Unity 合成データを用いた人間中心型のコンピュータービジョン



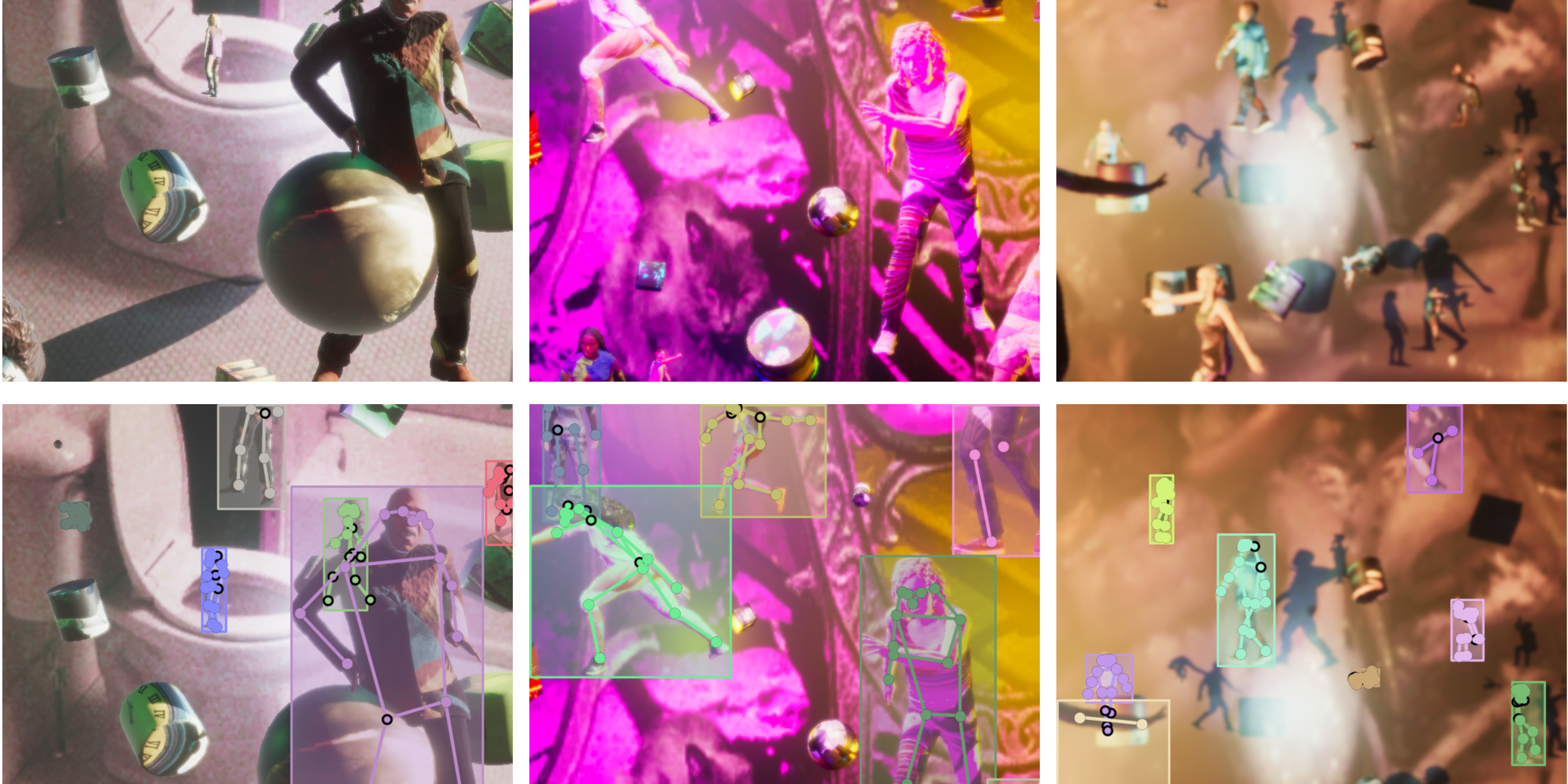
人間中心のコンピュータービジョンは、大規模でラベル付きの人間のデータのおかげで、ここ数年で大きな進歩を遂げています。しかし、プライバシー、法律、安全性、倫理面での深刻かつ重要な問題により、人間のデータを取得することには限界があります。また、既存のデータセットには、データ収集時やデータのアノテーション時に生じたバイアスが含まれており、そのようなデータを用いて学習すると、モデルに悪影響を与えます。さらに、既存のほとんどの人間のデータは、コンテンツの多様性、人間の活動やポーズ、ドメイン非依存性などに関する適切な分析を行っていません。このような問題を軽減するために、実世界のデータを使用する代わりに、合成データが登場しています(過去のブログ記事「Unity Computer Vision Datasets を使ったデータ中心型 AI」や「コンピュータービジョンで住居内のインテリジェントソリューションを実現する」をご覧ください)。しかし、合成データを作成することの困難さが、コンピュータービジョンの分野での合成データ活用を妨げていました。また、研究者たちは、合成データが既存の実世界データの代替や補完に役立つかを疑問視してきました。なぜなら、モデル学習そのものの一部として使われうる、高度にパラメトリックでかつ高度に制御可能なデータ生成器があまり存在しなかったからです。
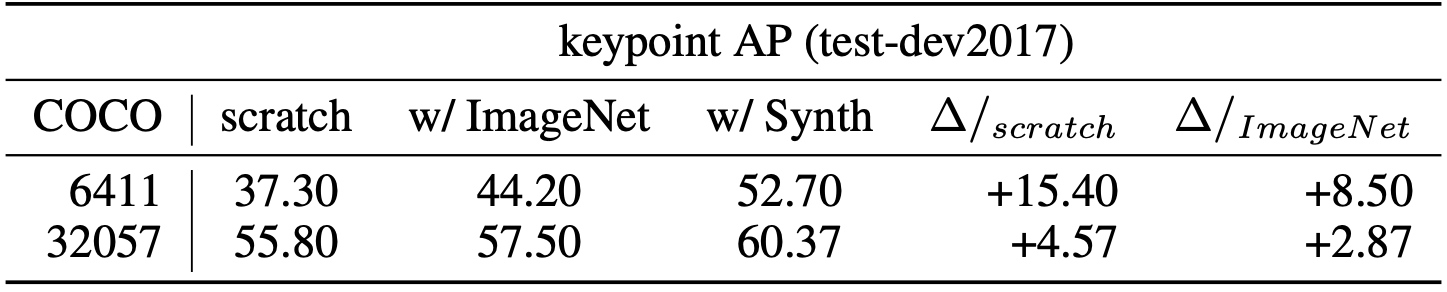
上記の課題に触発され、Unity は PeopleSansPeople を発表します。これは、高度にパラメトリックでシミュレーションに適した 3D ヒューマンアセット、パラメーター化されたライティングとカメラのシステム、パラメーター化された環境ジェネレーター、そして完全に制御可能かつ拡張性に富むドメインランダマイザーを含む、人間中心型のデータ生成器です。PeopleSansPeople は、サブピクセルパーフェクトな 2D および 3D バウンディングボックス、COCO 準拠のヒューマンキーポイント、セマンティック/インスタンスセグメンテーションマスクを JSON アノテーションファイルとして持つ RGB 画像を生成することができます。PeopleSansPeople と Detectron2 Keypoint R-CNN バリアントを用いて、ベンチマークとなる合成データによる学習を行いました。合成データを用いてネットワークを事前学習し、対象となる実データで微調整を行うことで(COCO Person train の制限付きサブセットに対する Few-shot transfer)、キーポイント AP が 60.37±0.48(COCO test-dev2017 上)となり、同じ実データのみで学習したモデル(キーポイント AP:55.80)や、ImageNet で事前学習したモデル(キーポイント AP:57.50)の性能を上回ることがわかりました。詳しくは、論文をご覧ください。
PeopleSansPeople は、人間中心のコンピュータービジョンのための合成データの有用性に関する研究を可能にし、加速させるであろうと考えています。PeopleSansPeople は、研究者が人間をターゲットクラスの一部として含むタスクにおいて、ドメインランダム化された合成データをどのように使用したいかということを念頭に置いて作成されており、AR/VR、自動運転、人間の姿勢推定、行動認識、追跡などの既存および新規のドメインにおいて、シミュレーターの機能を拡大します。PeopleSansPeople のデータを使った最もエキサイティングな研究は、シミュレーションからリアル(sim2real)への転移学習の橋渡しとなる合成データの生成と、合成データと実データの間のドメインギャップへの対処であると予想しています。


PeopleSansPeople リリース
PeopleSansPeople については、2 つのバージョンをリリースします。
まず、設定を変更することができる JSON ファイルで大規模(1M 以上)なデータセットを生成するために使用できる macOS および Linux 用の実行バイナリファイルです。これには以下のものが含まれます。
- 年齢や民族が異なり、衣服にバリエーション(28 個のアルベド、28 個のマスク、28 個の法線を組み合わせた 21,952 種類のユニークな衣服のテクスチャ)を持たせた 28 人の 3D 人体モデル。
- 多様な人間の配置の生成に使える、人型の配置、大きさ、回転が完全にランダム化された 39 個のアニメーションクリップ。
- 完全にパラメーター化された、ライティング(位置、色、角度、強度)とカメラ(位置、回転、視野、焦点距離)の設定。
- 視界を乱すための物体や遮蔽物として使える、さまざまなテクスチャが乗ったオブジェクトプリミティブのセット。
- COCO のラベルなしセットから選ばれた、1600 枚の自然の画像。オブジェクトの背景やテクスチャーとして使用可能。
2 つ目は、Unity のテンプレートプロジェクトとしてのリリースです。これはコミュニティへの参入障壁を下げ、独自の人間中心型データ生成器の開発を支援するためのものです。ユーザーはこの環境に独自の 3D アセットを持ち込み、既存のドメインランダマイザーに手を加えたり、新しいドメインランダマイザーを定義することで、その機能をさらに高めることができます。この環境には、上記のバイナリファイルについて紹介したすべての機能が搭載されているほか、下記の内容も含まれています。
- 衣服の色を変化させたサンプルの 3D 人体モデル 4 体。
- 多様な人間の配置の生成に使える、人型の配置、大きさ、回転が完全にランダム化された 8 個のアニメーションクリップ。
- オブジェクトの背景やテクスチャーとして使える、Unity Perception パッケージから選ばれた食料品の自然な画像 529 枚のセット。
Unity における PeopleSansPeople のドメインランダム化
PeopleSansPeople は、シンプルな JSON 設定ファイルを介して、いくつかのパラメーターを公開するパラメトリックデータ生成器です。また、ユーザーは Unity 環境から直接これらの設定を変更することもできます。今回のテーマは人間中心型のタスクであるため、人間の完全なパラメトリックモデルを作成するために、ドメインランダム化や環境の設計に多くの時間を費やしました。このようなパラメーターセットを用いることで、人間モデルのバリエーションの内在的なもの、外在的なものの両方について、その基礎となる要素を捉えることができます。Unity シェーダーグラフのランダマイザーを使って人間のアセットの服の質感を変化させ、図 3 と図 4 のようにキャラクターのユニークな表情を作り出しています。また、アニメーションのランダマイザーを使ってキャラクターのポーズを変更し、図 5 に示すように、リアルな人間のアクションやポーズを網羅した多様なアニメーションを作成しました。




現実のドメインに一般化できるモデルを学習するために、シミュレーション環境の複数の要素を変化させ、合成データにバリエーションを持たせるドメインランダム化を追加しています。Unity のランダマイザーは、定義済みの Unity のシーンコンポーネントに作用します。これらのコンポーネントのパラメーターは、正規分布、一様分布、二項分布を用いて、パラメーターが取りうる値の範囲からサンプリングして、シミュレーション中に変更されます。具体的には、3D オブジェクトの配置や姿勢、シーン内の 3D オブジェクトの質感や色、ライティングの設定や色、カメラのパラメーター、そしていくつかのポストプロセッシングエフェクトなどをランダム化します。ライティング、色相オフセット、カメラの回転、視野、焦点距離など、ある種のドメインランダム化は、標準的なデータ拡張の動作を模倣しています。そのため、合成データの学習時にデータ拡張が必要なく、学習プロセスを高速化することができます。
データセットの統計解析
ドメインランダム化を用いて、50 万枚の画像と上述のラベルからなる合成データセットを作成しました。そのうち 49 万枚を学習に、1 万枚を検証に使います。私たちの合成データセットの統計値を COCO Person データセットと比較します。私たちのデータセットは COCO に比べてインスタンスの数が桁違いに多く、キーポイントのアノテーションを持つインスタンスの数も桁違いに多いことが表 1 に示されています。
図 6 は、3 つのデータセットのバウンディングボックス占有率のヒートマップです。COCO データセットでは、縦長の画像や横長の画像が多いため、長方形のバウンディングボックスの分布が画像の縦横に沿って尾を引いていく様子が見られます。ほとんどの画像では中央付近にボックスの大部分が集まり、端の方にはあまり広がっていないことがわかります。PeopleSansPeople の合成データでは、ボックスが画像フレーム全体をより隙間なく占める傾向があり、その結果、モデルは受容野全体を使うように誘導されます。



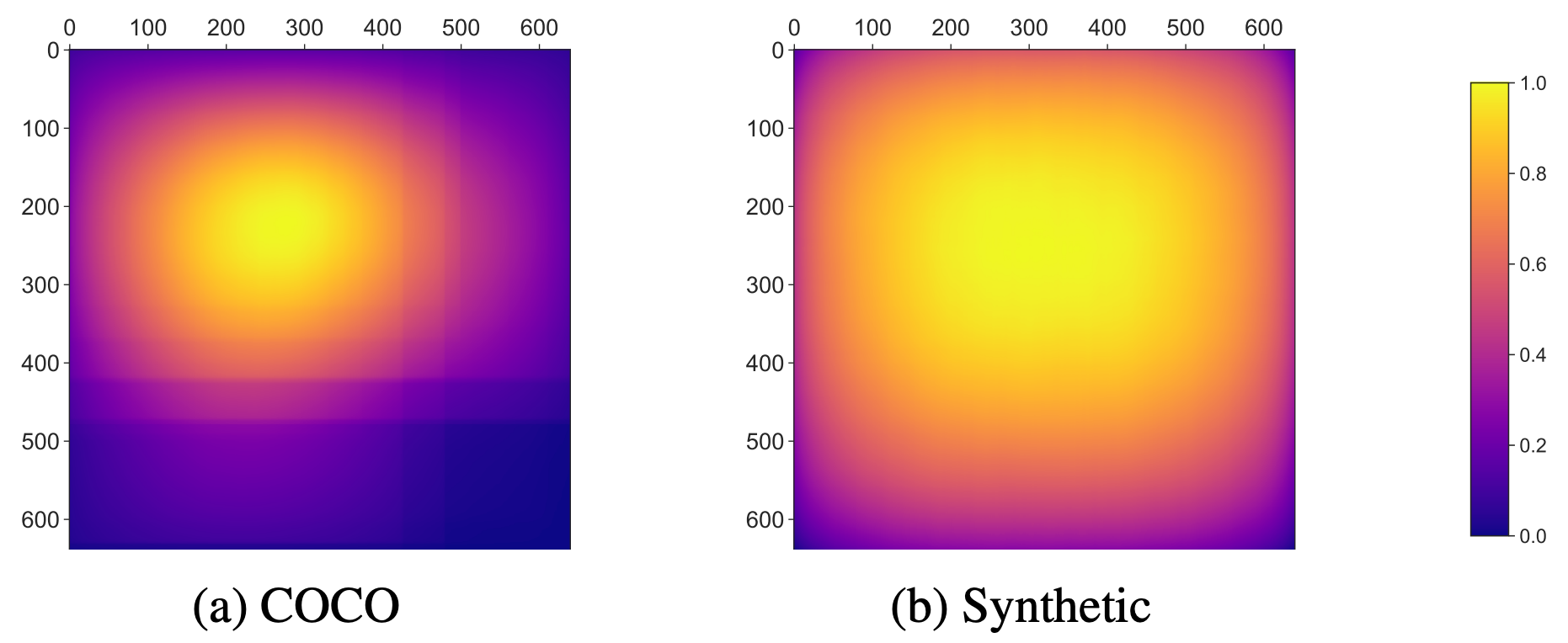
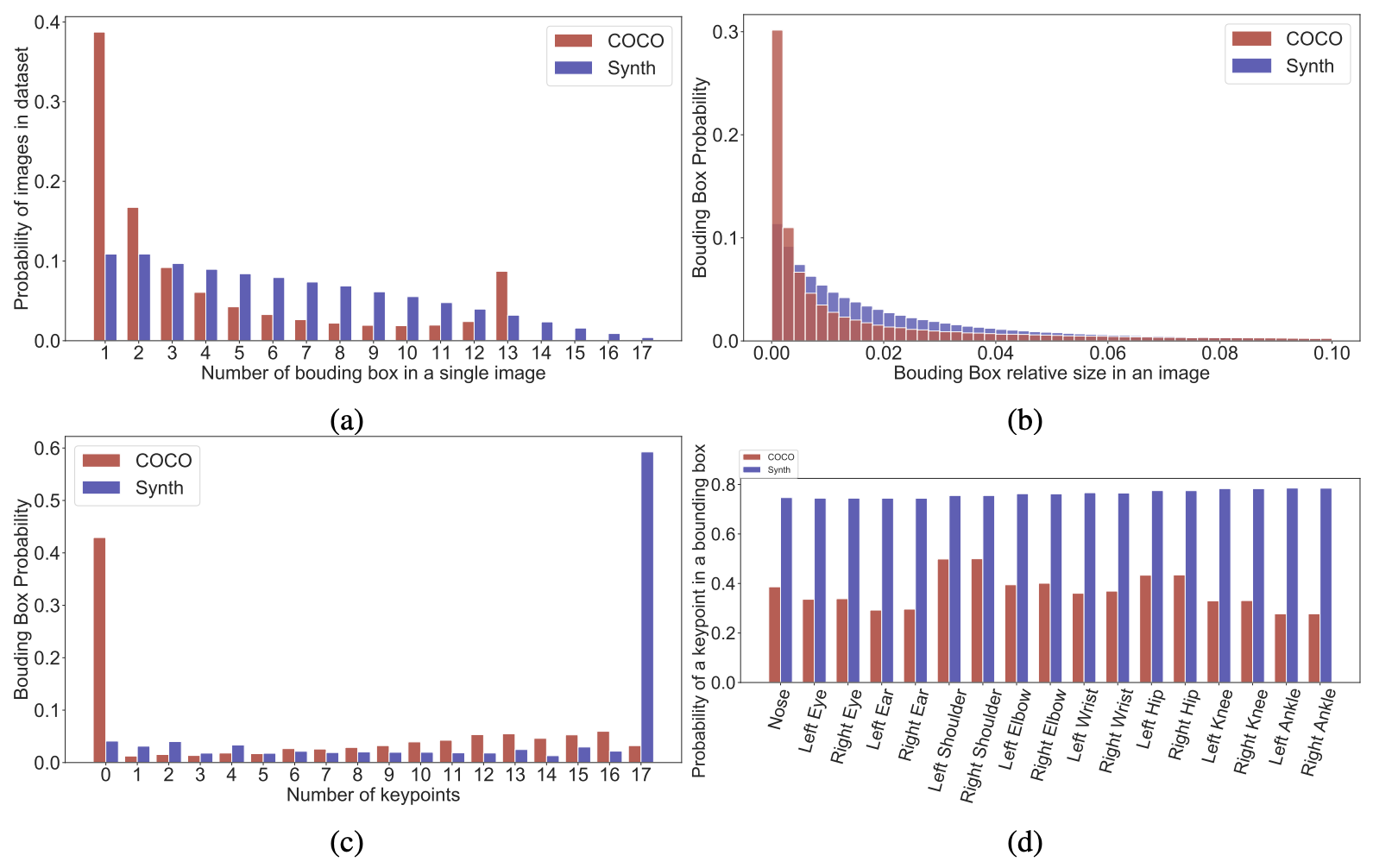
図 7 は、バウンディングボックスとキーポイントの統計量の比較です。これらの統計データから、私たちのデータセットは COCO よりも 1 画像あたりのバウンディングボックスの数が多く、COCO は 1 画像あたり 1 〜 2 個のバウンディングボックスがほとんどであることがわかります(図 7a)。また、COCO では小さなボックスが多いのに対し、私たちのデータセットではバウンディングボックスのサイズ分布がより均一になっています(図 7b)。私たちのデータセットでは、ほとんどのバウンディングボックスにすべてのキーポイントがアノテーションされていますが、COCO ではほとんどのボックスにアノテーションされていません(図 7c)。最後に、キーポイントのアノテーションがあるボックスについて、私たちのデータセットでは各キーポイントに対してアノテーションがある割合がおよそ 2 倍になっています(図7d)。

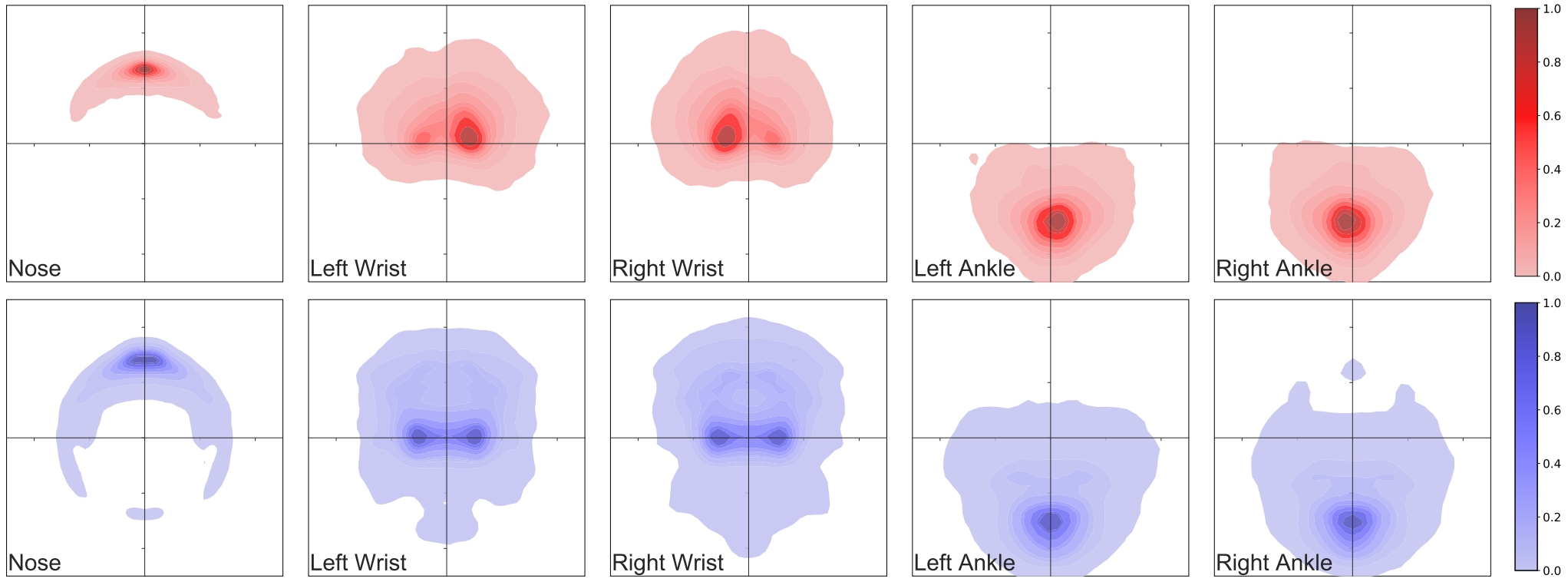
最後に、生成された画像における人間モデルのポーズの多様性を定量的に評価するために、図 8 で最も大きな変位を示す傾向があるキャラクターの四肢からの代表的な 5 つのキーポイントについて、ポーズのヒートマップを生成しました。1)PeopleSansPeople のポーズの分布は COCO のポーズの分布を包含していること。2)私たちの合成ポーズの分布は、COCO よりも広範囲であること。3)COCO では、ほとんどの人が正面を向いているため、私たちの合成データには見られない、ポイントの密度の「利き手」による非対称性が生じていることが観察されました。

PeopleSansPeople の既成概念にとらわれないインパクトのベンチマーク
シミュレーションから実物への転移学習に関する一連のベンチマーク結果を得るために、人物のバウンディングボックス(bbox)とキーポイントの検出について、さまざまなサイズの合成データと実物データの組み合わせで学習を行いました。COCO Person 検証セット(person val2017)と Test セット(test-dev2017)を対象に、モデルの性能を示す主要な指標として平均適合率(AP)を用いた結果を報告します。
ランダムに初期化された重みと、ImageNet で事前に学習された重みを用いてモデルを学習しました。どのベンチマークにおいても、モデルやデータ生成のハイパーパラメーターを実行しませんでした。実際には、直感的に選んだデフォルトのパラメータ範囲を使ってデータセットを作成し、その範囲から一様にサンプリングすることでブルートフォースでデータを生成しました。したがって、私たちのデータ生成は非常にナイーブなものです。その結果をタブ 2、3、4 に示します。実データのみで学習したモデルや、ImageNet で事前学習した後に実データで微調整したモデルよりも、合成データでの事前学習と実データでの微調整を行った私たちのモデルの方が優れていることが分かりました。この効果は、実データが限られている Few-shot 転移学習でより強く現れます。豊富な実データがある場合でも、合成データによる事前学習には利点があることがわかっています。



この結果は、PeopleSansPeople のデータのベンチマークでの利用を目的にしていることに注意してください。PeopleSansPeople には、高度にパラメーター化されたランダマイザーが搭載されており、カスタムのランダマイザーを簡単に組み込むことができます。そのため、PeopleSansPeople によって、Zero-shot、Few-shot、および完全教師付きのタスクを解決するために、ハイパーパラメーターのチューニングやモデル学習のループ内でのデータ生成の研究が可能になると期待しています。また、合成データには高品質なラベルが豊富に含まれているため、アノテーションがほとんどない実データと組み合わせることで、弱教師付き学習を実現することができます。
結論
このブログ記事では、Unity の合成データを使った人間中心型のコンピュータービジョンに関する研究を紹介しました。私たちは、高度にパラメーター化された合成データ生成器を作成しました。私たちは PeopleSansPeople という愛称で呼んでいますが、これは、人間中心型のコンピュータービジョンにおける合成データの有用性に関する研究を可能にし、加速させることを目的として開発されたものです。PeopleSansPeople では、シミュレーションのパラメーターやドメインランダム化を細かく制御できるため、モデルの学習ループにおけるメタ学習やデータ生成の道が開けます。PeopleSansPeople で提供されるパラメーター化の検証とベンチマークを目的とした一連のベンチマーク作業を行いました。これらのベンチマークでは、合成データを用いることで、ナイーブに選択されたランダム化パラメーターを用いてもモデルの性能が向上することが示されました。PeopleSansPeople とこれらのベンチマークによって、モデル学習の戦略、データのハイパーパラメーター検索、データ生成制御の代替戦略など、シミュレーションと現実の間のドメインギャップに関する幅広い研究が可能になると期待しています。
人間中心型のデータ生成器については、ソースコードと論文でその詳細をご確認ください。
現在進行中の研究に関するお問い合わせは、応用機械学習研究チームまでご連絡ください。
オープンソースプロジェクトで提供しているものを超えた、カスタムの人間データセットの作成にご関心がある場合は、Unity のコンピュータービジョンチームまでご連絡ください。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies