优化移动端游戏性能:图形和资源相关的专家级建议







Unity的Integrated Success团队以帮助Unity客户解决复杂技术问题为己任。本次,我们请到了这支高级软件工程师团队来与大家分享一些移动端游戏优化方面的专业知识。
而Accelerate Solutions团队对引擎的源代码了如指掌,并与大量的Unity客户有过合作,帮助他们最大限度地利用引擎。团队的日常工作包括深入剖析客户项目,搜寻其在速度、稳定性与效率方面有待优化的部分。 他们分享了非常多的锦囊妙计,以至于一篇博文很难涵盖所有内容。因此,我们决定将这些堆积如山的知识编篡成一本完整的电子书(可在此处下载),并推出一个博文系列,重点介绍其中75个可操作性强的技巧。
在系列的最后一篇博文中,我们将着重介绍怎样提高资源、项目配置和图形的性能。本系列共有三篇,另外两篇分别介绍了性能分析、内存和代码架构的优化,及物理模拟、UI和音频的优化,请阅读全部内容来了解完整的游戏优化方法,或者在Unity中文课堂获取免费移动游戏优化课程来详细了解每个优化主题。
项目配置
有几个特定的项目设置会影响移动端游戏的性能。
降低或禁用Accelerometer Frequency(加速度计频率)
Unity每秒钟会以一定次数统计移动设备的加速度计状态。如果应用并不会用到加速度计,我们完全可以禁用该功能或降低统计频率来获得更好的性能。


禁用不必要的Player或Quality设置
如果目标平台并不支持Auto Graphics API,最好禁用Player设置中的相应选项,防止驱动程序生成多余的着色器变体。如果应用不支持老式CPU,请禁用Target Architectures 。
禁用Quality设置里多余的质量等级。
禁用不必要的物理模拟
如果游戏并不会用到物理模拟,请取消勾选Auto Simulation和Auto Sync Transforms。这两个选项在物理模拟之外并没有过多的用处,因此只会减缓应用的运行。
选择正确的帧率
移动端项目必须小心在帧率与电池寿命、过热保护间找到平衡。有时与其用60帧挑战设备的极限,用30帧平稳运行是一种更好的选择,Unity默认会将移动端应用的帧率设为30fps。
你也可以在运行时调用Application.targetFrameRate动态地调整帧率,比如,在相对较慢或静止的场景中将帧数降到30帧以下,在游戏进行中保留高帧数。
消除庞杂的对象层级
把对象层级拆开。如果某个GameObjects不需要嵌到层级里,我们可以简化对象的从属关系。更精简的对象层级可以很好地利用多线程处理来刷新对象的Transform,而复杂的层级结构会导致多余的Transform计算和更高的垃圾数据回收成本。
关于Transform的最佳设置方法,请在Optimizing the Hierarchy和这段Unite演讲中详细了解。
尽量一次完成对象变换
在移动Transform时,请调用Transform.SetPositionAndRotation一次性完成对象的移动和旋转,这样做可避免两次修改同一变换,节省运算开销。
如果你需要在运行时实例化一个GameObject,则可以在实例化之际嵌入并移动对象,来达到优化的目的:
GameObject.Instantiate(prefab, parent);
GameObject.Instantiate(prefab, parent, position, rotation);
关于Object.Instantiate的更多细节,请参见Scripting API。
Vsync 在移动平台上默认启用
大部分移动端设备并不会将图像帧一分为二进行渲染。但即便我们在编辑器选项中禁用Vsync(Project Settings > Quality),Vsync功能仍会在硬件层面上启用。因为如果GPU频率不够高,帧将被滞留直到渲染完成,导致帧数降低。
资源优化
资源管线会极大地影响应用的性能。因此,我们最好请一名经验丰富的技术美术来协助制定和实施资源的格式、规格和导入设置,让流程尽可能流畅。
请不要完全依赖默认设置,使用具体平台的重写组件来优化纹理、网格几何形等资源。错误的资源设置可能会导致游戏文件过大、构建时间过长,甚至造成不合理的内存占用。请灵活使用Presets(预设)功能来制定适合项目的设置基准。
更多详情请参阅这份美术资源最佳使用指南,或在Unity Learn上学习3D Art Optimization for Mobile Applications教程。
找到正确的纹理导入方式
一款应用的大部分内存占用一般是用在了纹理上,因此纹理的导入设置非常关键。通常来说,纹理的导入应遵守如下原则:
- 降低最大分辨率:在肉眼不易察觉、尽量不破坏原图的前提下使用较低的分辨率,从而达到优化内存占用的目的。
- 采用二次幂(power of two,POT)压缩格式:Unity要求移动端的纹理压缩格式(PVRCT或ETC)采用二次幂的纹理尺寸。
- 制作纹理图集(texture atlas):将多张纹理合并到一张纹理图集中可以减少绘制调用次数,加快渲染速度。纹理图集可使用Unity Sprite Atlas或第三方的TexturePacker 进行制作。
- 取消勾选Read/Write Enabled:该选项在启用时会分别在CPU和GPU可寻址内存中创建一个副本,让纹理的内存占用翻倍。该选项在大多数情况下都可禁用。如果纹理是在运行时生成的,则可通过调用Texture2D.Apply,将makeNoLongerReadable设为true来强制禁用选项。
- 禁用多余的Mip Map:Mip Map贴图在2D精灵和UI图形这类大小始终一致的纹理上并无用处,但在随镜头距离变化而变化的3D模型上需要保留。

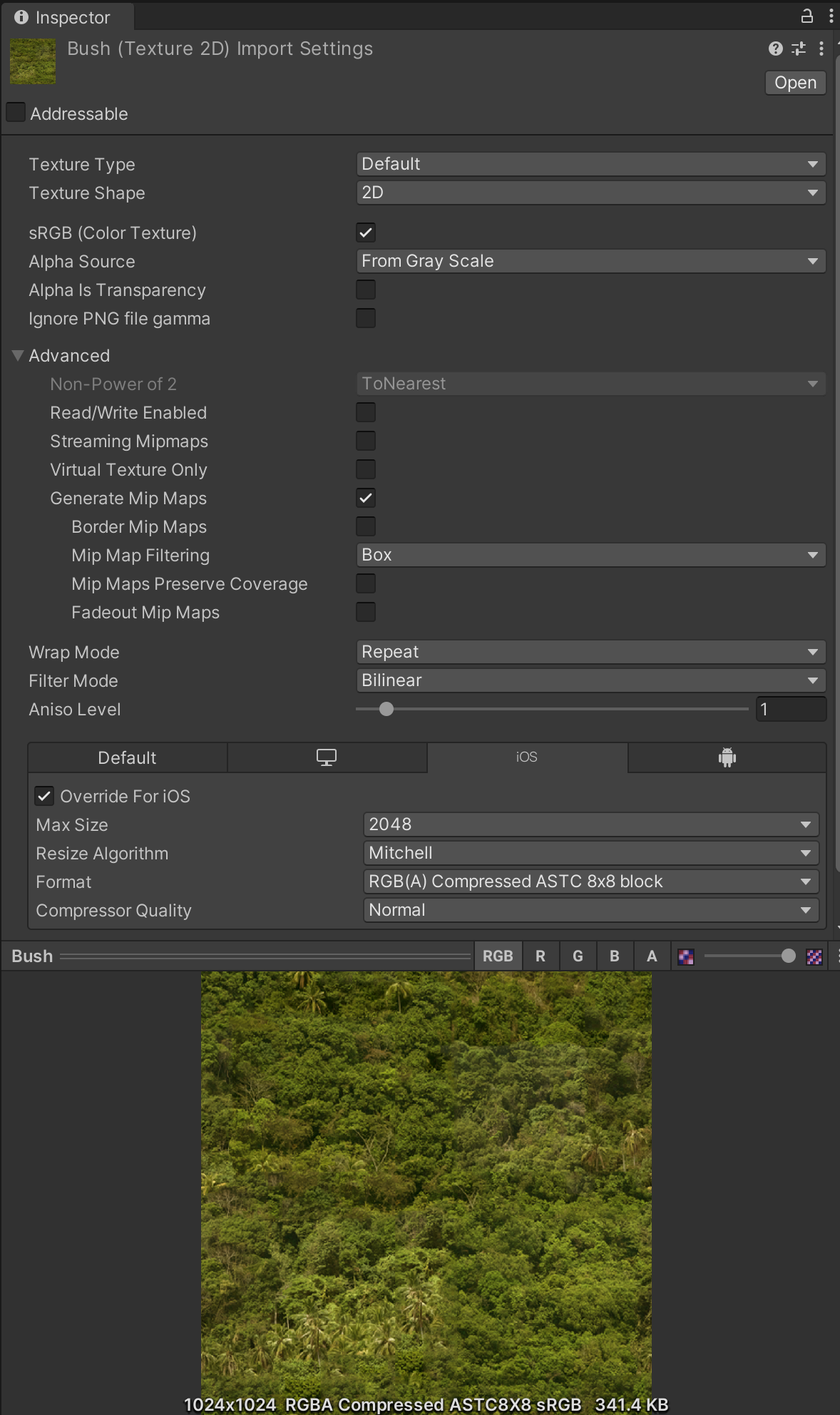
压缩纹理
我们来对比一下两个模型和纹理相同的例子:左图所占用的内存几乎是右图的八倍,但在视觉上却没有什么不同。

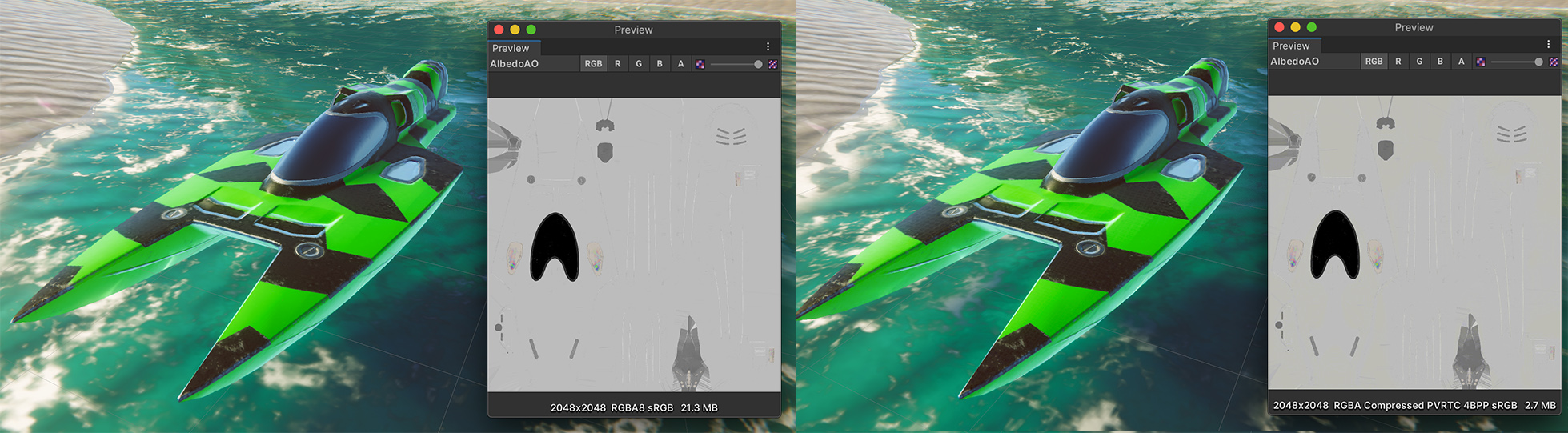
因此,请为iOS和Android应用采用自适应可伸缩纹理压缩(ATSC)格式。大多数游戏在开发时都以支持ATSC压缩、配置最低的设备作为目标设备。
当然也有例外,包括:
- 运行于A7及更老的芯片上的iOS游戏(即iPhone 5、5S等)——请使用PVRTC格式
- 运行于2016年以前的安卓设备的安卓游戏——请使用 ETC2 (爱立信的纹理压缩格式)
如果PVRTC和ETC等压缩格式的质量不够理想,或者目标设备不完全支持ASTC格式,我们可以试着将32位纹理替换成16位纹理。
请在完整版手册中详细了解各平台推荐的纹理压缩格式。
调整网格导入设置
类似于纹理,网格模型如果导入不当,也会占用过多的内存。要想尽量减少网格模型的内存占用,我们可以:
- 压缩网格,采用激进的压缩方法来减少磁盘空间占用(运行时的占用不会受影响)。注意,量化模型可能会导致模型失真,请根据实际情况来选择合适的压缩等级。
- 禁用Read/Write,该选项会分别在运行内存和GPU内存中创建模型的副本,它在大多数情况下都应禁用(Unity 2019.2及更早的版本会默认启用)。
- 禁用动画骨架和BlendShapes,若网格模型不带有骨骼动画或BlendShapes动画,则这两个选项并无多大用处。
- 禁用法线和切线贴图,若网格模型的材质并没有法线或切线贴图,则我们能禁用这两个选项来节省性能开支。

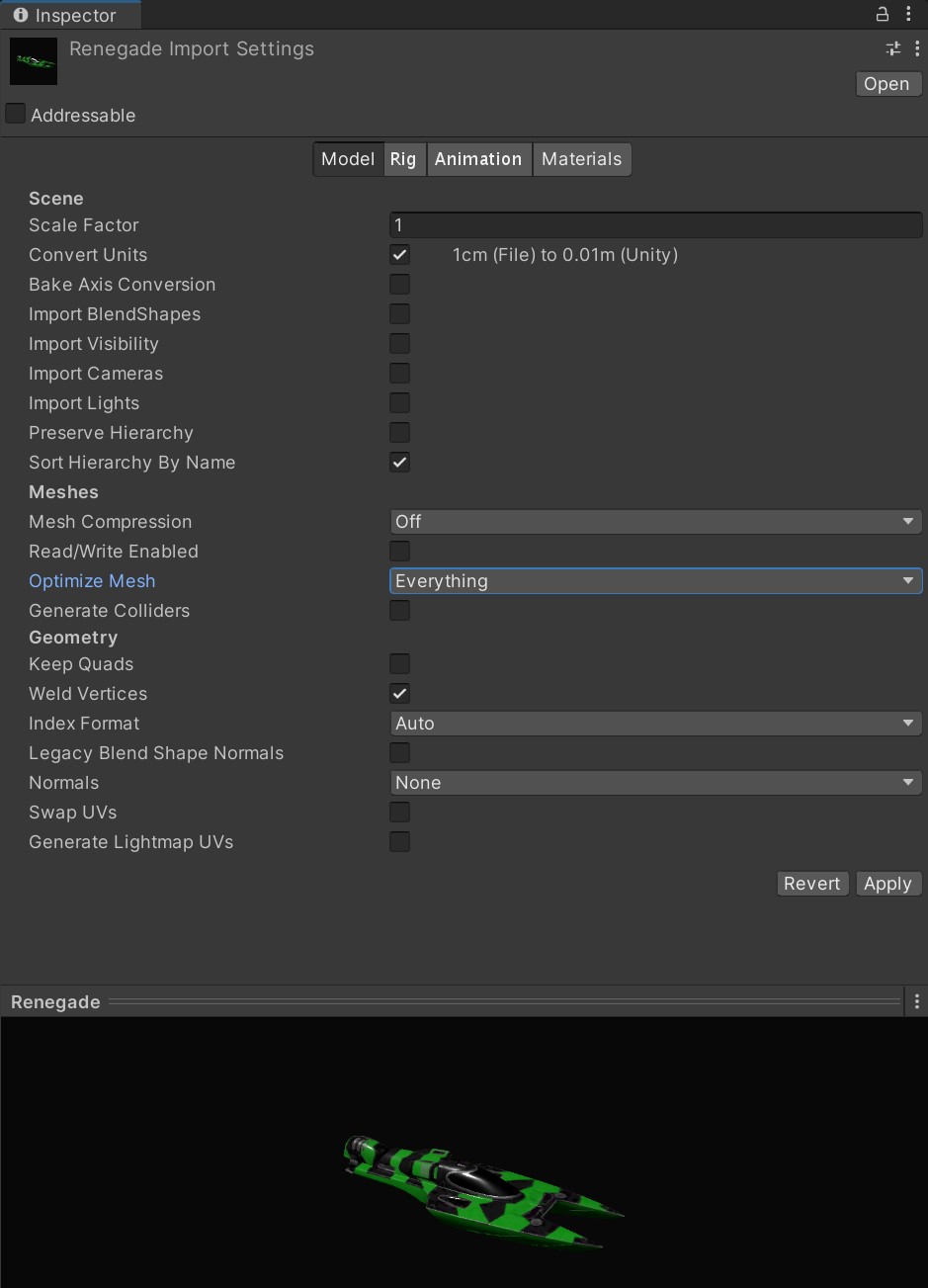
检查模型多边形面数
一个模型如果有更高的分辨率就意味着更多的内存占用和更长的GPU处理时间。通常来说,游戏的背景并不需要数十万的面,并且许多DCC软件导出的模型也可做一定的精简。举例来说,处于摄影机拍摄角之外的多边形可被删去,模型的细节可使用纹理和法线贴图呈现,不必使用过于复杂的网格来保留细节。
借助AssetPostprocessor自动设定导入设置
AssetPostprocessor功能支持在导入资源时运行脚本,如此一来我们便能在模型、纹理、音频等资源的导入前/后应用自定义设置。
使用Addressable Asset System(可寻址资源系统)
Addressable Asset System可以一种更为简单的方式来管理内容。系统采用统一的处理方式,通过调用AssetBundle的“地址”或别称,从本地路径或远程的内容分发网络(CDN)异步完成资源的加载。


如果把脚本以外的资源(模型、纹理、预制件、音频,甚至整个场景)划分成一个个AssetBundle,就可以将其作为可下载内容(DLC)分开分发。
然后,使用Addressables创建一个最小的应用程序,Cloud Content Delivery将在游戏进行中完成游戏内容的管理和分发。

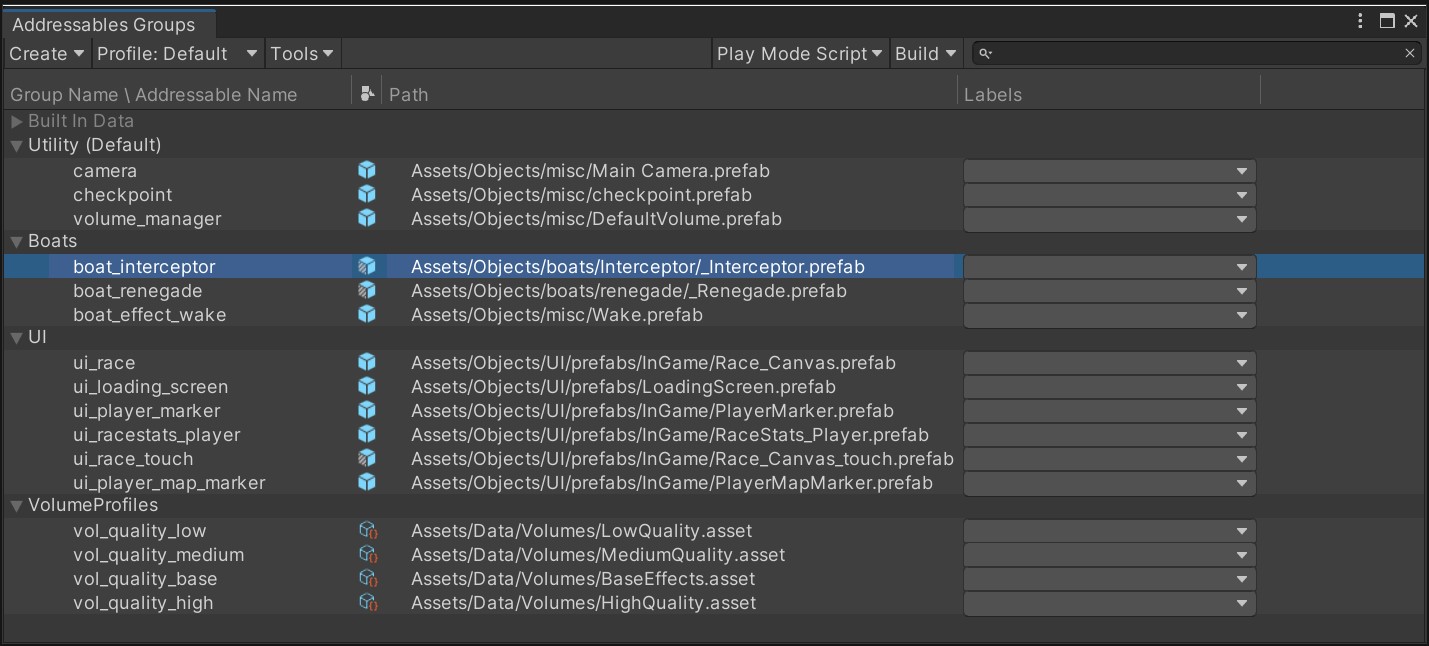
点击此处来详细了解Addressable Asset System是怎样让资源管理更为轻松的。
图形和GPU优化
Unity会在每一帧上搜寻必须渲染的对象,然后再发起绘制调用。绘制调用是指调用图形API来绘制对象(如一个三角形),而批处理是一组同时运行的绘制调用。
随着项目变得愈发复杂,我们需要制定一定的渲染管线来减轻GPU的工作负荷。目前, 通用渲染管线(Universal Render Pipeline,URP) 使用单程(single-pass)前向渲染为移动设备生成高质量图形(延迟渲染将在未来添加)。在游戏主机与PC上常见的物理性光照和材质在经过一定调整后也可以用于手机或平板。
请遵循下方指南来优化图形的绘制速度。
绘制调用批处理
将所有需要绘制的对象分批处理可以最大限度地减少因为绘制单个对象所产生的场景变化,这样做可以降低渲染物体的CPU开销,能切实提高性能。Unity有几种方法将多个对象合并成批:
- 动态批处理(dynamic batching):对于较小的模型网格,Unity可以在CPU上对顶点进行分组和变换,然后一次性画完它们。注意:该方法仅适用于模型带有大量的低多边网格(即少于900个顶点属性及300个顶点)时。Dynamic Batcher不会处理更大的网格,程序在启用时会在每一帧上搜寻符合标准的网格,占用一定的CPU运行时。
- 静态批处理(static batching):对于静态的几何体,Unity可以减少绘制那些材质相同的网格。该方法比动态批处理更有效,但也会使用更多的内存。
- GPU实例化:若场景中存在大量相同的对象,我们可以采用这种方法利用起显卡的算力,更高效地完成对象的绘制。
- SRP批处理:SRP Batcher可在通用渲染管线配置资源的Advanced选项下启用。该功能在特定场景下可大大加快CPU的渲染时间。

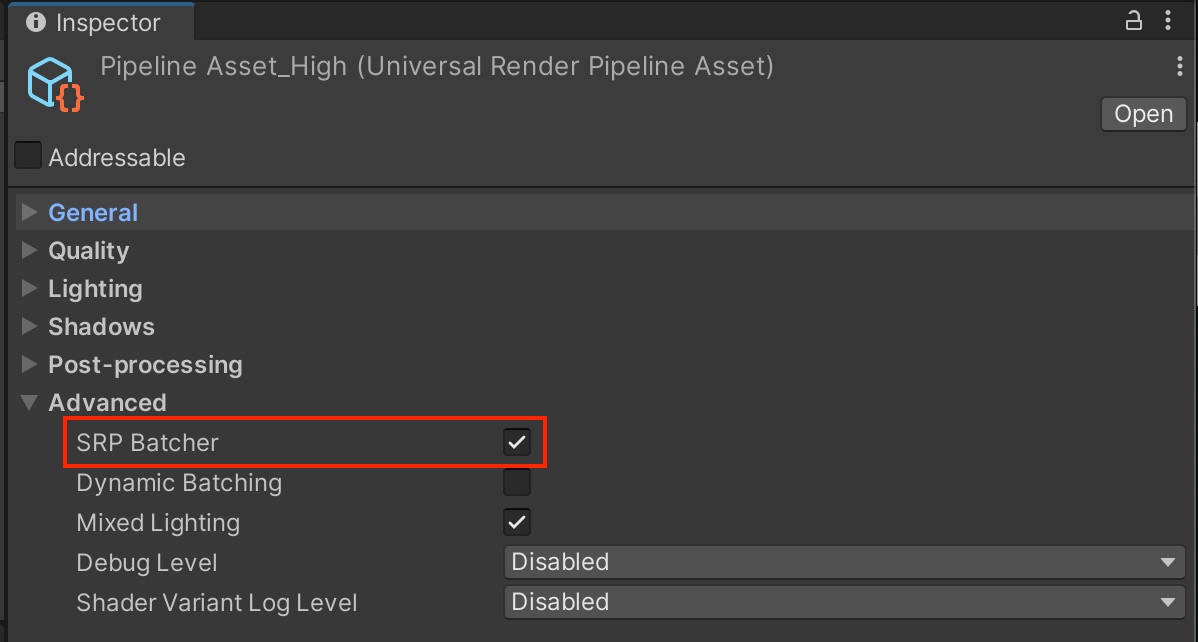
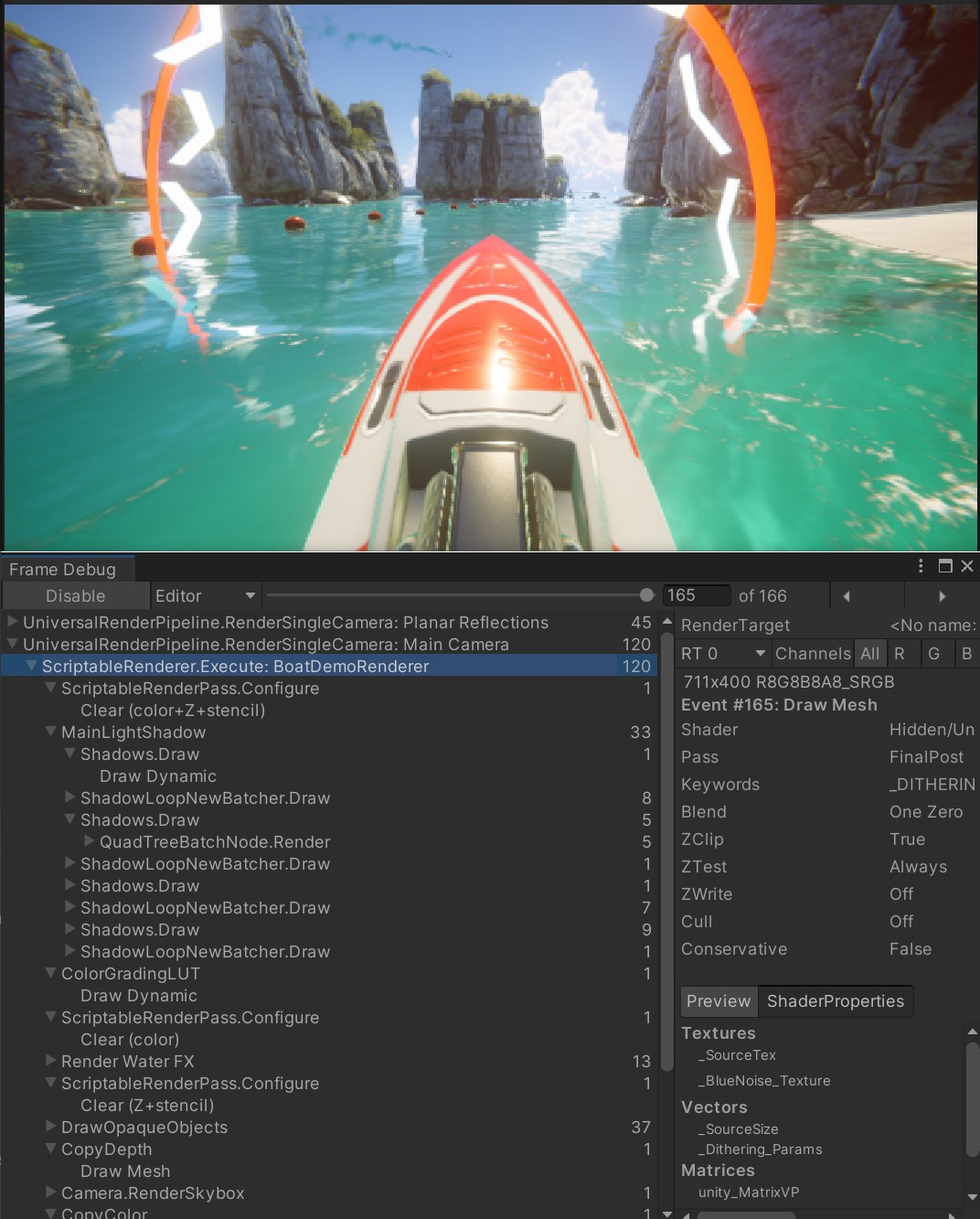
善用Frame Debugger(帧调试器)
Frame Debugger可显示每一帧的绘制调用组成。它可以帮助你分析游戏的渲染过程,是检查着色器的宝贵工具。


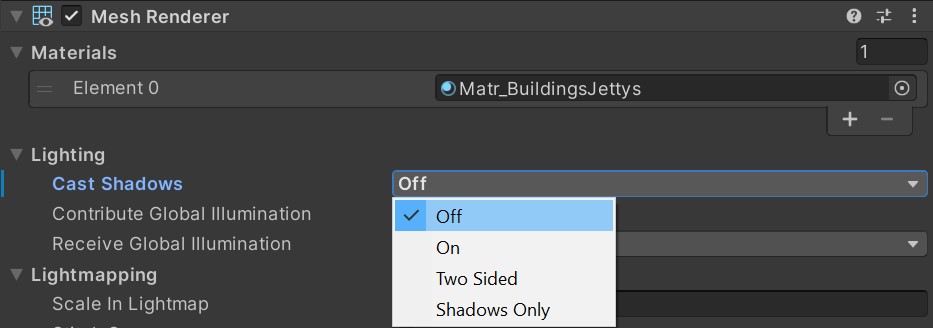
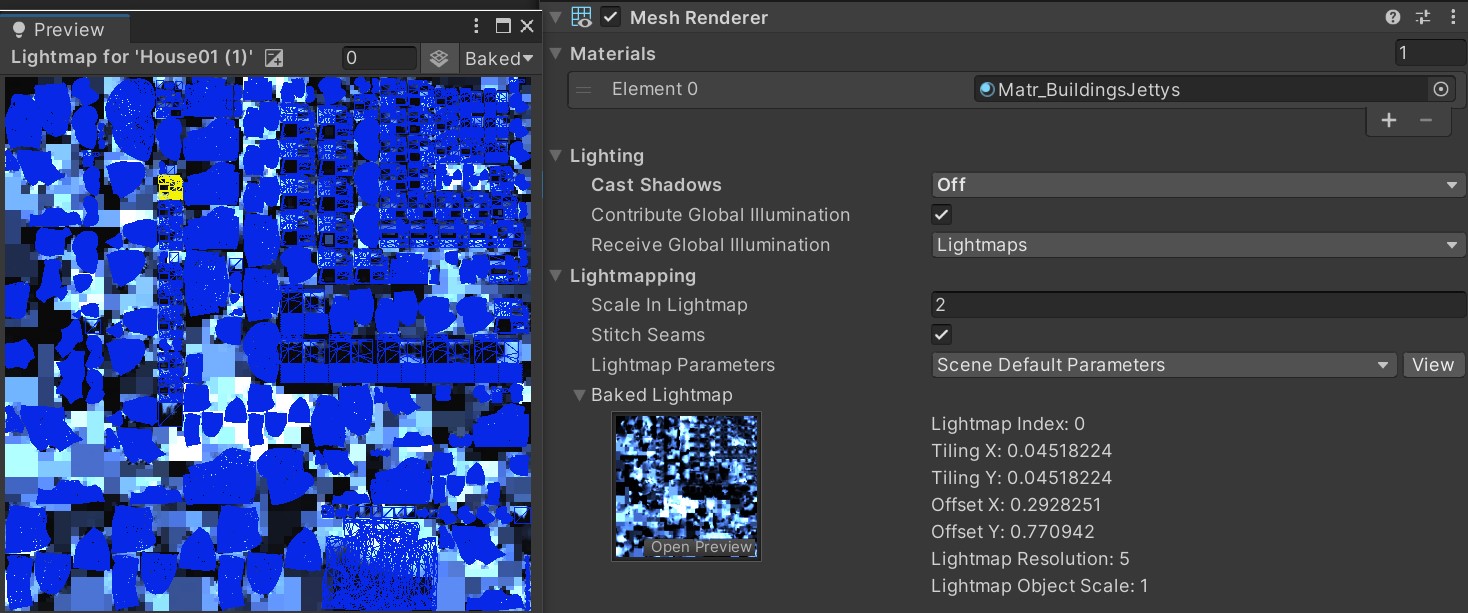
烘焙光照贴图
全局光照(GI)投射到静态几何形上产生戏剧性灯光效果。如果为对象勾选Contribute GI选项,所有的光照信息便能以光照贴图的形式存储起来。

启用Contribute GI。
光照贴图将由引擎进行烘焙,而这些阴影和光照的渲染不会对运行时的性能产生显著的影响。Progressive CPU及GPU Lightmapper更是可以加快全局光照的烘焙。


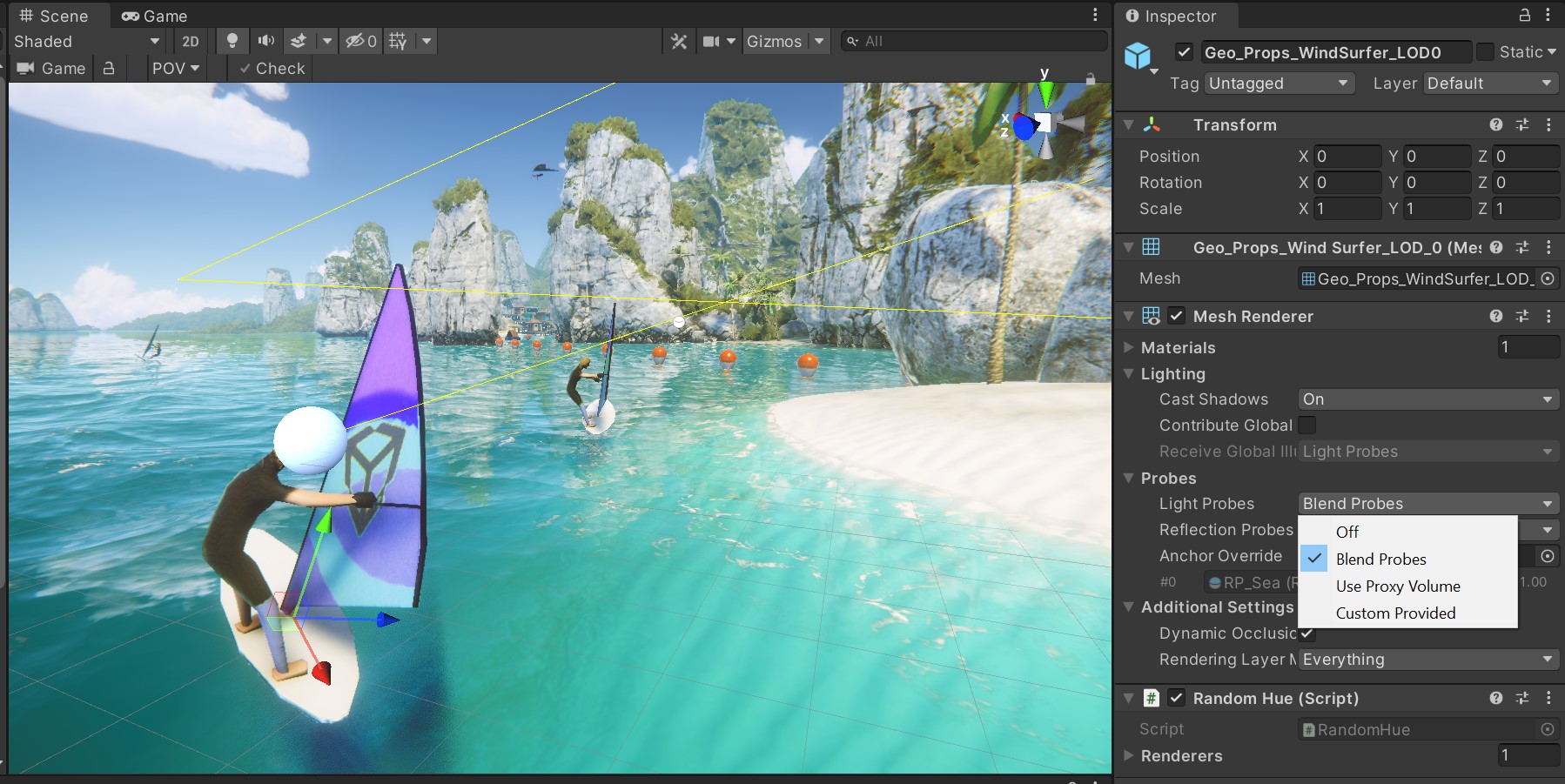
在运动物体上使用光照探针
光照探针可储存场景内空旷空间内烘焙好的光照信息,并以较高的质量还原光照效果(包括直接和间接光照)。探针的光照采用了球谐运算(Spherical Harmonics),相较于动态光照计算速度要快得多。

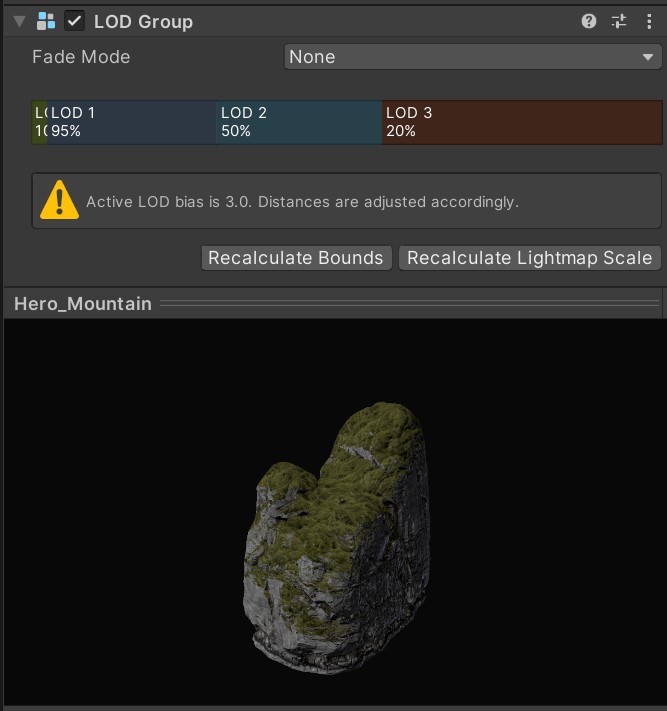
使用细节层级(LOD)
细节层级可在物体向远处移动时简化或替换原对象,应用更为精简的网格模型、材质和着色器,从而达到节省GPU性能开支的目的。



使用Occlusion Culling剔除不可见对象
许多藏在物体后方的对象仍会被引擎渲染、耗费一定的计算资源,我们可使用Occlusion Culling来舍弃这部分对象。
在摄像机视角外,引擎会自动执行视锥剔除,而视角内的遮挡剔除则需要提前烘焙:我们须将对象标记为Static Occluders或Occludees,然后找到Window > Rendering > Occlusion Culling窗口开始烘焙过程。虽然功能并非每个场景都需要,但适当利用可以提高一定的性能。
请在Working with Occlusion Culling教程中了解更多信息。
尽量不要采用设备的原生分辨率
随着手机和平板越来越先进,新设备的屏幕分辨率也变得非常高。
然而高分辨率会拖累应用性能,我们可以使用Screen.SetResolution(width, height, false)来降低输出图像的分辨率。多尝试几种分辨率,在质量和性能之间找到最佳平衡。
尽量减少摄像机数量
无论是否有用于呈现画面,每个摄像机都会产生一定的渲染开销。因此,我们只保留渲染所必须的摄像机即可。在低端移动平台上,每个摄像机能占用最多1毫秒的CPU处理时间。
保持着色器简洁
通用渲染管线包括几种轻量级的受光和非受光着色器,每种都已针对移动平台进行了优化。着色器变体的数量会对运行时的内存占用产生巨大影响,因此我们需要尽量减少着色器变体的数量。若默认URP着色器无法满足需求,你也可以试着用Shader Graph来定制材质的外观。请在此处详细了解怎样用Shader Graph可视化地编写着色器。


小心使用Renderer.material
在脚本中调用Renderer.material会让引擎复制一份材质的副本并返回一个该副本的引用名,这会破坏任何包含该材质的批处理。如果你想访问批处理对象的材质,请使用Renderer.sharedMaterial。
优化SkinnedMeshRenderers
渲染蒙皮网格会消耗大量计算资源,请尽量只在必须的对象上使用SkinnedMeshRenderer。如果某个GameObject在特定时段只需播放一些动画,我们可使用BakeMesh将蒙皮网格固定为一个静止姿势,然后在运行时切换到更为轻量的MeshRenderer。
尽量减少Reflection Probe(反射探针)的使用
反射探针可以生成逼真的反射效果,但在批处理时的计算开支很高。我们可以在探针上使用低分辨率立方体贴图、剔除遮罩和压缩纹理来降低其性能消耗。
下载完整优化指南
本文属移动端性能优化系列的最后一篇。如果你想学习全部的技巧和窍门,可在Unity中文课堂查看所有优化技巧。


若想详细了解Integrated Support服务,获希望让自己的团队直接联系到Unity的工程师、学习专家级建议和项目最佳实践,请在此处了解Unity的企业支持服务。
没有找到你要找的东西?
我们将尽力帮助你发挥出Unity应用的最大性能,若有任何想深入了解的优化主题,请在评论中向我们留言。
Is this article helpful for you?
Thank you for your feedback!