Imitation Learning in Unity: The workflow







With the release of ML-Agents toolkit v0.3 Beta, there are lots of new ways to use Machine Learning in your projects. Whether you’re working on games, simulations, academic or any other sort of projects, your work can benefit from the use of neural networks in the virtual environment.
If you’ve been using ML-Agents tooklkit before this latest release, you will already be familiar with Reinforcement Learning. If not, I wrote a beginner’s guide to get you started. This blog post will help you get up to speed with one of the major features that represent an alternative to Reinforcement Learning: Imitation Learning.
Before we start
As opposed to Reinforcement Learning, which works with a reward/punishment mechanism, Imitation Learning uses a system based on the interaction between a Teacher agent (performing the task) and a Student agent (imitating the teacher). This is very useful in situations where you don't want your AI to have machine-like perfection, but want it to behave like a real person instead. We’ve shared the example that we will look at here at this year’s Unity at GDC Keynote.
What is good about using Machine Learning Agents toolkit rather than scripting a behavior is that they are adaptable and require almost no AI development knowledge.
If you’re using this post as a reference and you’re starting from a project that uses ML-Agents toolkit v0.1 or v0.2, make sure you’re aware of the changes in the semantics and that you align with v0.3. If you need help with setting up ML-Agents toolkit into a Unity environment, check out the ML-Agents Docs.
The Task
This example is based on the Hover Racer project developed by Unity using the assets from the game Antigraviator from Cybernetic Walrus. We will look at the same scene that you’ve seen at GDC, and understand how it works.

The task is to automate the movement of the opponent’s vehicle so that it’s fun for the player to race against it. The car, in this case, is the Agent. Since the AI cannot see, in the traditional sense, it needs a way to simulate vision to understand how the human is making their decisions. Therefore, both vehicles send out a series of raycasts around it to "see" where the walls are. In this way, the machine can see that the human is avoiding the walls so that it can begin to imitate the behavior. Of course, the human could always intentionally drive into walls or try to crash into other players in order to create an AI that wants to do that same, that's all a part of the fun!
The Training Prep
Now that the task is clear, we can start preparing for training. Top tip: have your task clear in mind (and practice) before you start training - it will save you a headache later on. You will be teaching the task to a student agent, and you cannot teach what you don’t know yourself!
First, understand Observations and Actions. The former are the pieces of information that the agent needs to be trained properly. In our case, the agent has to know whether there is an obstacle around to avoid it. We will add this information in the CollectObservations() method. Raycast() is a simple method in the custom class ShipRaycaster that casts rays around the agent and returns the value of the distance from the wall with which the rays overlap, -1 otherwise. We pass the value of the distance from any wall it hits or a value of -1 if it hits nothing. Generally speaking, we should pass observations as normalized values from 0 to 1, so we need a way to tell the brain both how far the wall is, and whether or not the raycaster hit a wall at all. Therefore we will use two points of data for each raycast. For example, if our raycast distance was 20 units and a wall was hit 10 units away, we'd pass in the values .5f (half the distance) and 1f (yes, it hit). If the same ray didn't hit any walls, we'd pass in 1f (max distance) and 0f (no, it didn't hit).
We also want to record the localVelocity and the Y value of localAngularVelocity for the neural network to be aware of.
//Agent collecting the results of its actions
public override void CollectObservations()
{
//Ask each raycaster if it sees a wall
foreach (ShipRaycaster ray in rays)
{
float result = ray.Raycast();
if (result != -1)
{
AddVectorObs(result);
AddVectorObs(1f);
}
else
{
AddVectorObs(1f);
AddVectorObs(0f);
}
}
Vector3 localVelocity = transform.InverseTransformVector(rigidBody.velocity);
Vector3 localAngularVelocity = transform.InverseTransformVector(rigidBody.angularVelocity);
AddVectorObs(localVelocity.x);
AddVectorObs(localVelocity.y);
AddVectorObs(localVelocity.z);
AddVectorObs(localAngularVelocity.y);
}Now we communicate this information to the Brain Inspector Window. At this stage, the Brain needs to know how many observations we’re collecting and whether they’re Discrete or Continuous. In this case, we collect 20 observations as the rays array contains 8 raycasts, which is 16 total observations (since we add 2 for each ray). We add 4 additional observations for localVelocity (X, Y and Z axes), and localAngularVelocity (Y axis).


The Actions are the actions that the agent can perform during both training and testing (Play mode). They can be either Discrete or Continuous. In this case, there is only one Continuous action: steering. This can have a negative (steer left) or positive (steer right) value. We can script this in the AgentAction() method. Additionally, we can include a small reward that works as a visual feedback for the human trainer. The reward does not affect the training, but it will notify the trainer that the Agent is actually learning (as it outputs to the console during training).
//Agent making a decision
public override void AgentAction(float[] act, string txt)
{
movement.input.rudder = Mathf.Clamp(act[0], -1, 1);
AddReward(.1f);
}Again, we transfer this information to the Brain Inspector Window.

What your agent knows and what it can do needs to be clear from the beginning. Scripting your Agent class and filling in the variables of your Brain component go hand in hand here.
Before leaving the scripting side of our Agent, we want to make sure that the simulation gets restarted when the vehicle hits an obstacle. To do this, we check for collision with a wall. When Done() is called, the AgentReset() method takes care of resetting the agent so that it can start learning again. This means moving the vehicle back to the closest waypoint and clearing out any velocities it might have.
//Agent has collided with the wall and needs to be restarted on the track
public override void AgentReset()
{
transform.position = spawnPosition;
transform.rotation = spawnRotation;
rigidBody.velocity = Vector3.zero;
rigidBody.angularVelocity = Vector3.zero;
}Teacher and Student Agents
We want to train a Student racer to play like a Teacher racer. Therefore, we need to implement a Student Brain and a Teacher Brain to associate with the two agents, respectively. We can simply duplicate the Brain that is currently in the scene, as the variables in the Inspector have to be the same for both. At this stage, it’s important to give relevant names to the Game Objects to which the Brains are attached, as this will matter later. “StudentBrain” and “TeacherBrain” are adequate names.
 | 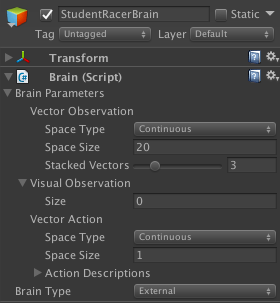 |
The Teacher Brain Type is “Player”, as it uses the inputs coming from the Player. Here, we set up the steer inputs as per defined in the logic of the game. In this case, A is steer left (value -1), and D is steer right (value 1). The “Broadcasting” checkbox will ensure that the actions performed by the player are visible to the Student brain so that it can learn to imitate.
The Student Brain is the one that will receive the training. Its Type will be “External“, which means that its behavior will be decided by the AI brain while we are playing.
We can customize the training configuration (hyperparameters) by editing the trainer_config.yaml file in the python folder or we can choose to use the default values. When training starts, the configuration for each brain is found by name in this file. That is why it’s important to pay attention to the Brain's Game Object name in the editor. This is what the StudentBrain in the trainer_config.yaml file looks like:
StudentBrain: trainer: imitation max_steps: 10000 summary_freq: 1000 brain_to_imitate: TeacherBrain batch_size: 16 batches_per_epoch: 5 num_layers: 4 hidden_units: 64 use_recurrent: false sequence_length: 16 buffer_size: 128
The Training Process
The next step is to launch the training and start teaching your agent. First, build your Unity executable into the python folder. Then, from your terminal window, navigate to the python folder and run python3 learn.py <env_name> --train --slow, where <env_name> is the name of your Unity executable. A window will pop up and will allow you to play as the Teacher Agent. Keep training until your Student Agent seems to have understood how to perform the task by itself (for this task or any of a similar difficulty, ~4-5 minutes should be enough).
Once the training is completed, press CTRL+C to stop the simulation. The program outputs a .bytes file that contains the trained model: the action to perform given an observation. We import back this file into the editor by changing the Student Brain Type to "Internal". At the end, the agent should act like at minute 0:32 of this video.
To sum up
There is a lot going on in the world of Machine Learning at the moment, and Unity is working hard on empowering developers to leverage it fast and easy! Hopefully, this post provided some insightful tips to get started with your own projects or to begin to understand what is possible in the world of Machine Learning in Unity.
I would absolutely love to see what you’re working on, so if you found this useful please let me know by leaving a comment, and make sure to check-out the Machine Learning portal.
Going to Unite Berlin? Don’t miss sessions on Machine Learning!
Get an intro on our toolkit from “Democratize Machine Learning: ML-Agents Toolkit Explained” by Vincent-Pierre Berges (day 3, breakout 3). Vincent-Pierre is also hosting a Hands-On Lab on Machine Learning (day 3, breakout 2). If you’re working on marketing your game, you should also check out a talk titled “Maximize user acquisition spend with immersive ad formats and machine learning” by Juho Metsovuori (day 2, breakout 4).
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies