Boosting computer vision performance with synthetic data





You need a lot of data to train a computer vision model to effectively interpret its surroundings, which can strain resources. Read this guest post to discover how Neural Pocket, an AI solution provider, used synthetic data to enable its computer vision models.
Neural Pocket provides end-to-end AI smart city solutions for some of the largest Japanese corporations and local governments across various municipalities. As a rapidly growing startup headquartered in Tokyo, Neural Pocket aims to stay on top of cutting-edge technologies.
The company recently used synthetic data to maximize its results. Neural Pocket’s tool of choice for synthetic data generation is Unity Computer Vision, which includes the Perception Package that makes it easy for developers to quickly produce diverse datasets with randomized assets that are perfectly labeled for computer vision model training.
Learn more in this guest post from Neural Pocket by Romain Angénieux, Head of Simulation, and Alex Daniels, Senior Expert and Head of the Technology Incubation Team.
Why should you use synthetic data for computer vision tasks?
Computer vision tasks deal with interpreting data from images or videos and trying to gain an understanding of what they contain. This can be a simple classification of an entire image, or more detailed detections of the locations of specific objects within an image such as detecting human poses. Training a computer vision model to complete these tasks requires gathering and annotating a significant amount of data, a time-consuming and expensive venture.
Teams collect data in the real world primarily through photography and videography, but these methods have several drawbacks:
- Photography: Capturing the right shots can be quite difficult. For instance, having images reflecting different meteorological conditions across seasons may be desirable but also challenging and time consuming to shoot.
- Videography: Capturing actual real-life videos can lead to privacy challenges. For example, recording footage from a drone is not permitted in most urban areas of Japan, and recording with actors and hardware in specific locations requires non-trivial logistics planning and costs.
Once data is collected, teams often need to spend days manually labeling each image so that the computer vision model can learn to accurately identify what it’s seeing. This process ties up valuable resources internally or may be outsourced for additional cost.
One way to address these challenges is through the use of synthetic data, which enables teams to generate large quantities of images with perfect annotations in a short amount of time. With the ability to easily and quickly change parameters to generate new improved datasets (e.g., lighting, objects, materials, environments), and no dependency on the external factors mentioned above, the dataset creation process becomes significantly more streamlined.
Challenges of a homemade solution
We started creating synthetic data in August 2020 with a homemade Unity project. Our goal was to train a computer vision model to recognize and track moving vehicles and people for security purposes. Creating a simulation from scratch offers the advantage of freedom but can also be quite challenging and requires reinventing the wheel to a certain extent.
Within 3 weeks, we implemented the basic building blocks required to produce the synthetic data we required. These included ways to place objects in a scene, randomize environmental factors such as the background and lighting, and record and annotate the data. While we got decent results within a short time, generating the data required to further improve our computer vision performance meant significantly more complex and time-consuming additions were necessary.
Implementing features such as pixel-perfect bounding boxes that encompass only the visible parts of objects or object-placement algorithms to generate balanced datasets with objects in myriad positions turned out to be more complex than we first imagined. As a small team working on tight deadlines, we wished we had a reliable tool that already contained such features, allowing us to focus solely on our project’s specific needs.
Enter Unity Computer Vision
Soon after having this realization we discovered Unity Computer Vision, specifically the Perception Package, and were very excited to give it a try. We started using it to train an object detection AI and were surprised to get great results right out the box.
Computer vision models are highly domain dependent – that is, highly sensitive to variations in background, lighting and other environmental factors. Through a technique called domain randomization, wherein synthetic images have large degrees of randomization based on said environmental factors, a robust dataset can be generated. The Perception Package contains a simple UI to control sets of customizable components such as scenarios, randomizers, tags, labels and smart cameras, all with the aim of achieving domain randomization to improve computer vision performance. It allows for an organized flow and structure, and is highly reusable across any perception project.
But in most cases, designing custom randomizations is not necessary, since the package comes with all the basic tools needed to get started. As a result, we were able to instead shift our focus to the acquisition of 3D models from the Unity Asset Store and other marketplaces, and integrating them into the UI with a simple drag and drop.


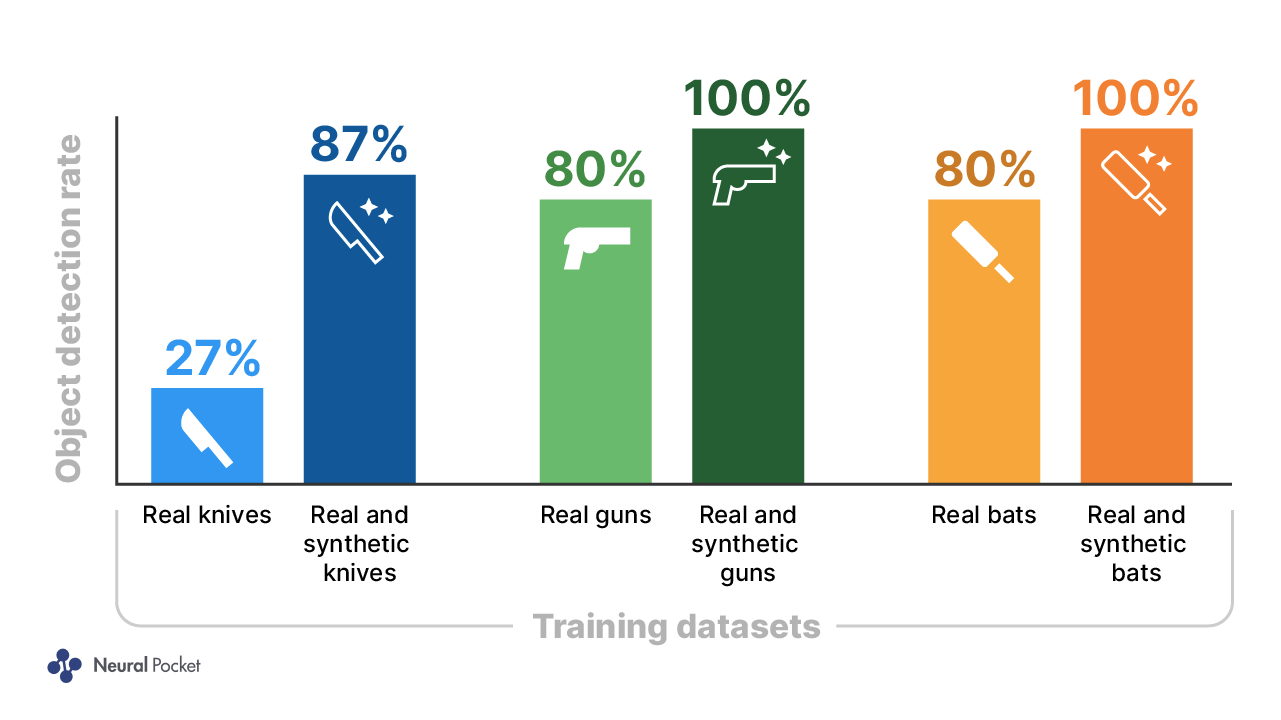
To illustrate this statement, figure 2 shows the performance of our AI both with and without synthetic data. Using the Perception Package’s default configuration with no changes except the addition of 3D models, the detection rate increases by between 20% and 60%, depending on the object in question.

Advanced uses of the Perception Package
Using the default configuration of the Perception Package is enough to get a consequent boost in terms of computer vision performance; however, much more can be built on top of the existing tools to cover as large a domain as possible. It’s even viable to change the internal logic of the Perception Package since it is open source.
Some good examples of custom randomizations are the ones we developed to train a computer vision model to detect people taking pictures with their smartphone, as part of a measure to protect confidential information, such as credit card numbers. Recognizing smartphones is a very challenging task for the following reasons:
- A wide range of models
- An infinite number of possible phone case designs
- They are held and partially covered by fingers in different ways
- Many objects could be mistaken for a smartphone
Our solution to this technical challenge was to design a logical method of combining various base components to generate realistic phones representative of the market. To that end, we created 3D models of existing phones with their visible components, such as their logos and cameras, separated from their bases. Using a system of anchors, we swapped these elements from one phone to another to create new combinations.
To account for the phone cases, we performed texture mappings so that any image from the Google Images API could be mapped to our phone cases and be a perfect fit without hiding the lenses or the brand logo.
Taking a picture requires holding the phone, so we created modular hands that can hold any phone, no matter its dimensions, with different poses, and we added skin variations as a finishing touch.
Finally, since many objects can look like a smartphone from a computer vision model’s perspective, we also created non-annotated trap objects: objects that have a similar shape and style to smartphones, but should not be detected. This introduced the notion that “not every held rectangular object is necessarily a phone” to the model. The introduction of these objects drastically reduced the number of false positives predicted by the AI.
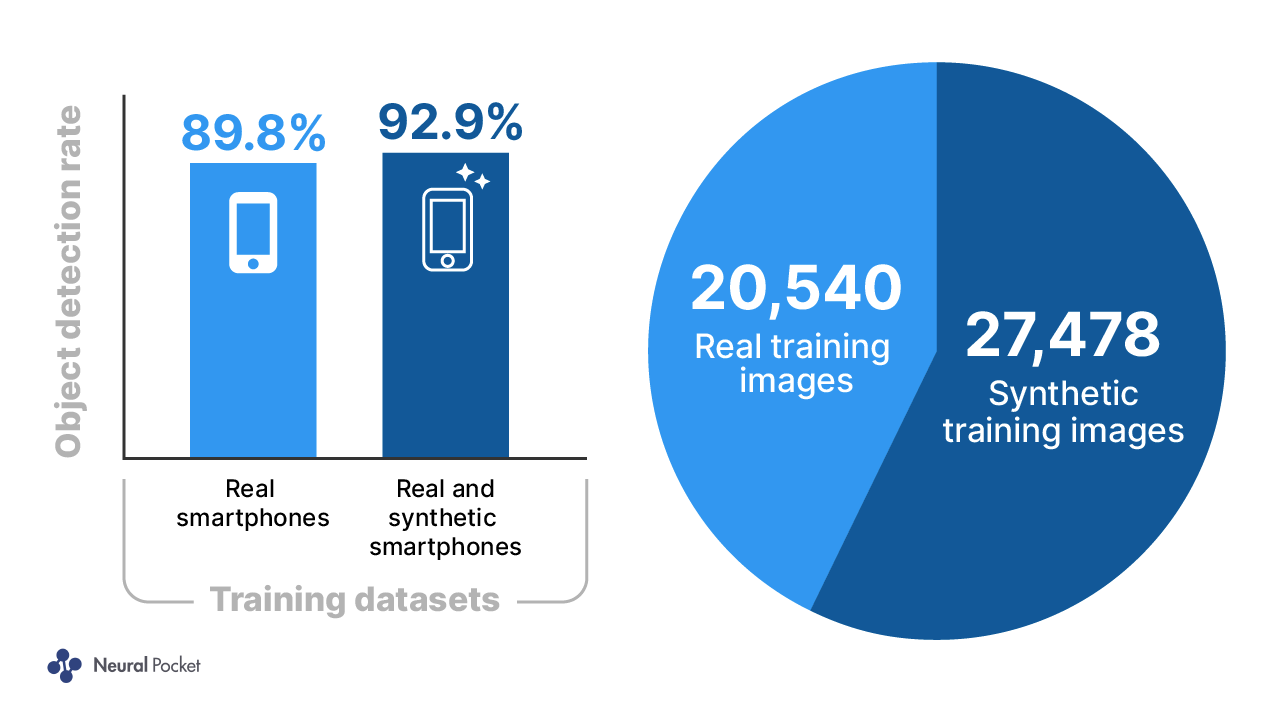
In our latest iterations the difference in terms of accuracy after adding synthetic data is 4% (see Figure 3). As the phone detection program runs over a series of video frames, a gain of 4% on static images can lead to a significant gain in detection rates for phones as a whole.





The business impact of Unity Computer Vision
Typically, when training a model on real-world data, numerous iterations are required, often as many as 30 training cycles. Each of these cycles requires data collection, annotation, training and then evaluation, which on average takes around one week per cycle, and costs in the realm of $2,000 to $5,000 depending on the project. Thus, for a set of 30 cycles the costs skyrocket to $60,000–$150,000 and 4–6 months to make a production-ready model.
In comparison, when using synthetic data created with the Perception Package and only one cycle of real-world training, we created a better model in just over one week at significantly reduced costs, essentially saving about 95% in both time and money.


With the increase in variation of data that the Perception Package can provide, the necessity for real-world data collection is reduced. The performance of the computer vision models is also improved, resulting in higher-quality products. All of these points not only benefit our organization internally, but also benefit our partners.
Thanks to the savings made by using simulation, we can now consider its advantages when deciding which projects/products to pursue commercially. Essentially, it has widened the scope of the quantity of projects we can take on simultaneously allowing not only for savings, but increased volume of sales.
What’s next
Since we started using it, the Unity Computer Vision Perception Package has received regular updates with new features that support more randomizations, a more intuitive UI and more freedom in terms of data recording. With recent version updates, the Perception Package can save bounding boxes, human pose estimation data and other custom 3D point data.
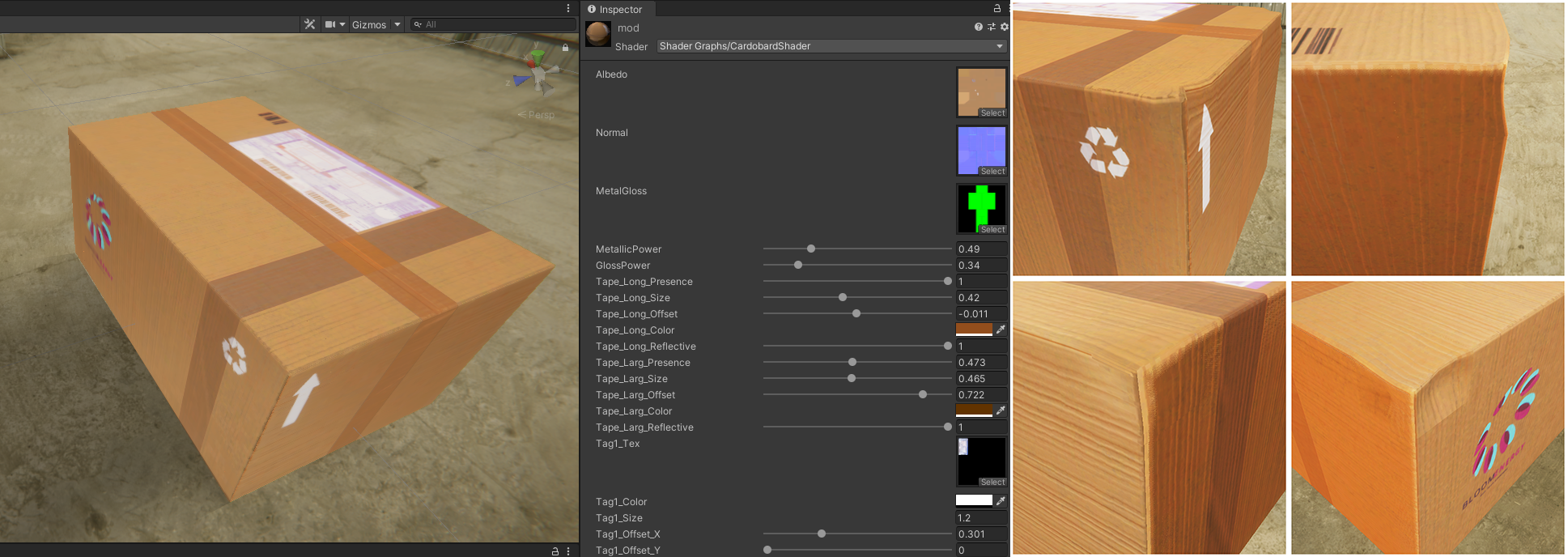
One of our projects that benefits the most from this is a computer vision model we are developing for smart factories that allows us to analyze cardboard boxes. Our simulation needs to account for any condition they might be in, such as dented or damaged, as well as labels and logos on their surfaces.
For this project, we can take the time to develop complex shaders, randomizing every aspect of our objects without having to worry about the integration in the Package as we now know that this will be quick and easy.

With its active development focused on user’s needs, we expect the Unity Computer Vision Perception Package to keep improving over time, becoming a reference for perception tasks and a starting point for our perception projects.
***
Our thanks to Romain and Alex from Neural Pocket for contributing to this guest post. For more information:
- Check out this case study to learn more about Neural Pocket’s work with Unity.
- Learn more about Unity Computer Vision and try our Perception Package free. Don’t have Unity developers on your team? Contact us to get help building synthetic datasets.
- Sign up for our mailing list to get updates about all things computer vision.
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies