Build Engineering and Infrastructure: How Unity Does It





Hello! I'm Na'Tosha and I'm the Build and Infrastructure Developer here at Unity Technologies. While speaking with users at the awesome Unite 2011, I had several people ask me to write a blog post about how Unity Technologies manages to develop, build, and test Unity.
We do this with a combination of:
- Continuous Integration
- Automated Testing
- Code Hosting
- Code Reviews
- Manual Testing
I’ll talk about how we do the first four of those things here.
Continuous Integration
The Continuous Integration Server

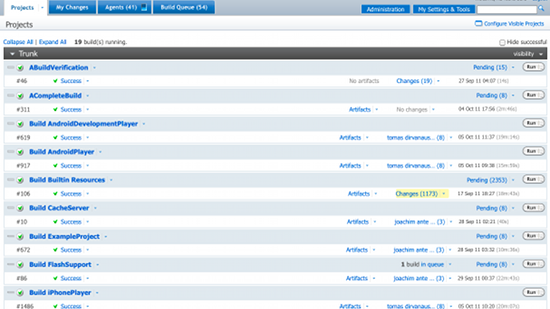
We use TeamCity from JetBrains as our continuous integration solution. One of the things we like best about TeamCity is that it has a very clear UI that gives the end user a good indication of the state of a project. For testsuites, it’s easy to see at a glance whether the suite passes or fails and what tests are failing. It can farm builds out to agents on Windows, OS X, and Linux, and keeps an extensive history of builds and tests, which are very useful when trying to figure out why a test is failing or whether there is something wrong with an agent. Generally speaking, we are quite happy with the feature-set and also with the support we’ve received from JetBrains.
Our only real complaint now is regarding the web UI -- it can still be slow to load at times (specifically, when loading a large project page that hasn’t been loaded for a while, or when opening the custom build run dialog when a lot of agents are attached). It can also be difficult regarding managing multiple branch projects, as there is currently no way to synchronize changes between branches that are copies of each other. However, the projects are stored in XML, and the schema is not complicated, so I have written a tool to do this instead by modifying the XML directly.
The Build Farm

Along with TeamCity, we have a build farm of approximately 45 machines, known as build agents. Most of these are virtual machines running Windows, Mac OS X, and Linux. We also have a few physical machines used for graphics tests, because testing graphics functionality requires a level of GPU manipulation that we could not achieve with virtual machines. Our virtual build agents are virtualized with VMWare Workstation on Linux hosts, using a combination of Apple and non-Apple hardware.
The reason for choosing virtual machines, despite the performance hit it gives us, is that virtualization allows us to easily maintain the system -- instead of updating 45 machines separately, we update the template virtual machine image for a given operating system, then copy it to the live buildservers. It also allows us to make every agent appear to be the same hardware-wise, even if they are running on different types of host hardware. This is important because as we add more build agents, they will be running on different generations of hardware, and for the purposes of testing, we need them to all appear the same.
Automated Testing

We have several automated test suites that we run on a regular basis. These are used, along with manual testing, as a metric for how stable our mainline codebase is, as well as when a feature branch is stable enough to be merged back into trunk. We currently have four types of test suites:
- Unit Tests -- these test the correctness of individual functions / small bits of functionality in the code, but they do not test high-level features of the product. These are used by developers, but not by our continuous integration server.
- Graphics Tests -- these work by building a Unity project that renders a set of static scenes. The project is then run on the target platform (desktop, console, or mobile), and screenshots of each scene are saved. We then compare the saved screenshots against a set of “known good” screenshots. If the difference is greater than a certain amount, we assert that the test has “failed”.
- Functional Tests -- these work by launching one instance of the editor or player, and testing various aspects of its functionality.
- Integration Tests -- these are the most high level tests. They work by launching an instance of the editor or player, testing a particular action or series of actions, and shutting down the editor or player and going on to the next test.
Our integration tests are executed by our continuous integration server as NUnit tests. TeamCity can run MSBuild projects directly, and we have a script that runs them with Mono’s Xbuild on Mac OS X. We developed our own framework for running the graphics tests.
We also have a regression rig that we developed ourselves. The regression rig, similar to the graphics tests, compares content played in Unity against previously recorded content, and checks for regressions. This is a good way to catch high-level regressions (for example audio having become bit-shifted).
Our test suites are always being expanded, and, along with our regression rig, they have helped us catch a number of regressions and bugs.
Code Hosting and Reviews
Like many software companies, Unity Technologies has run through a few different version control systems. In the beginning, there was no version control. Eventually the first Unity Ninjas began using CVS, and eventually Subversion. About a year ago, we started to investigate distributed version control systems and eventually settled on Mercurial. Now all of our source code is versioned in Mercurial, except for our public Mono, MonoDevelop, and Boo-related repositories on GitHub.
Why Mercurial?
Well, we had a few requirements. The first was that the version control system work with our continuous integration server, which is TeamCity, so we started off considering Git, Mercurial, and Bazaar, and Perforce. We also wanted something distributed because we have developers working in several different locations, and we also work on multiple platforms. A distributed system allows our developers around the globe to interact with the remote server less frequently, and it also allows all of us to easily test our changes on multiple local machines without having to share changes that potentially break some other platform with each other. We also wanted to be able to do feature development in branches and merge them back together successfully. So we were left with Git, Mercurial, and Bazaar. We spent some time evaluating these three systems. We were interested in:
- A simple, easy to use and understand command-line interface
- Good GUI tools for the system on OS X and Windows
- A good code review tool that works well with the system.
We also wanted a system that we felt had a lot of momentum -- an ecosystem that is growing and developing around it. After a few weeks of testing, we eventually decided on Mercurial because:
- It was substantially more simple to learn and use than Git
- It had good GUI tools for both Windows (TortoiseHg) and Mac (SourceTree, and now TortoiseHg)
- It had a couple of different options for large-scale code review tools
- It had a good-sized user-base (which is growing), a regular development cycle, and seemed to be well-adopted by both open-source and and commercial projects
Another very big win for Mercurial is that it was the only DVCS (at the time, at least) that had even attempted to handle the issue of large binaries in the repository. This was done through a few different publicly-available extensions to Mercurial. Distributed version control systems, by nature, don’t lend themselves well to codebases with a lot of large binaries, so we knew we would need some system that can cooperate with the version control system to store the large binaries outside of the repository, but still let us version them in some way. Not having to develop our own system completely from scratch was a really big win.
How to Host Mercurial and What to Use for Code Reviews?
After we decided on Mercurial, we needed to figure out how to host it and how we would review code. With this switch, we also wanted to implement a new development policy. Up until this point, we had always worked with just one central copy of the codebase, except for when we branched for release. This led to something almost always being broken, which had a serious effect on productivity. We wanted to be able to easily do feature development in branches; perform peer code reviews, build, and test verification on the branch; then merge it back into the mainline repository once it is complete. The goal is that trunk is always in a releasable, or nearly releasable, state.
[caption id="" align="aligncenter" width="550" caption="A Code Review in Kiln."]

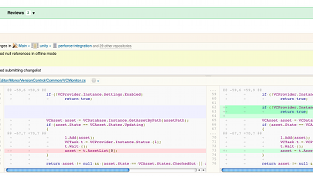
[/caption]
We looked at a few different code review systems, and eventually settled on Kiln from Fog Creek Software. Many people already know that we have used FogBugz as our issue tracking system for a while now. While FogBugz has some room for improvement (specifically, it doesn’t work very well as a public-facing bug tracker), it has done a pretty good job of serving our needs, and we have a really large amount of data in the system. At this point, we would need a pretty compelling reason to put in the effort to move all of that data to a new system. Kiln is a Mercurial code hosting system that interfaces with FogBugz and provides nice web-browsing of the repositories, code reviews on a per-changeset basis with one or more reviewers, and a server-side implementation of a Mercurial extension that handles large binaries. We have had some ups and downs with Kiln, mostly with regards to performance. Our repository size, which is about 1.6 GB with a clean working copy, and has several fairly large binaries, as well as our number of concurrent developers, about 65 and growing, and our build farm, another 45 or so machines, seem to have pushed it to its limits performance-wise. The self-hosted version of Kiln is currently not built with scalability to large teams (with large repositories) in mind, which results in very slow clones & pushes when there is heavy load. Hopefully, this will get resolved in the future. We’re not sure what our own future is with Kiln, but I will say that its feature set is quite nice, and it has allowed us to move to our desired development model of feature development in branches rather than in mainline. Beware that it is written in .NET and does not run on Mono, so if you want to consider Kiln, you will need to run a Windows server. I can say, however, that the Fog Creek support staff has spent countless hours trying to help us work through our various issues with Kiln.
Conclusion
Building and testing for so many platforms is a really difficult task -- especially as our development team is rapidly growing, and we find ourselves putting strains on infrastructure and processes in areas we didn’t expect. These tools and processes are fundamental to how the development team gets things done here at Unity.
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies