What’s next for computer vision: An AI developer weighs in






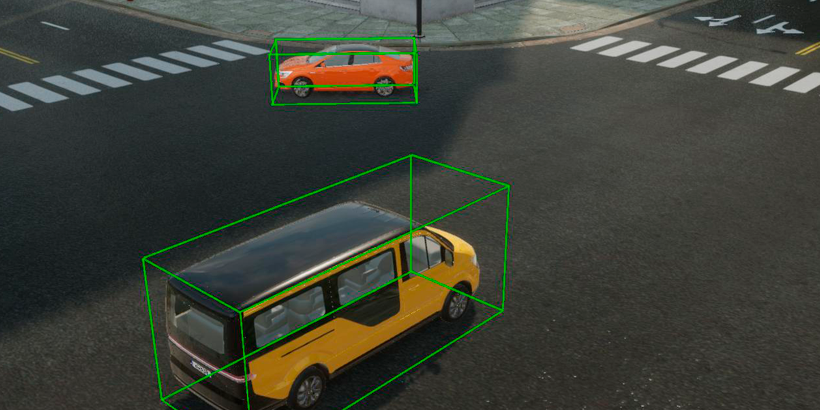
In this Q&A, get a glimpse into the future of artificial intelligence (AI) and computer vision through the lens of longtime Unity user Gerard Espona, whose robot digital twin project was featured in the Made with Unity: AI series. Working as simulation lead at Luxonis, whose core technology makes it possible to embed human-level perception into robotics, Espona uses his years of experience in the industry to weigh in on the current state and anticipated progression of computer vision.
Is computer vision becoming more accessible?
During recent years, computer vision (CV) and AI have become the fastest-growing fields both in market size and industry adoption rate. Spatial CV and edge AI have been used to improve and automate repetitive tasks as well as complex processes.
This new reality is thanks to the democratization of CV/AI. Increasingly affordable hardware access, including depth perception capability as well as improvements in machine learning (ML), has enabled the deployment of real solutions on edge CV/AI systems.
Spatial CV using edge AI enables depth-based applications to be deployed without the need of a data center service, and also allows the user to preserve privacy by processing images on the device itself.
Along with more accessible hardware, software and machine learning workflows are undergoing important improvements. Although they are still very specialized and full of technical challenges, they have become much more accessible, offering tools that allow users to train their own models.
What are the biggest challenges for computer vision?
Within the standard ML pipeline/workflow, large-scale edge computing and deployment can still pose issues. One of the biggest general challenges is to reduce the costs and timelines currently required to create and/or improve machine learning models on real-world applications. In other words, the challenge is how to manage all these devices to enable a smooth pipeline for continuous improvement.
Also, the implicit limitations in terms of compute processing need extra effort on the final model deployed on the device (that is, apps need to be lightweight, performant, etc.). That said, embedded technology evolves really fast, and each iteration is a big leap in processing capabilities.
Spatial CV/AI is a field that still requires a lot of specialization and systems. Workflows are often complicated and tedious due to numerous technical challenges, so a lot of time is devoted to smoothing out the workflow instead of focusing on value-added tasks.

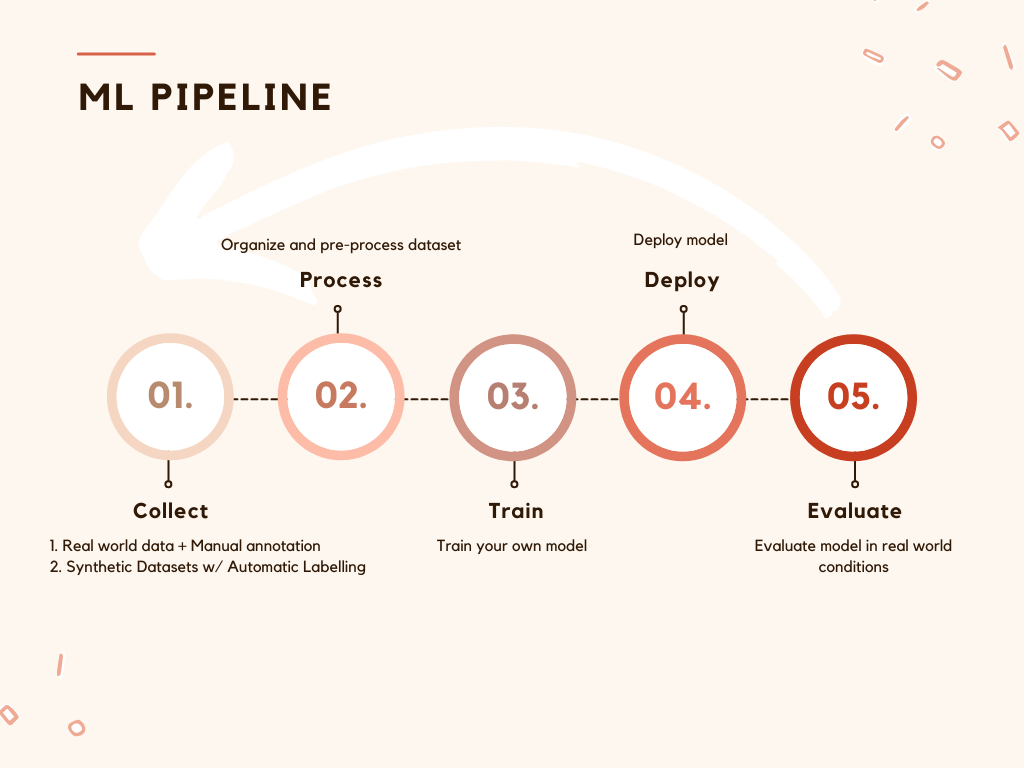
Creating datasets (collecting and filtering images and videos), annotating the images, preprocessing/augmentation process, training, deploying and closing the feedback loop for continuous improvement is a complex process. Each step of the workflow is technically difficult and usually involves time and financial cost, and more so for systems working in remote areas with limited connectivity.
At Luxonis, we help our customers build and deploy solutions to solve and automate complex tasks at scale, so we’re facing all these issues directly. Our mission, “Robotic vision made simple,” provides not only great and affordable depth-capable hardware, but also a solid and smooth ML pipeline with synthetic datasets and simulation.
Another important challenge is the work that needs to be done on the interpretability of models and the creation of datasets from an ethical, privacy and bias point of view.
Last but not least, global chip supply issues are making it difficult to get the hardware into everybody’s hands.


Why is data-centric AI important?
Data-centric AI is potentially useful when a working model is underperforming. Investing a large amount of time to optimize the model often leads to almost zero real improvement. Instead, with data-centric AI the investment is in analysis, cleaning and improving of the dataset.
Usually when a model is underperforming, the issue is within the dataset itself, as there is not enough data for the model to outperform. This could be the result of two possible reasons: 1) the model needs a much larger amount of data, which is difficult to collect in the real world, or 2) the model doesn’t have enough examples of rare cases, which take a lot of time to happen in the real world.
In both situations, synthetic datasets could help.
Thanks to Unity’s computer vision tools, it is very easy to create photorealistic scenes and randomize elements like materials, light conditions and object placement. The tools come with common labels like 2D bounding boxes, 3D bounding boxes, semantic and instance segmentation, and even human body key points. Additionally, these can be easily extended with custom randomizers, labelers and annotations.



Why do we need human-centric computer vision?
Almost any task you want to automate or improve using edge CV/AI very likely involves detecting people for obvious safety and security reasons. It’s critical to guarantee user safety around autonomous systems or robots when they’re working, requiring models to be trained on data about humans.
That means we need to capture a large amount of images, including information like poses and physical appearance, that are representative of the entire human population. This task raises some concerns about privacy, ethics and bias when starting to capture real human data to train the model.
Fortunately, we can use synthetic datasets to mitigate some of these concerns using human 3D models and poses. A very good example is the work done by the Unity team with PeopleSansPeople.


PeopleSansPeople is a human-centric synthetic dataset creator using 3D models and standard animations to randomize human body poses. Also, we can use a Unity project template, to which we add our own 3D models and poses to create our own human synthetic dataset.
At Luxonis, we’re using this project as the basis for creating our own human synthetic dataset and training models. In general, we use Unity’s computer vision tools to create large and complex datasets with a high level of customization on labelers, annotations and randomizations. This allows our ML team to iterate faster with our customers, without needing to wait for real-world data collection and manual annotation.
What technological advancements are boosting computer vision adoption?
Since the introduction of transformer architecture, CV tasks are more accessible. Generative models like DALL-E 2 could also be used to create synthetic datasets, and NeRF as a neural approach to generate novel point of views of known objects and scenes. It’s clear all these innovations are catching the attention of audiences.


On the other hand, having access to better annotation tools and model zoos and libraries with pre-trained, ready-to-use models are helping drive wide adoption.
One key element contributing to the uptick in computer vision use is the fast evolution of vision processing units (VPUs) that currently allow users to perform model inferences on device (without the need for any host) at 4 TOPS of processing power (current Intel Movidius Myriad X). The new generation of VPUs promises a big leap in capabilities, allowing even more complex CV/AI applications to be deployed on edge.
Do any computer vision use cases surprise you?
Any application related to agriculture and farming always captures my attention. For example, there is now a cow tracking and monitoring CV/AI application using drones.


Our thanks to Gerard for sharing his perspective with us – keep up with his latest thoughts on LinkedIn and Twitter. And, learn more about how Unity can help your team generate synthetic data to improve computer vision model training with Unity Computer Vision.
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies