Unity AI 2021 interns: Accelerating learning with the ML-Agents Toolkit





AI@Unity is working on amazing research and products in robotics, computer vision, and machine learning. Our summer interns worked on AI projects with real product impact.
The ML-Agents Toolkit allows researchers and game developers to build and train agents in Unity environments using Reinforcement Learning (RL). RL is useful when it is easier to specify what task an agent needs to complete rather than how to do it. An agent learns to select actions to complete a task on its own using observations from its environment and a task reward signal.
During the summer of 2021, our interns worked diligently to create valuable contributions to our work at Unity. Read about their projects and experiences in the following sections.
Discoverable Behavior Diversity
Kolby Nottingham, Computer Science, University of California Irvine
Whether deploying agents in the real or simulated world, users often want control over how an agent completes a task. They don’t just care about task success; they want it done a certain way. Achieving a desired behavior can be difficult to accomplish and often requires repeatedly retraining an agent while tweaking environment parameters. In this project, we explore a method to learn a variety of behaviors during training and provide a means for the end user to select the behavior that they prefer.
We implement Maximum Entropy Diverse Exploration (MEDE) and apply it to tasks in the ML-Agents toolkit. This method encourages an agent to solve a task in different ways during training so that after training, a user can specify which learned behavior to use. Behaviors are discovered automatically rather than predefined, and MEDE encourages behaviors to be as different as possible while still solving the original task. An agent learns behaviors by training a discriminator to predict the probability that an agent’s experience came from a particular behavior. MEDE then incentivises the agent to act so that the discriminator can easily tell which behavior the agent is using.
The original MEDE algorithm only tested agents that sample actions from a continuous space. Part of this project was modifying MEDE to work with agents with a discrete or mixed set of actions. Additional changes to MEDE include parameter schedules and additional regularization on the discriminator network to improve the robustness of training. While MEDE originally required users to define a fixed number of behaviors for the agent to learn, we expanded MEDE to work with behaviors that had a continuous range of possible values. MEDE with continuous behaviors allows the agent to learn a potentially infinite number of behaviors, all of which transition smoothly. In practice, achieving smoothly transitioning behaviors depends largely on the current task. This line of work aims to alleviate much of the tweaking and tuning that requires RL expertise making RL in Unity environments more accessible to the non-expert.
Simplifying Hyperparameters in ML-Agents
Scott Jordan, Computer Science, University of Massachusetts

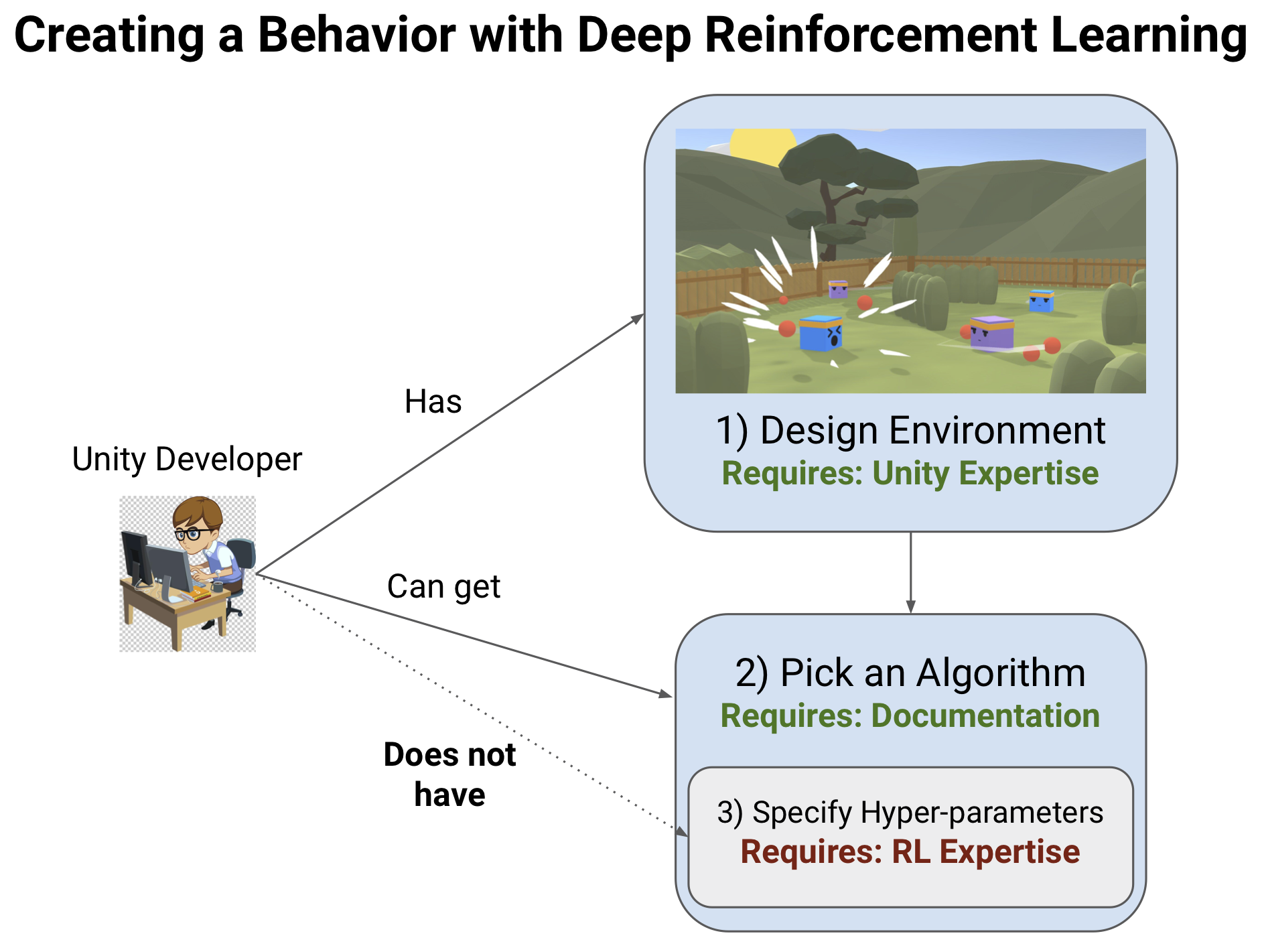
When used effectively, Reinforcement Learning (RL) can learn complex behaviors and play the role of Non-playable Characters (NPCs) or bots in a game, with minimal code. One necessary and challenging aspect of using RL to learn agent behaviors is to specify an algorithm's hyperparameters, such as the learning rate and network size. These parameters can be unintuitive and brittle so that an incorrect setting can prevent the learning of desirable behaviors. Consequently, trial and error, as well as RL expertise, are often a requirement for the successful application of RL. For this project, we focused on discovering the relationships between various hyperparameters with the goal of reducing the number of changes required to maximize performance.
The project's main contribution is to modify Proximal Policy Optimization (PPO), a common and effective RL algorithm, such that the user needs to adjust only two instead of five of the most commonly tweaked hyper-parameters. We reduce the number of hyperparameters by grouping five parameters into two groups: frequency and work. The frequency parameter controls how often the agent's behavior is allowed to change, while the work parameter controls how much the agent's behavior is allowed to change per step of the learning process. Additionally, since the relationships between variables are better understood, some hyperparameters can be automatically adjusted to maximize computational efficiency during training. To test the algorithm changes, we made custom environments (games in Unity that can be used to train RL agents) that can have their characteristics, such as the reward function and the number of parallel simulations, changed without rebuilding the Unity game each time. Once this work is integrated into the ML-Agents Toolkit, users will be able to train a good behavior with much less trial and error and tweaking of obtuse parameters than before.
Computer Vision Sensor for ML-Agents
Grant Bowlds, Computer Science and Mathematics, Vanderbilt University


I had the opportunity to create a Computer Vision (CV) sensor for Unity’s ML-Agents Toolkit. The ML-Agents Toolkit allows researchers and game developers and researchers to build and train agents in Unity environments using Reinforcement Learning (RL), specifically using visual or numerical based observations. While numerical observations like distance and direction to a target allow the agent to learn very quickly, using numerical observations is limited and does not support a diverse range of problem areas. Visual observations are better suited in situations where the agent’s state and environment are difficult to quantify. However, visual observations require more training at a slower pace than numerical observations. I created a sensor that allows creators to use the output of their own pretrained CV models as observations, which creates some inductive bias but allows training to speed up with superior results. This sensor will make the ML-Agents Toolkit more accessible to customers attempting to leverage their own CV models for reinforcement learning.
The most challenging part of my project was creating and using a complex machine learning workflow. Errors could show up at any point in the pipeline which made debugging very difficult, but I was able to learn a lot about working intentionally and solving problems efficiently. Next steps for the project include creating a demonstration and incorporating it into a release of ML Agents extensions. My favorite part of this project was the scope of Unity products that I was able to use. I used the Computer Vision Perception package to generate synthetic data to train a CV model for my sensor, the Barracuda package to support my model, and both ML-Agents toolkit and ML-Agents Cloud to create my sensor and train an agent.
Join our team
If you are interested in building real-world experience by working with Unity on challenging artificial intelligence projects, check out our AI careers page and students can see openings on out university careers page. You can start building your experience at home by going through our demos and tutorials on the ML-Agents Toolkit Github.
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies