Human-centric computer vision with Unity synthetic data



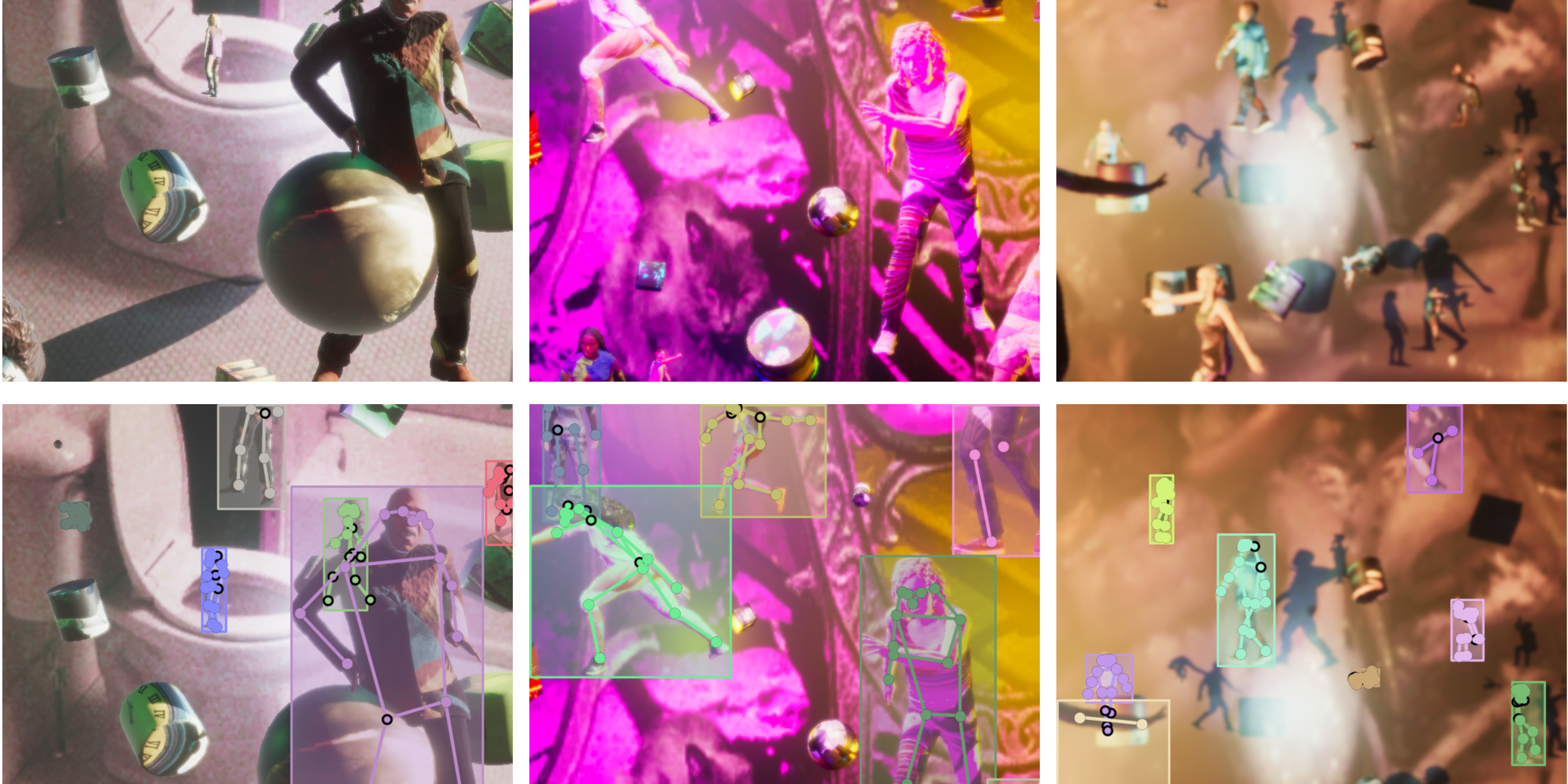
Header Image: Sample PeopleSansPeople images and labels. Top row: three sample generated synthetic images. Bottom row: the same images with generated bounding box and COCO pose labels.
Human-centered computer vision has seen great advancements in the past few years, helped by large-scale labeled human data. However, serious and important privacy, legal, safety, and ethical concerns limit capturing human data. Existing datasets also carry biases introduced at the time of data collection and data annotation, which negatively impact models trained with such data. Additionally, most existing human data provides no proper analysis of content diversity, human activities and poses, and domain-agnosticism. An emerging alternative to using real-world data that can help alleviate some of these issues is synthetic data (see our previous blog posts on Data-Centric AI with UCVD and Unlocking Intelligent Solutions in the Home with Computer Vision). However, creating synthetic data generators is challenging, which has prevented the computer vision community from taking advantage of synthetic data. Furthermore, researchers have been wondering whether synthetic data can help replace or complement existing real-world data mainly because of the lack of a highly-parametric, and highly-manipulable data generator that can be used as part of model training itself.
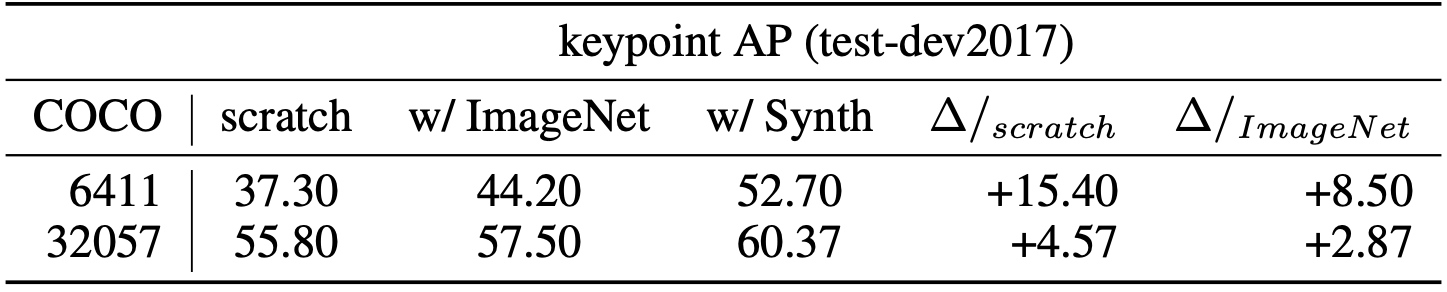
Motivated by the above challenges, Unity is delighted to present PeopleSansPeople which is a human-centric data generator that contains highly-parametric and simulation-ready 3D human assets, parameterized lighting and camera system, parameterized environment generators, and fully-manipulable and extensible domain randomizers. PeopleSansPeople can generate RGB images with sub-pixel-perfect 2D/3D bounding box, COCO-compliant human keypoints, and semantic/instance segmentation masks in JSON annotation files. Using PeopleSansPeople we performed benchmark synthetic data training using a Detectron2 Keypoint R-CNN variant. We found that pre-training a network using synthetic data and fine-tuning on target real-world data (few-shot transfer to limited subsets of COCO-person train) resulted in a keypoint AP of 60.37±0.48 (on COCO test-dev2017) outperforming models trained with the same real data alone (keypoint AP of 55.80) and pre-trained with ImageNet (keypoint AP of 57.50). Please see our paper for more details.
We envision that PeopleSansPeople will enable and accelerate research into the usefulness of synthetic data for human-centric computer vision. We created PeopleSansPeople bearing in mind how researchers may want to use synthetic data with domain randomization in tasks involving people as part of the target class, expanding the space of simulator capabilities in existing and new domains, like AR/VR, autonomous driving, and human pose estimation, action recognition, and tracking. We anticipate that the most exciting line of research with PeopleSansPeople data will involve generating synthetic data that bridges the simulation to real (sim2real) transfer learning and addressing the domain gap between the synthetic and real data.


PeopleSansPeople Release
We release two versions of PeopleSansPeople:
First, macOS and Linux executable binary files that can be used to generate large-scale (1M+) datasets with a variable configuration JSON file. It includes:
- 28 3D human models of varying age and ethnicity, with varying clothing (21,952 unique clothing textures from 28 albedos, 28 masks, and 28 normals);
- 39 animation clips, with fully randomized humanoid placement, size, and rotation, to generate diverse arrangements of people;
- Fully-parameterized lighting (position, color, angle, and intensity) and camera (position, rotation, field of view, focal length) settings;
- A set of object primitives to act as distractors and occluders with variable textures; and
- A set of 1600 natural images from the COCO unlabeled set to act as backgrounds and textures for objects.
Second, we release a Unity template project that helps lower the barrier of entry for the community, by helping them get started with creating their own version of a human-centric data generator. The users can bring their own sourced 3D assets into this environment and further its capabilities by modifying the already-existing domain randomizers or defining new ones. This environment comes with the full functionalities described for the binary files above, expect with:
- 4 example 3D human models with varying clothing colors;
- 8 example animation clips, with fully randomized humanoid placement, size, and rotation, to generate diverse arrangements of people; and
- A set of 529 natural images of grocery items from the Unity Perception package to act as backgrounds and textures for objects.
PeopleSansPeople Domain Randomization in Unity
PeopleSansPeople is a parametric data generator that exposes several parameters for variation via a simple JSON configuration file. Alternatively, the users have the ability to change these configurations from the Unity environment directly as well. Since our main topic of interest revolves around a human-centric task, much of our domain randomization and environment design went into creating fully-parametric models of humans. With such parameter sets, we are able to capture some fundamental intrinsic and extrinsic aspects of variations for our human models. We vary the clothing texture of our human assets using our Unity Shader Graph randomizer, which produces unique looks for the characters as shown in Fig 3 and 4. We also change the pose of the characters using our animation randomizer with a diverse set of animations that cover many realistic human actions and poses as shown in Fig 5.




To train models that can generalize to the real domain, we rely on additional domain randomization that varies the aspects of the simulation environment to introduce more variation in the synthetic data. Our randomizers act on predefined Unity scene components. They change the parameters of these components during simulation by sampling from possible ranges for those parameters, using normal, uniform, and binomial distributions. In brief, we randomize aspects of the 3D object placement and pose, the texture and colors of the 3D objects in the scene, the configuration and color of the lighting, the camera parameters, and some post-processing effects. Certain types of domain randomization, such as the lighting, hue offset, camera rotation/Field of View/Focal Length, mimic standard data augmentations’ behavior. Hence, no data augmentation is needed during synthetic data training, which speeds up the training process.
Dataset Statistics Analysis
Using our domain randomization we generated synthetic datasets of 500,000 images along with labels described above. We use 490,000 of those images for training and 10,000 for validation. We compare our synthetic dataset statistics to the COCO person dataset. Our dataset has an order of magnitude more instances and also an order of magnitude more instances with keypoint annotations than COCO as shown in Tab 1.
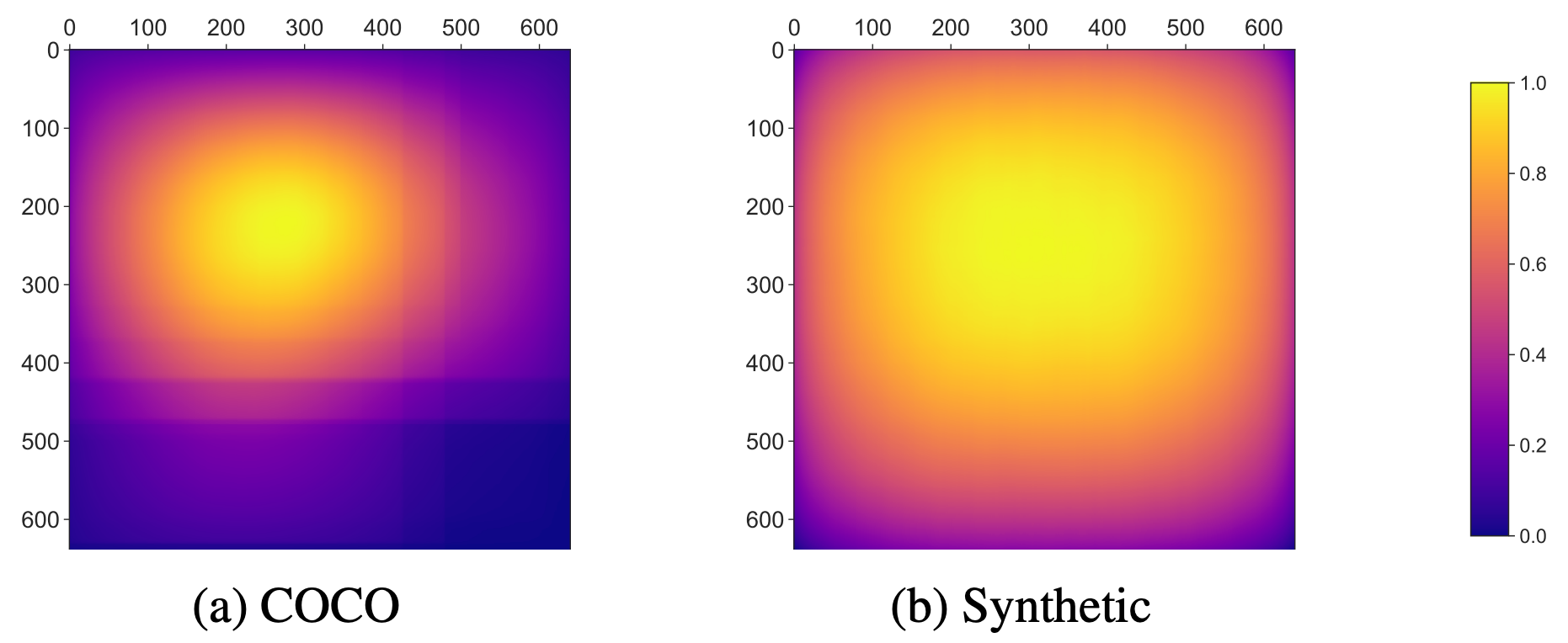
In Fig 6 we show bounding box occupancy heatmaps for the three datasets. For the COCO dataset, since there are many portrait and landscape images, we observe oblong bounding box distributions tailing along with the image’s height and width. We find the majority of the boxes near the center of most images and less spreading to the edges. For the PeopleSansPeople Synthetic data, the boxes tend to occupy the entire image frame better, and as such forcing the model to use the entire receptive field.



In Fig 7 we show the bounding box and keypoint statistics comparisons. We see from these statistics that our dataset has more bounding boxes per image than COCO, whilst COCO has mostly 1 or 2 bounding boxes per image (Fig 7a). Also, our dataset has more homogenous bounding box size distributions, whilst COCO has mostly small boxes (Fig 7b). Most bounding boxes in our dataset have all the keypoints annotated, while this is not true for most boxes in COCO (Fig 7c). And finally, for boxes that have keypoint annotations, our dataset is doubly as likely to have annotations for individual keypoints (Fig 7d).

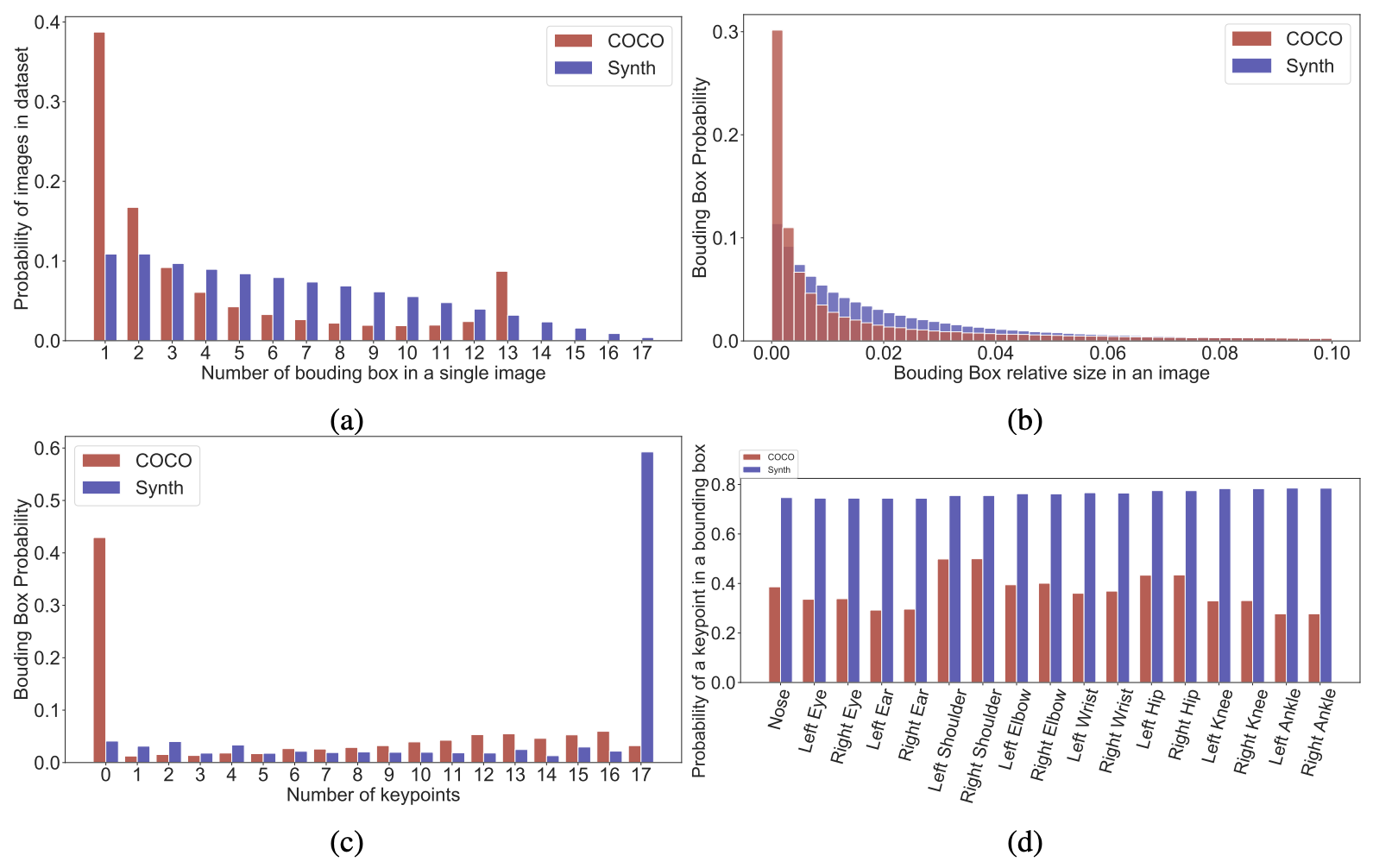
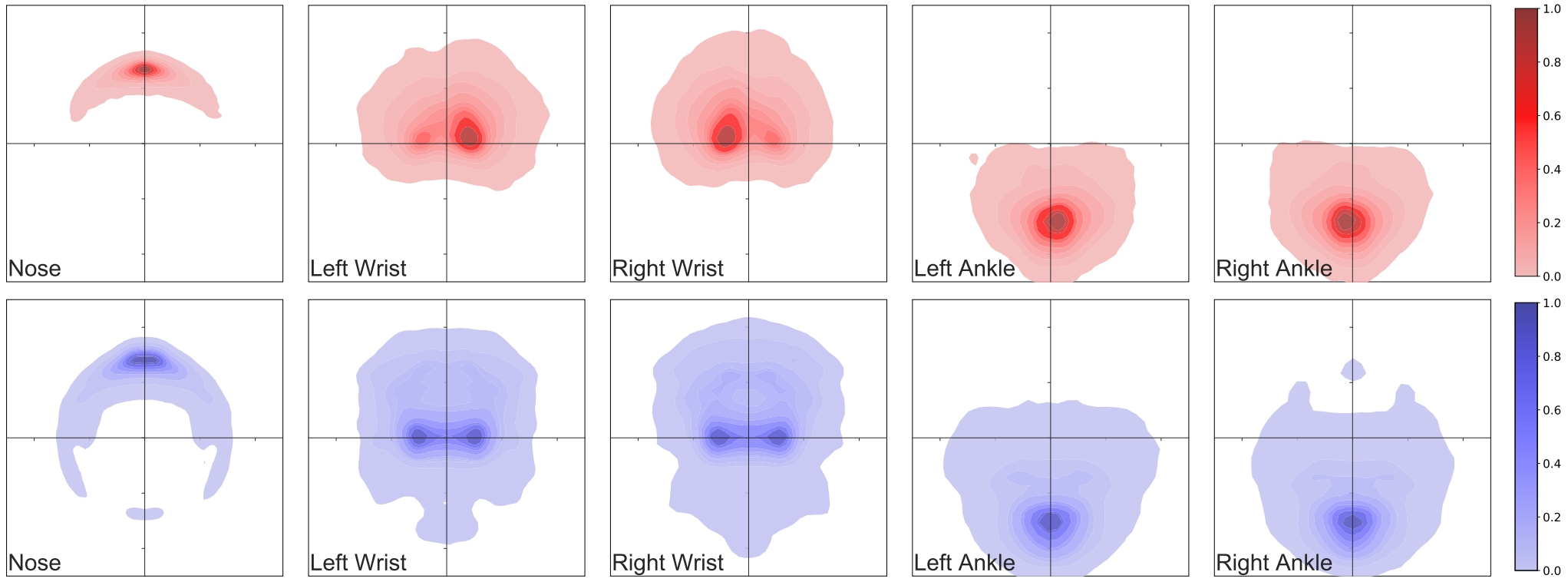
Lastly, to quantify the pose diversity of our human models in the generated images, we generated the pose heatmaps for five representative keypoints from the extremities of the character which tend to demonstrate the largest displacements in Fig 8. We observe that 1) the distribution of PeopleSansPeople poses encompass the distribution of poses in COCO; 2) the distribution of our synthetic poses is more extensive than for COCO; and 3) in COCO, most people are front-facing, leading to an asymmetry with “handedness” in the density of points which is absent in our synthetic data.

Benchmarking out-of-the-box Impact of PeopleSansPeople
To obtain a set of benchmark results on simulation to real transfer learning, we trained on various synthetic and real dataset sizes and combinations for person bounding box (bbox) and keypoint detection. We report our results on the COCO person validation (person val2017) and test sets (test-dev2017) using Average Precision (AP) as the primary metric for model performance.
We trained our models from randomly initialized weights, and also from ImageNet pre-trained weights. We did not perform any model or data generation hyper-parameters in any of our benchmarks. In fact we generated our dataset using the default parameter ranges we chose intuitively and brute-forced data generation by uniform sampling from these ranges. Hence our data generation is very naïve. We show our results in Tab. 2, 3, and 4. We observe that using synthetic data pre-training and real data fine-tuning, our models out-perform the ones trained only on real data alone or pre-trained with ImageNet and then fine-tuned on real data. This effect is stronger in few-shot transfer learning with limited real data. With abundant real data, we still observe the advantages of synthetic data pre-training.



It is important to note that these results are aimed to serve the purpose of benchmarking PeopleSansPeople data. PeopleSansPeople comes with highly-parameterized randomizers, and it is straightforward to integrate custom randomizers into it. Therefore, we expect that PeopleSansPeople will enable research into hyper-parameter tuning and data generation in the model training loop to optimize the performance of such data for solving zero-shot, few-shot, and fully-supervised tasks. Also, since synthetic data comes with abundant high-quality labels, it can be coupled with real data with few to no annotations to achieve weakly-supervised training.
Conclusions
In this blog post, we presented our research on human-centric computer vision using Unity’s synthetic data. We created a highly-parameterized synthetic data generator affectionately-named PeopleSansPeople which is aimed at enabling and accelerating research into the usefulness of synthetic data for human-centric computer vision. PeopleSansPeople provides fine control over simulation parameters and domain randomization, opening up avenues for meta-learning and data generation in the model training loop. To validate and benchmark the provided parameterization of PeopleSansPeople, we conducted a set of benchmarks. These benchmarks showed that model performance is improved using synthetic data, even using naïvely-chosen randomization parameters. We expect that PeopleSansPeople and these benchmarks will enable a wide range of research into the simulation to reality domain gap, including but not limited to model training strategies, data hyper-parameter search, and alternative data generation manipulation strategies.
Please check the source code and paper on our human-centric data generator for more information.
For questions on our ongoing research, reach out to our Applied Machine Learning Research team.
If you are interested in generating custom human datasets beyond what the open source project can provide, reach out to our computer vision team.
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies