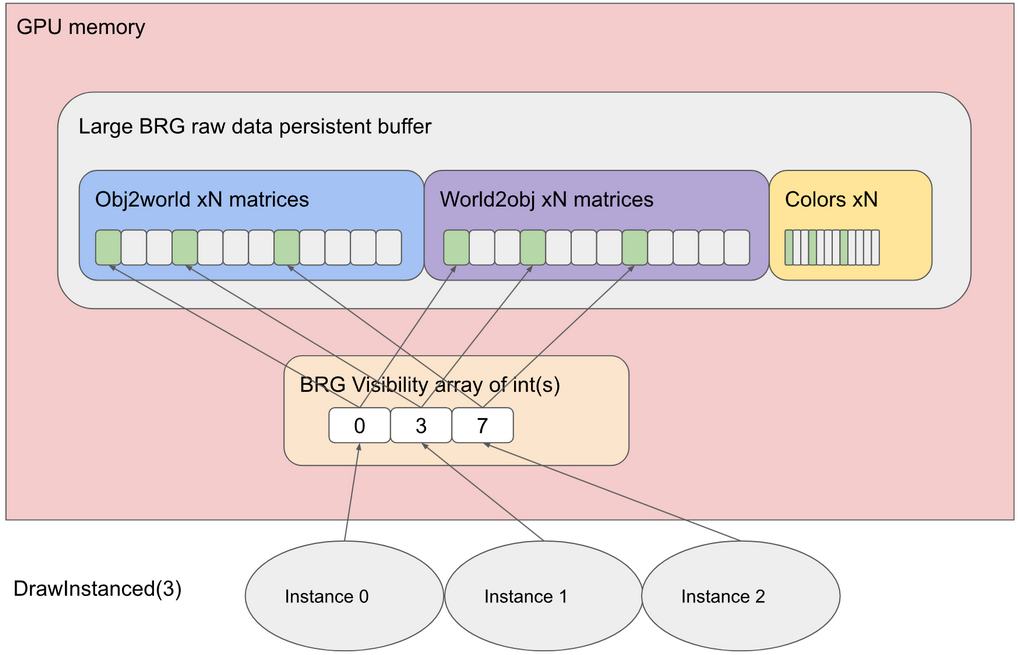
BRG カリングおよび可視性インデックス
BRG は、Graphics.DrawMeshInstanced とは異なり、永続化された GPU メモリバッファを使用します。例えば、Raw バッファに 10 個のキューブの位置と色があるが、キューブ 0、3、7 だけが見える位置にあるとします。3 個のキューブを描画するだけですが、シェーダーがそれらのキューブの位置と色を適切に読み込む必要があります。そうするために、BRG シェーダーは小さな追加のインダイレクションを使用します。この可視性バッファは、描画コマンドを生成する際に入力する「int」の配列に過ぎません。
この例では、int 型変数を 3 つ入力できる配列に {0,3,7} を入力してから、3 つのインスタンスの BRG 描画コマンドを生成する必要があります。

「baseColor」プロパティをフェッチするシェーダーコードは次のようになります。
if ( metadata_baseColor&(1<<31) )
{
// get the real index from the visibility buffer indirection
int visibleId = brg_visibility_array[GPU_instanceId];
uint base = (metadata_baseColor&0x7ffffffc);
uint offset = visibleId * sizeof(baseColor);
// fetch data from a custom array in BRG raw buffer
baseColor = brg_raw_buffer.Load( base + offset );
}
else
{
// fetch data from UnityPerMaterial (as usual)
baseColor = UnityPerMaterial.baseColor;
}
| サンプルの詳細な説明:SRP シェーダー(unlit、simplelit、lit)のいずれのプロパティもインスタンス化できるため、すべてのマテリアルプロパティには「if metadata&(1<<31)」分岐があります。インスタンスごとにカスタムの滑らかさの値が必要ない場合でも、パフォーマンスが多少犠牲になります。サンプルでは、baseColor をインスタンス化しているだけです。BRG でインスタンス化可能として定義されるのは色のみであるという、シェーダーグラフを作成することができます。そのため、生成されたコードには、color プロパティに対してのみ大量のデータフェッチインダイレクションがあります。シェーダーは、ローエンドの GPU でも若干高速に動作するはずです。 |
フロアセルのレンダリング
ゲームサンプルでは、フロアは 32x100 のセル、つまり 3,200 個のセルで構成されています。各セルには、位置、高さ、色が指定されており、カメラを固定したままセルをスクロールできます。ある列がビューからスクロールアウトすると、32 個のセルからなる新しい列が挿入されます。

任意の時点で 3,200 個までのセルについては、カリングは実際には必要ありません(すべてのセルが常にカメラのビュー内に収まります)。各セルを配置するには、セルごとの obj2world 行列、ライト用の反転行列、および色が必要になります。全フロアをレンダリングするために、単一の BRG 描画コマンドを使用します。
爆発破片のレンダリング

サンプルの破片は小さなキューブで構成されており、それぞれに位置、色、そして垂直軸に対する回転速度が設定されています。これは、フロアセルと非常に似ています。このように構成するために、BRG_Container.cs を作成しました。クラスが BRG オブジェクトを管理し、フロアセルまたは爆発破片をレンダリングします。物理演算を用いたアニメーションとインタラクションはすべて、BRG_Debris.cs を使用して C# コードで実行されます。
破片の量は、フロアセルの場合とは異なり、フレーム間で変動します。初期化時に、BRG_Container に対して最大項目数を指定します。サンプルでは、破片の数は 16,384 個(各爆発は 1,024 個の破片キューブで構成されています)であり、重力場内の破片をアニメーション化するために非同期ジョブを使用しています。破片がフロアセルに衝突すると、地面に食い込んで相互作用します。
BRG 行列形式
GPU メモリのストレージと帯域幅を最適化するために、BRG では float4x4 の代わりに float3x4 を使用して、行列を保存しています。Raw バッファ内の BRG 行列は 64 バイトではなく 48 バイトであることに注意してください。

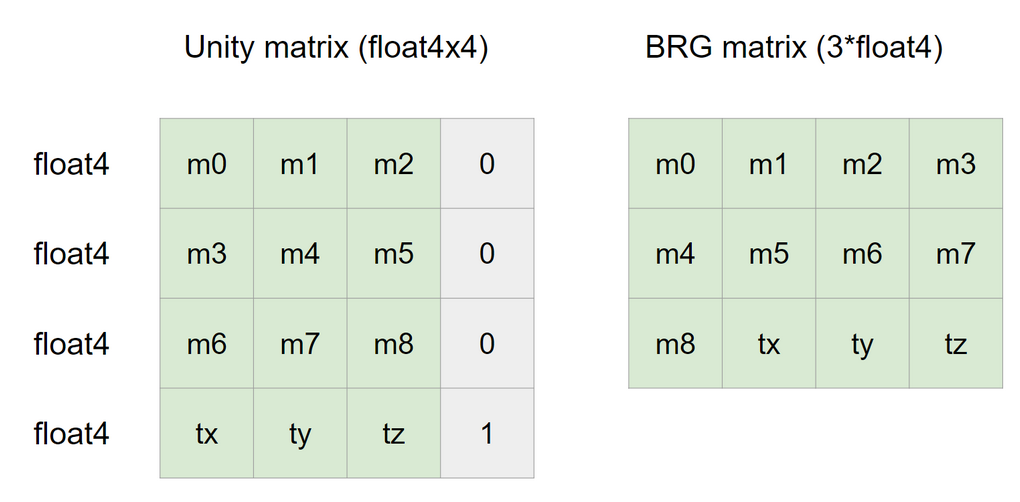
Raw バッファは次のようになります。


ヒント:破片の Raw バッファデータでも、3 つのカスタムプロパティ(obj2world、world2obj、color)を使用しているため、フロアデータと似ています。破片の場合、最大項目数は 16,384 であり、これは 112x16,384 バイト、つまり 1.75MiB の Raw バッファを使用します。特定の時点で存在する破片キューブの数にもよりますが、たいていの場合、すべての破片がレンダリングされることはありません。
フロアセルのアニメーション化
GPU GraphicsBuffer は 358,400 バイトです。アニメーションは CPU で実行するため、システムメモリに同等のバッファを割り当てます(CPU はシステムメモリ内のデータをフルスピードで処理できます)。この 2 つ目のバッファを、GPU メモリの「シャドウコピー」と呼ぶことにします。C# コードでは、sin を使用してフロアセルを、またシャドウコピーから破片をアニメーション化します。アニメーションを実行したら、GraphicsBuffer.SetData API を使用して、シャドウコピーバッファを GPU にアップロードします。
|
サンプルの詳細な説明:GPU レンダリングの最適化とは、多くの場合、データ量の最適化を意味します。サンプルでは、標準および既存の SRP シェーダーを使用しています。そのため、行列に 3 つの float4、色に 1 つの float4 を使用しました。さらに、カスタムシェーダーを記述してデータサイズを削減するか、または 32 ビットのフロアセルの高さの値を使用することができます。 このまま続行する場合は、セルのインデックスを使用してワールド位置を計算してから、シェーダーで行列と反転行列を計算します。そして、32 ビット整数を使用して色を保存します。最後に、項目ごとに 112 バイトではなく 8 バイトをアップロードします。これにより、GPU データアップロード時のスピードが 14 倍アップします。これは、シェーダーフェッチコードを再記述することを意味します。 |
BRG BatchID
BRG 描画コマンドでは、MeshID、MaterialID、BatchID が必要になります。最初の 2 つは容易に理解できますが、BatchID とは何でしょうか。ここでは、BatchID とは「バッチの種類」と考えましょう。フロアをレンダリングするには、以下のように定義されたバッチを 1 種類、登録する必要があります。
- 「unity_ObjectToWorld」プロパティは、BRG Raw バッファのオフセット 0 から開始される配列です
- 「unity_WorldToObject」プロパティは、オフセット 153,600 から開始される配列です
- 「_BaseColor」プロパティは、オフセット 307,200 から開始される配列です
作成時にこの種類のバッチを登録するコードは次のようになります。
int objectToWorldID = Shader.PropertyToID("unity_ObjectToWorld");
int worldToObjectID = Shader.PropertyToID("unity_WorldToObject");
int colorID = Shader.PropertyToID("_BaseColor");
var batchMetadata = new NativeArray<MetadataValue>(3, Allocator.Temp, NativeArrayOptions.UninitializedMemory);
batchMetadata[0] = CreateMetadataValue(objectToWorldID, 0, true); // matrices
batchMetadata[1] = CreateMetadataValue(worldToObjectID, 3200*3*16, true); // inverse matrices
batchMetadata[2] = CreateMetadataValue(colorID, 3200*3*16*2, true); // colors
m_batchId = m_BatchRendererGroup.AddBatch(batchMetadata, m_GPUPersistentRawBuffer.bufferHandle, 0, 0);作成時に m_batchId を取得してから、各 BRG 描画コマンドに使用することができます(シェーダーは、該当する種類のバッチのデータをフェッチする方法を正確に認識しています)。
ヒント:BatchRendererGroup.AddBatch はレンダリングコマンドではありません。将来実行されるレンダリングコマンドのために、1 種類のバッチを登録するために使用されます。
細部に存在する問題点:GLES 例外
現時点では、フロアセルをアニメーション化して、シャドウコピーシステムのメモリバッファを GPU にアップロードし、3,200 インスタンスの 1 つの DrawCommand を使用してすべてのセルをレンダリングすることができます。
これは、DirectX、Vulkan、Metal、その他さまざまなゲームコンソールなど、大部分のプラットフォーム上で動作しますが、GLES 上では動作しません。問題となるのは、大部分の GLES 3.0 デバイスが頂点ステージ中に SSBO にアクセスできない(つまり、GL_MAX_VERTEX_SHADER_STORAGE_BLOCKS 値が 0 である)ことです。そのため、グラフィックス API が GLES に設定されている場合、BRG は代わりに定数バッファ(UBO)を使用して、Raw データを保存します。
これにより、次のような制約が加わります。定数バッファは任意のサイズにできますが、シェーダーが実行されている際には常に、その一部(1 つのウィンドウ)しか表示できません。ウィンドウサイズはハードウェアとドライバーに依存しますが、広く受け入れられている値は 16KiB です。
ヒント:UBO モードでは、常に BatchRendererGroup.GetConstantBufferMaxWindowSize() API を使用して、正しい BRG ウィンドウサイズを取得する必要があります。
GLES 上で実行する場合、コードがどのように変化するか確認してみましょう。フロアセルの場合、データの総量は 350KiB です。シェーダーは一度に 350KiB を認識できないため、1 つの DrawInstanced(3,200) を実行することはできません。そのため、16KiB ブロックに収まるように、UBO 内でデータを分割して、描画ごとのインスタンス量を最大化する必要があります。1 つのフロアセルは 112 バイト(2 つの行列と 1 つの色)であるため、16,384 を 112 で除算した値、つまり 146 インスタンスを 16KiB ブロックに収めることができます。3,200 インスタンスをレンダリングするには、21 のDrawInstanced(146) と最後に DrawInstanced(134) を発行する必要があります。
これで、350KiB の UBO は、次のようにそれぞれが 16KiB の 22 のウィンドウブロックに分割されます。

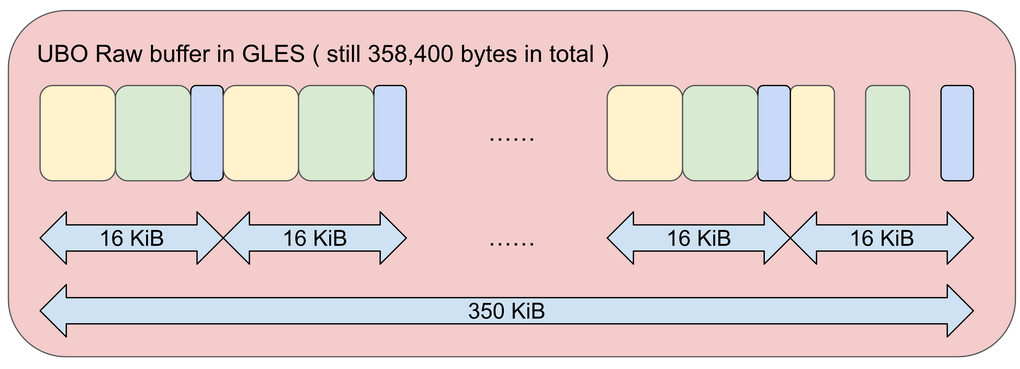
ヒント:UBO モードでは、各ウィンドウのオフセットを、BatchRendererGroup.GetConstantBufferOffsetAlignment() に合わせて揃える必要があります。代表的な整列値の範囲は 4~256 バイトです。
GLES では、UBO と 16KiB ウィンドウが原因で、各ウィンドウのオフセットを保存するために、22 の BatchID を登録する必要があります。そのため、次に示すように、初期化コードでは 1 つのループが必要になります。
// Register one BatchID per 16KiB window, using the right offsets
m_batchIDs = new BatchID[m_windowCount];
for (int b = 0; b < m_windowCount; b++)
{
batchMetadata[0] = CreateMetadataValue(objectToWorldID, 0, true); // matrices
batchMetadata[1] = CreateMetadataValue(worldToObjectID, m_maxInstancePerWindow * 3 * 16, true); // inverse matrices
batchMetadata[2] = CreateMetadataValue(colorID, m_maxInstancePerWindow * 3 * 2 * 16, true); // colors
int offset = b * m_alignedGPUWindowSize;
m_batchIDs[b] = m_BatchRendererGroup.AddBatch(batchMetadata, m_GPUPersistentInstanceData.bufferHandle, (uint)offset,(uint)m_alignedGPUWindowSize);
}
ヒント:ゲームサンプルで GLES(UBO)と他のグラフィックス API(SSBO)をサポートするために、初期化時に BRG_Container.cs で、いくつかの var を設定します。SSBO モードでは、m_windowCount は 1 であり、m_alignedGPUWindowSize は合計バッファサイズです。UBO モードでは、m_alignedGPUWindowSize は 16KiB であり、m_windowCount には 16KiB ブロックの数が含まれています(わかりやすくするために、値を 16KiB にしています。GetConstantBufferMaxWindowSize() API を使用して、正しい値を取得してください)。
データのアップロード
CPU がシステムメモリの行列と色をすべて更新したら、データを GPU にアップロードできます。これを実行するには、BRG_Container.UploadGpuData 関数を使用します。SoA データモデルであるため、単一ブロックのメモリはアップロードできません。破片の場合、バッファの項目数は 16,384 です。GLES モードでは、16,384 個の破片が画面上にある場合、それぞれが 16KiB の 113 個のウィンドウを使用します。
しかし、ある特定のフレームに破片キューブが 5,300 個しかない場合はどうでしょうか?1 つのウィンドウに 146 個の項目があるため、これは最初の 36 個の連続した 16KiB のウィンドウをアップロードする必要があることを意味しており、1 つの SetData(36x16KiB)を使用することができます。最後のウィンドウには、44 個の破片キューブだけが表示されているはずです。44 の行列をアップロードするには、行列と色を反転させて、3 つの SetData コマンドを使用します。最後に、4 つの SetData コマンドを発行する必要があります。

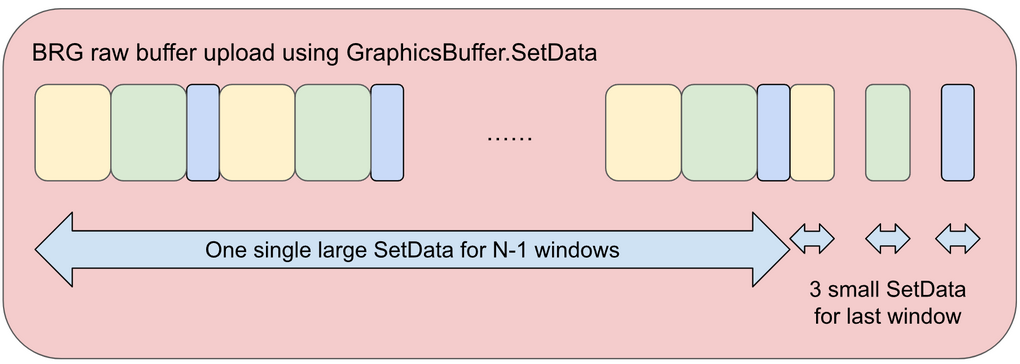
ヒント:SSBO モードの場合でも、項目数が最大値より少ない場合(例えば、最大値 16,384 個に対して 5,300 個の破片がある場合)、3 つの SetData コマンドが必要になります。実装の詳細については、BRG_Container.UploadGpuData(int instanceCount) を参照してください。
メインの BRG ユーザーコールバック
BRG のメインのエントリーポイントは、作成時に指定するカリングコールバック関数です。サンプルは次のとおりです。
public JobHandle OnPerformCulling(BatchRendererGroup rendererGroup, BatchCullingContext cullingContext, BatchCullingOutput cullingOutput, IntPtr userContext)このコールバックのコードでは、以下の 2 つの操作を実行します。
- すべての描画コマンドを、出力用 BatchCullingOut 構造体に生成する
- BatchCullingContext 読み取り専用構造体で提供される情報を、独自のカリングコード内で使用する(または使用しない)
注:このコールバックは、これらの操作を実行するために非同期ジョブを起動する必要がある場合に、JobHandle を返します。エンジンは、結果が必要になる時点でこれを使用して同期するため、コマンド生成コードがメインスレッドをブロックすることはありません。
BatchCullingContext には、カメラ行列、カメラ錐台プランなどの情報が含まれています。基本的に、より少ない描画コマンドをカリングして生成するために必要なすべてのデータです。サンプルでは、すべてのオブジェクトがカメラビューに収まっているため(フロアセルと破片)、カリングコードを使用する必要はありません。
BatchCullingOutputDrawCommands 構造体には、配列を含む、さまざまなデータが含まれています。これらの配列にネイティブメモリを割り当てるのはユーザーです。データが消費されると、エンジンがそのメモリを解放します(つまり、ユーザーが割り当てて、Unity が解放します)。メモリ割り当ては、Allocator.TempJob タイプにする必要があります。
private static T* Malloc<T>(uint count) where T : unmanaged
{
return (T*)UnsafeUtility.Malloc(
UnsafeUtility.SizeOf<T>() * count,
UnsafeUtility.AlignOf<T>(),
Allocator.TempJob);
}
割り当てる必要がある最初の配列は、表示する項目を記載する int 配列です。サンプルでは、すべてが可視であると仮定しているため、表示する項目を記載する int 配列に {0,1,2,3,4,...} のように 1 ずつ増える値を入力するだけです。
描画コマンドの生成
BRG 描画コマンドは、たいていの場合、GPU DrawInstanced 呼び出しです。割り当てて入力する最も重要な配列は、BatchDrawCommand です。現在のフレームに、破片キューブが 4,737 個あるとします。
GLES モードでの m_maxInstancePerWindow は 146 です。次のようにして描画コマンドの量を計算し、m_instanceCount を m_maxInstancePerWindow で除算して切り上げした値を使用して、バッファを割り当てることができます。
int drawCommandCount = (m_instanceCount + m_maxInstancePerWindow - 1) / m_maxInstancePerWindow;
drawCommands.drawCommands = Malloc<BatchDrawCommand>((uint)drawCommandCount);複数の描画コマンドに似たようなパラメーターが複製されるのを回避するために、BatchCullingOutputDrawCommands には BatchDrawRange 構造体の配列があります。renderingLayerMask、シャドウフラグの受信など、BatchDrawRange.filterSettings 内でさまざまなパラメーターを設定できます。描画コマンドはすべて、同じレンダリング設定を共有するため、描画コマンド 0 から適用され、すべての drawCommandCount コマンドを含む単一の DrawCommandRange 構造体を割り当てることができます。
drawCommands.drawRanges[0] = new BatchDrawRange
{
drawCommandsBegin = 0,
drawCommandsCount = (uint)drawCommandCount,
filterSettings = new BatchFilterSettings
{
renderingLayerMask = 1,
layer = 0,
motionMode = MotionVectorGenerationMode.Camera,
shadowCastingMode = m_castShadows ? ShadowCastingMode.On : ShadowCastingMode.Off,
receiveShadows = true,
staticShadowCaster = false,
allDepthSorted = false
}
};次に、描画コマンドを入力します。各 BatchDrawCommand には、meshID、batchID(メタデータの使用方法を知るため)、materialID が含まれています。また、表示する項目を記載する int 配列バッファの開始オフセットも含まれています。コンテキストでは錐台カリングは必要ないため、表示する項目を記載する配列に {0,1,2,3,...} を入力します。そうすると、すべての描画コマンドは、同じ {0,1,2,3,...} インダイレクションを参照することになるため、各 BatchDrawCommand は 0 を表示する項目を記載する配列の開始オフセットとして使用することになります。以下のコードでは、必要な描画コマンドをすべて割り当てて入力しています。
drawCommands.drawCommands = Malloc<BatchDrawCommand>((uint)drawCommandCount);
int left = m_instanceCount;
for (int b = 0; b < drawCommandCount; b++)
{
int inBatchCount = left > maxInstancePerDrawCommand ? maxInstancePerDrawCommand : left;
drawCommands.drawCommands[b] = new BatchDrawCommand
{
visibleOffset = (uint)0, // all draw command is using the same {0,1,2,3...} visibility int array
visibleCount = (uint)inBatchCount,
batchID = m_batchIDs[b],
materialID = m_materialID,
meshID = m_meshID,
submeshIndex = 0,
splitVisibilityMask = 0xff,
flags = BatchDrawCommandFlags.None,
sortingPosition = 0
};
left -= inBatchCount;
}
まとめ:フォーラムでさらに知識を深めよう
BatchRendererGroup を直接使用するには、若干の作業が必要になります。ただし、カスタムシェーダーや追加のパッケージは必要なく、すぐに動作させることができます。カスタムのインスタンス化されたプロパティを持つ、CPU でシミュレーションされたオブジェクトを大量にレンダリングする必要があるような状況では、BatchRendererGroup が最適な方法です。
プロジェクトは、このリポジトリからダウンロードできます。
また、C# Job System と Burst コンパイラーを使用して、ローエンドの CPU 上でもすべてのアニメーションとインタラクションをフルスピードで処理する方法について、フォーラムでさらに深く議論することもできます。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies