シミュレーション画像活用でコンピュータービジョンの性能が飛躍的に向上





コンピュータービジョンモデルが周囲の環境を正確に解析できるように学習させるためには、膨大なのデータが必要で、データを収集し、整備するためのリソースが不足する場面もあります。AI ソリューションを提供するニューラルポケットのゲスト記事では、同社がシミュレーションを活用してコンピュータービジョンモデルを構築した方法をご紹介いただきます。
東京に本社を置くニューラルポケットは、スマートシティに取り組む日本の大企業や地方公共団体向けに画像解析 AI を使った様々なサービスを提供しています。同社は急成長中のスタートアップとして常に最先端の技術を取り入れ、サービス開発に活かしています。
ニューラルポケットはシミュレーション画像を活用して学習データを整備し、AI の精度向上に活かしています。同社がシミュレーション画像の生成で使っているのが Unity コンピュータービジョンです。
Unity コンピュータービジョンには、開発者がスピーディーに多様な学習データセットを作り出すことを可能にする Perception Package が含まれています。実物のシミュレーション画像だけではなく、実際にない色や形などの要素を加えて作り出したシミュレーション画像を生成する(ランダム化)こともでき、多様な画像生成からコンピュータービジョンモデルの学習に合わせ、最適なラベル付けまでをパッケージの中で行えます。
この記事は、ニューラルポケットのシミュレーション部門の責任者である Romain Angénieux 氏と、同社のシニアエキスパートでテクノロジーインキュベーションチームの責任者である Alex Daniels 氏による、ニューラルポケット提供のゲスト記事です。本記事の残りの部分で、同社のシミュレーション画像を用いた取り組みについて解説します。ぜひご一読ください。
コンピュータービジョンでシミュレーション画像を使うべき理由
コンピュータービジョンは、画像や映像から解析したデータを基に、画像に何が含まれているのかを見つけ出す作業を行います。画像全体から単純な分類を行うだけでなく、人間の姿勢検出のように、画像内の特定の物体の位置をより詳細に検出する作業を行うこともあります。コンピュータービジョンモデルを学習させ、こうした作業ができるようにするには、膨大なデータ収集と、1つ1つの画像にタグを付けして分類し、学習データとして整備するアノテーション作業が必要で、多くの時間と費用がかかります。
実際の写真や映像を撮影して画像データを収集するのが一般的ですが、このやり方にはいくつかの欠点があります。
- 写真:ほしい最適な写真を撮影するのは、実は非常に難しいことです。例えば、季節ごとに違った気象条件を反映した画像を集めたいとした時、そのような写真を撮影するのは難しく、また、時間がかかります。
- 映像:現実世界での映像撮影には、プライバシーの課題があります。例えば、日本のほとんどの都市ではドローンを使った動画撮影は許可されていませんし、場所を決めて役者や機器を使って撮影をするためには、しっかりした計画と十分な費用が必要とされます。
データを収集した後は、コンピュータービジョンモデルに正確な認識をさせるために、何日もかけて手作業で画像のラベル付けを行う必要があります。このプロセスは、社内の貴重なリソースを使って行うか、追加の費用を支払って外部に委託することになります。
これらの課題を解決する方法の 1 つが、シミュレーションの活用です。この方法なら、アノテーション済みの大量の画像を短時間で生成することができます。光や対象物、素材、撮影環境などのパラメーターを変更して、よりよいデータセットを簡単かつ迅速に生成することができます。また、前述の外部要因の影響を受けないため、データセットの作成プロセスが大幅に合理化されます。
自作ソリューションの課題
ニューラルポケットは 2020 年 8 月から、自社で作成した Unity プロジェクトでシミュレーション画像の作成をはじめました。セキュリティ関連のサービスで使うために、動いている車両や人を認識して、追跡するコンピュータ―ビジョンモデルを学習させることが目的でした。
3 週間で、シミュレーション画像を生成するために必要な基本的な作業工程を作りあげました。具体的には、構図の中に対象物を配置する方法、背景や光などの環境に変化を加えた画像を生成する方法、データを記録し、画像をタグ付けして分類し、学習データとして整備する方法などです。
対象物の見える部分だけを切り出したピクセル単位の完璧なバウンディングボックスの設定や、対象物の配置場所が無数にある画像を使ったデータセット整備のためのオブジェクト配置アルゴリズムなどは、当初の想定以上に複雑であることがわかりました。私たちは少人数で、かつ、短期間で AI 開発を行うチームです。そのため、このような機能を備えたツールがあれば、よりプロジェクトに特化した開発に注力できるようになると考えました。
Unity コンピュータービジョンの導入
そうした経緯を経て、私たちは Unity コンピュータービジョンの Perception Package に出会いました。そして、パッケージを使い、物体検知 AI の学習を開始ししたところ、すぐに素晴らしい結果が出て、とても驚かされました。
コンピュータービジョンのモデルは、背景や光などの環境要因の変化に非常に敏感であるというドメイン依存性を持っています。ドメインランダム化と呼ばれる手法を用いて、合成した画像を背景や光などの環境要因を変化させることで、堅牢な学習を可能にするデータセットを生成することができます。Perception Package には、シナリオ、ランダマイザー、タグ、ラベル、スマートカメラなど、好みに合わせて設定できる機能を使うためのシンプルな UI が含まれています。これらはすべて、ドメインランダム化を実現してコンピュータービジョンの性能を向上させることを目的としています。このパッケージは、整理されたフローと構造を実現し、あらゆる検知システムプロジェクトで再利用できます。
パッケージには基本的なツールがすべて含まれているので、ほとんどの場合、カスタムランダム化(ユーザー独自のランダム化)を設計する必要がありません。そのため、Unity アセットストアなどのマーケットプレイスから 3D モデルを入手してドラッグアンドドロップで UI にまとめる作業に集中することができました。


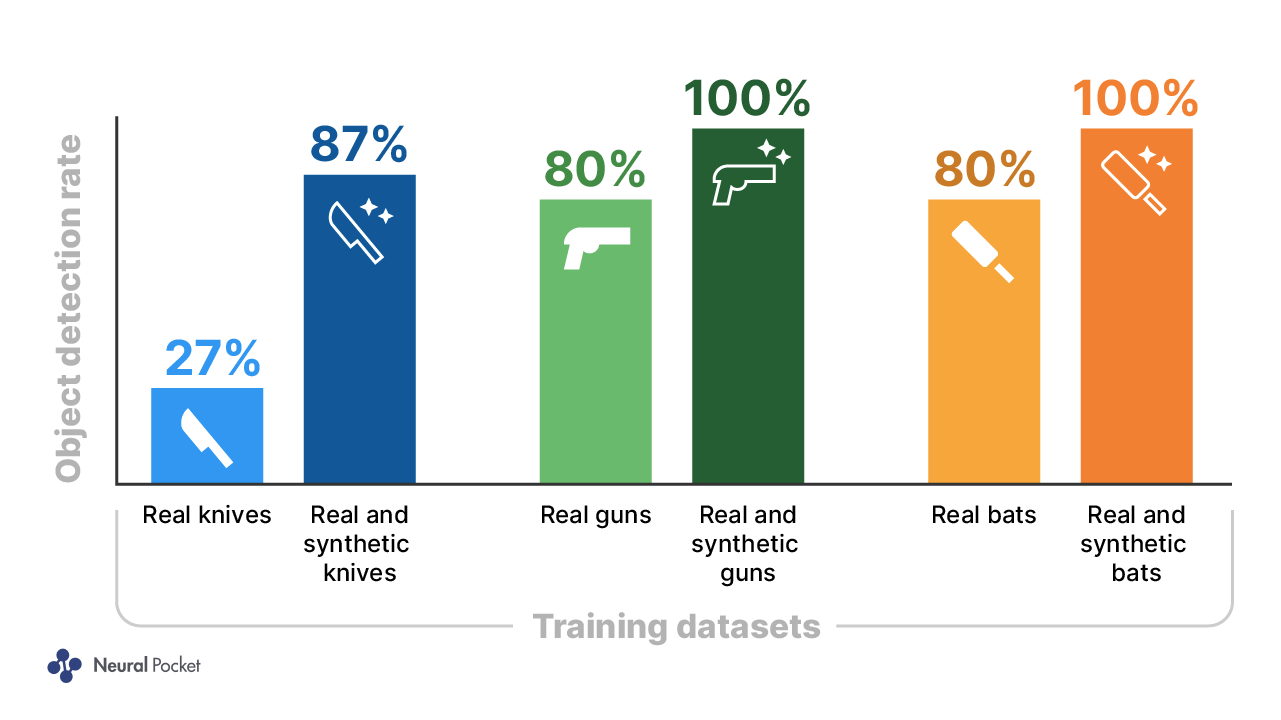
図 2 は、シミュレーションデータを使用した場合と使用しない場合の AI の性能を示しています。Perception Package のデフォルト設定で、3D モデルの追加以外の変更を加えていない場合、対象物によって異なりますが、検出率は 20 ポイントから 60 ポイント向上しています。

Perception Package の高度な使い方
Perception Package をデフォルト設定で使うだけでもコンピュータービジョンの性能は向上しますが、既存のツールに加えて作り込むことで、より広域のドメインをカバーすることができます。Perception Package はオープンソースなので、内部ロジックを変更することもできます。
スマートフォンを使って写真を撮影する人を検知するコンピュータービジョンの学習を進めるためにカスタムランダム化を使いました。これは、スマートフォンでパソコン画面などを撮影することで、クレジットカード番号などの機密情報が漏洩してしまうことを防ぐために開発したものです。スマートフォンを持った人を検知するのは以下の理由からとても困難な作業でした。
- 多様なモデルがある
- スマートフォンケースのデザインが無数にある
- スマートフォンを手で持つため、筐体の一部が指で隠れ、その隠れ方が全て違っている
- スマートフォンと間違われて検知される物体が多数存在する。
こうした課題を解決するために、私たちは様々なベース部品を論理的に組み合わせて、実際にありそうな「市場に出回っているスマートフォンを幅広く網羅するモデル」を生成する方法を設計しました。まず、既存のスマートフォンのロゴやカメラなど、目に見えるパーツをスマートフォン本体から切り離した 3D モデルを作成しました。そして、アンカーシステムを用いて、これらの部品をスマートフォンごとに入れ替え、新しい組み合わせを作り出していきました。
スマートフォンケースを検知するために、Google Images API からの画像をスマホケースにマッピングして、レンズやブランドロゴを隠さずに完全にフィットするようにテクスチャマッピングを行いました。
写真を撮るにはスマートフォンを手で持つ必要があります。そこで、どんな大きさのスマートフォンでもさまざまな姿勢で持つことができるモジュール化した手を作り、仕上げに肌のバリエーションを加えました。
最後に、コンピュータービジョンモデルがスマートフォン以外の多くの物体をスマートフォンとして誤検知する問題に対処するため、「スマートフォンに似た形やスタイルを持っているが、検出すべきではない物体」という、タグ付けされないトラップ(罠)となるような物体も作りしました。これにより、「捉えられた四角い物体がすべてスマートフォンとは限らない」という概念がモデルに組み込まれされました。このトラップ(罠)となる物体を学習データに加えたことで、AI で予測を行った時の誤検知数が大幅に減少しました。
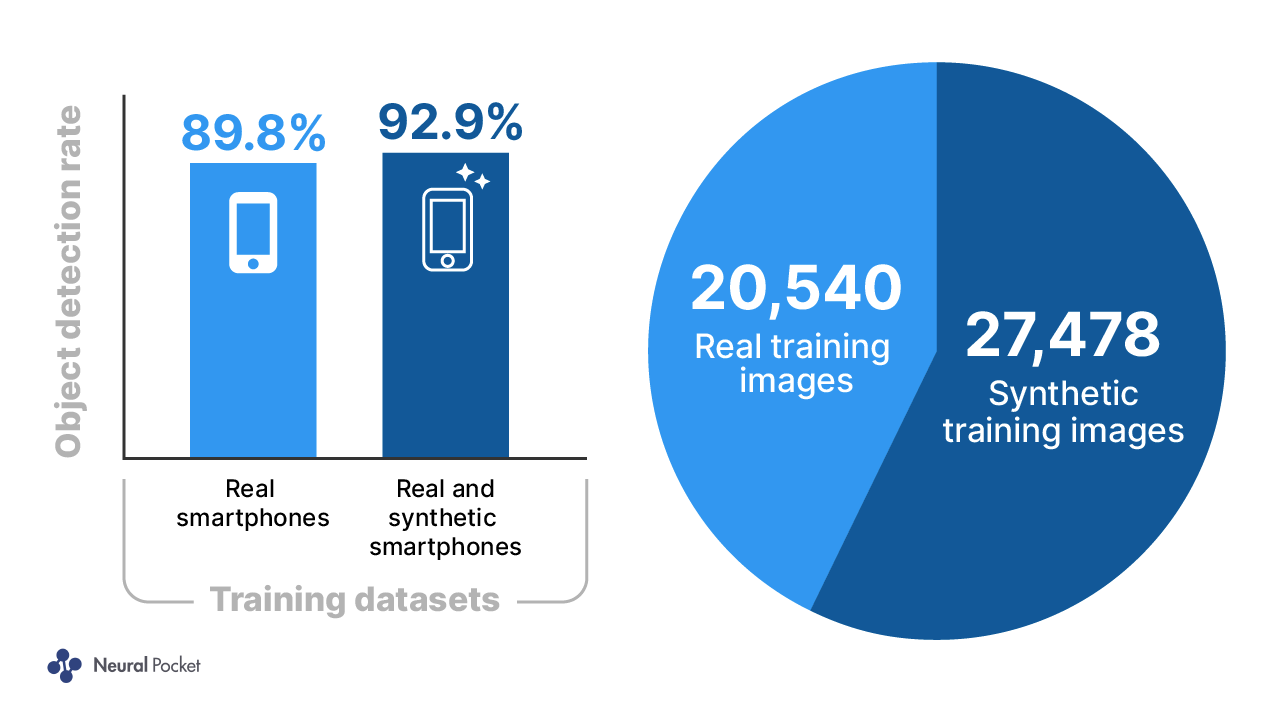
最新のイテレーションでは、シミュレーションデータを追加した後の精度の差は約 3 ポイントになりました(図 3 参照)。スマートフォンの検出プログラムは連続した動画フレームの上で実行されるため、静止画像で 3 ポイントの差が出ると、スマートフォンの検出率が全体として大きく向上することになります。





Unity コンピュータービジョンがビジネスに与えるインパクト
一般的に、実世界の画像を使ってモデルを学習させる場合、何度も繰り返し学習させる必要があり、その数は 30 回に及ぶこともあります。繰り返しのサイクルごとにデータの収集、アノテーション、学習、評価が必要で、1 サイクルあたり平均 1 週間程度かかり、プロジェクトによっては 2,000 ドルから 5,000 ドル程度の費用がかかります。30 サイクル行う場合は、費用は 60,000 ドルから 150,000 ドルという莫大な額になります。また、製品に使えるモデルを作るのには 4 か月から 6 か月かかります。
これに対して、Perception Package を使って作成したシミュレーションデータと実際の画像データを使った学習を 1 サイクル(5,000 ドル)にとどめた場合、1 週間程度でより優れたモデルを作り上げることができました。追加費用は 1,750 ドルで、時間と費用の両方を約 95% カットすることができました。


Perception Package が提供するデータのバリエーションが増えたことで、実際の画像データを収集する必要性は軽減されています。また、コンピュータービジョンモデルの性能も向上し、より高品質な製品を提供できるようになりました。これは社内だけでなく、私たちのパートナー企業のメリットにつながります。
シミュレーション活用でコストが削減できたことで、プロジェクトやソフトウェアの商用化を決定する場面で、シミュレーションの利点を考慮できるようになりました。つまり、同時に引き受けられるプロジェクトの数を増やすことができるため、コスト削減だけでなく、売上の増加も見込めるようになりました。
広がる活用場面
Unity コンピュータービジョンの Perception Package には、私たちが使い始めて以来、定期的にアップデートされ、多様なランダム化をサポートする新機能が追加され、より直感的な UI やデータ記録の自由度の向上などが図られてきました。最近のバージョンアップで、Perception Package はバウンディングボックス、人間のポーズ推定データ、その他、カスタムの 3D ポイントデータを保存できるようになりました。
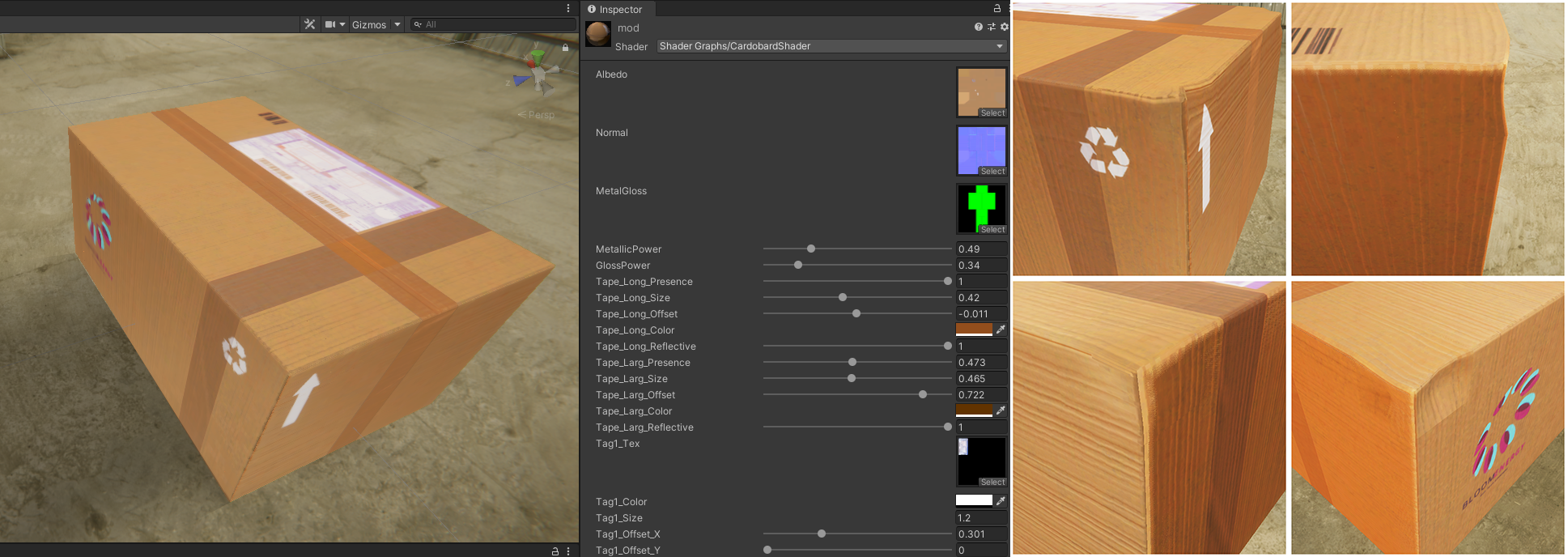
ニューラルポケットのプロジェクトの中で、性能向上による恩恵を最も受けているものの 1 つが、スマート工場向けに開発している段ボール箱の分析を行うコンピュータービジョンモデルです。シミュレーションでは、段ボールがへこんでいたり、破損していたり、表面にラベルが貼られていたり、ロゴが印刷されていたりといった状態を作り出す必要があります。
このプロジェクトでは、複雑なシェーダー開発に時間をかけて、物体のあらゆる要素をランダム化しましたが、これまでの経験から、パッケージの組み込みは、素早く簡単に行えることが分かっていたので、まったく心配していませんでした。

ユーザーのニーズに焦点を当てた積極的な開発により、Unity コンピュータービジョンの Perception Package がこれからも継続的に改良され、やがて認識タスクの基準となり、私たちが検知プロジェクトを始める時の出発点として使える存在となることを願っています。
***
このゲスト記事にご協力いただいたニューラルポットの Romain さんと Alex さんに感謝申し上げます。さらに詳細をご覧になりたい方は、以下のリソースをご覧ください。
- ニューラルポケットが Unity を活用して挙げた成果については、こちらのケーススタディ(英語)をご覧ください。
- Unity コンピュータービジョンの詳細はこちらでご覧ください。また、Perception Package は無料でお試しいただけます。合成データセットを作成したいのに、Unity 開発者がチームにいなくてお困りの方は、ぜひお問い合わせください。
- メーリングリストにぜひご登録ください。コンピュータービジョンに関する幅広い分野の最新情報をお届けいたします。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies