2021 年の Unity AI でのインターン報告:コンピュータービジョンで未来を見据える



AI@Unity では、ロボット工学、コンピュータビジョン、機械学習の分野における素晴らしい研究や製品に取り組んでいます。今夏、Unity にやってきたインターン生は、実際の製品に影響を与える AI プロジェクトに取り組みました。
Unity Computer Vision チームが開発した Perception Package は、Unity のリアルタイム 3D エンジンを使って合成データを作るユーザーを支援するパッケージです。合成データは、コンピュータービジョンの開発者が、機械学習に基づくビジョンアプリケーションにおいて、偏りの排除、エッジケースの生成、データの多様性の向上、画像の完全なラベリングなどを行って、実世界のデータセットを補完するために使われます。また、合成データに関する専門知識と研究を活用して、顧客向けに独自のカスタムデータセットを作成しています。
2021 年の夏、Unity にやってきたインターン生は熱心に働き、Unity の活動に貴重な貢献をしてくれました。以下のセクションでは、インターン生たちのプロジェクトや経験についてご紹介します。
合成データを用いた弱教師ありインスタンスセグメンテーション
Eric Crawford さん(博士(コンピュータサイエンス)、マギル大学)


インスタンスセグメンテーションはコンピュータービジョンのタスクの 1 つで、入力画像内のどのピクセルがどのオブジェクトに対応するかを示すモデルを構築することを目的とするものです。現在、Mask R-CNN [1] などのディープニューラルネットワークは、インスタンスセグメンテーションのための最新技術だと言えるでしょう。しかしこうしたネットワークは、実世界のドメインで高い性能を発揮するために何万ものラベル付きのサンプルを必要とし、データを極めて大量に消費するものとなっています。これは、バウンディングボックス(物体の位置を示す 2 次元の箱)と、セグメンテーションマスク(どの画素が物体に対応するかを示す画像サイズの 2 値マスク)の 2 種類のラベルを使用します。これらのラベルは通常、人間のアノテーターによって提供されますが、セグメンテーションマスクの作成にはバウンディングボックスよりもはるかに多くの時間と労力が必要とされます。このプロジェクトでは、入手困難なセグメンテーションマスクが比較的少ない場合でも、ディープインスタンスセグメンテーションネットワークの学習が可能かどうか、また、セグメンテーションマスクが少ない、あるいは存在しない場合に、合成データが性能向上に役立つかどうかを検討しました。
まず最初に、実際のデータ(COCO データセットなど)において、多くのバウンディングボックスラベルがある場合、高いセグメンテーション性能を得るためには、そのうちのどの程度の割合でセグメンテーションマスクラベルを添付する必要があるのか、という問いに答えようとしました。その結果、セグメンテーションマスクでラベル付けされたデータ(つまり完全にラベル付けされたデータ)がわずか 1% でも、全てのデータが完全にラベル付けされている場合の 90% 近くの性能を達成できることがわかりました(プロット参照)。

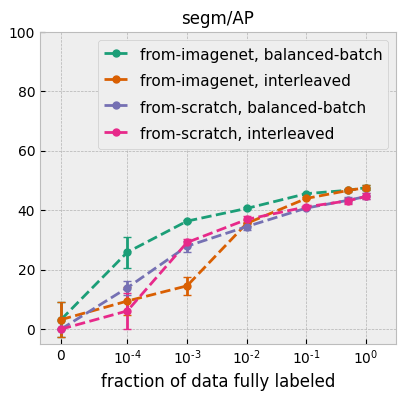
この結果は、インスタンスセグメンテーションのためのラベリングの負担を大幅に軽減できる可能性を示唆するものです。また、今後の研究に向けての刺激的な道筋を示すものでもあります。例えば、合成データを使って、1% だけ完全なラベル付けがされたデータを使う場合と 100% 完全にラベル付けがされたデータを使う場合の間の性能差を埋めることができるでしょうか。真の正解となるセグメンテーションマスクを合成データで完全に置き換えることはできるのでしょうか。真の正解となるバウンディングボックスの数が減ると、合成データの利用可能性はどのように変わるのでしょうか。合成のインスタンスセグメンテーションデータを使ったトレーニングの初期的な結果は有望なものでした。
Dataset Visualizer
Leopoldo Zugasti さん(コンピューターサイエンス専攻、マギル大学)
Dataset Visualizer python ツールを使うと、Unity Perception パッケージを使用して生成されたデータセットなど、Unity Perception 形式を利用したコンピュータービジョンデータセットの閲覧とビジュアライゼーションを行うことができます。これらのデータセットには、合成環境や物体の画像と、2D および 3D バウンディングボックス、セマンティックセグメンテーション、インスタンスセグメンテーション、キーポイントなど、真の正解を与えるアノテーションが含まれています。これらのデータセットは、物体検出や分類などのタスクのためのコンピュータビジョン AI モデルのトレーニングに使用されます。
Dataset Visualizer は、ユーザーがこれらのデータセットを簡単かつ効率的に閲覧し、画像を複数の選択可能なオーバーレイとして視覚化した、真の正解のアノテーションとあわせて確認することができます。このツールは、様々なユースケースでユーザーの役に立ちます。
- Perception パッケージを使用してデータセットを生成するための Unity 3D 環境の構築は、コードやシーンの修正を何度も繰り返しながら、生成されたデータセットを確認して微調整を行い、最良の結果を得ることを目的としています。Dataset Visualizer では、生成された最新のデータセットを数回クリックするだけでその内容を確認できるため、ユーザーの反復プロセスを大幅に高速化します。
- データセット生成ツール以外にも、Unity はコンピュータービジョンで行われる学習のニーズに合わせたオーダーメイドのデータセットを提供しています。顧客は Dataset Visualizer を使って、Unity が提供するデータセットを簡単に調査・検証することができるので、アノテーションのビジュアライゼーション機能を持たない一般的なフォトビューアを使用する場合に比べて、作業の体験を大幅に改善することができます。
このツールを作成している間に、人工知能、コンピューターネットワーク、コンピューターグラフィックス、ウェブ開発など、コンピューターサイエンスのさまざまなトピックについて学ぶ機会がありました。Unity で提供されているリソースと、素晴らしい人々と一緒に仕事をする機会を得たおかげで、私は、異なるカメラ投影タイプでの 3D ボックスのレンダリング、ポート衝突の自動解決、さまざまなオペレーティングシステムと互換性のあるアプリケーションの作成など、予想外の難しい問題をいくつも解決することができました。
データセットプレビュー機能
Jamie Won さん(コンピューター工学専攻、クイーンズ大学)

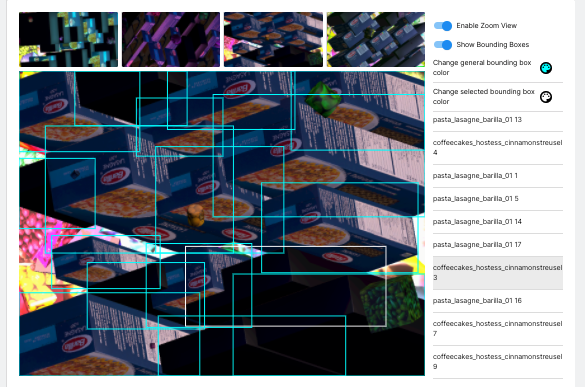
AI@Unity は、大規模な合成データセットを作成する機能を提供することで、コンピュータービジョンに取り組む顧客を支援しています。データセットのサンプルをいくつか公開していますが、これまでユーザーはデータセットをダウンロードして画像を抽出しないとそれを見ることができませんでした。これらのデータセットは小さくないため、顧客がデータセット内の画像を閲覧するまでに、顧客の使っているネットワークの帯域幅に応じた待ち時間が生じることになっていました。カスタムデータセットの場合でも、ユーザーは内容を見る前にダウンロードする必要があり、データを反復修正するサイクルが遅くなることがありました。
データセットプレビュー機能は、ダウンロードする前にデータセットのサンプルを確認することができ、ユーザー体験を向上させるものです。ユーザーのニーズに合わせてデータセットを調整する必要がある場合、ユーザーは新しいデータセットを生成し、ダウンロードする前に一旦プレビューすることができます。この機能では、1 ページに表示される画像のサイズや枚数を変更したり、各画像を拡大したりすることができます。画像を確認しやすくするために、ズームされた画像上でバウンディングボックスを有効にし、また必要に応じてボックスの色を変更することができます。
一番怖かったのは、ユーザーの目に触れる機能になることがわかっていたことです。実際、ほとんどすべてのユーザーが使用することになるツールということだけでなく、プロジェクトに参加している他の開発者が、自分の作業をプレビューするためにもよく使われていました。組織のコード提出ガイドラインを学びながら、それに従って既存の製品に機能を統合することは困難でしたが、最終的にはすべての経験が非常に満足のいく学習の旅となりました。
深度画像の Sim2Real ギャップを探る
Blake VanBerlo さん(コンピューターサイエンス専攻、ウォータールー大学)


十分にラベル付けされた大規模なデータセットを見つけることは、機械学習の専門家が直面する大きな課題です。データセットへのラベル付けには費用がかかり、またデータセットに望ましくない偏りが含まれていたり、実世界を十分に表現していなかったりする場合があります。Unity はレンダリングパイプラインを利用して、コンピュータービジョンのタスクのためのラベル付き合成データセットを作成することで、この問題に対処しています。私のインターンシップは、実際のセンサーから収集した深度トレーニングデータの代わりとなる合成深度画像の開発と研究に取り組んだものです。合成深度画像を用いて学習した機械学習モデルは、実世界のデータでテストしたときに良い結果を出せるのでしょうか。ギャップを埋めるために、どの程度のリアリティが必要なのでしょうか。
深度マップとは 1 チャンネルの画像で、各画素はカメラからその画素を占める物体までの、カメラの前方軸方向の距離を表しています。私が開発したのは、Unity のシーンのカメラビューに対応する深度マップを生成するラベラーです。深度画像の有用性を評価するために合成データセットを作成し、単一の物体の 6D ポーズ推定のモデルのトレーニングを行っています。私たちは、2 つの最新モデルと、私たちが設計した新しいアーキテクチャを研究しています。データセットの各サンプルには、カラー画像、深度画像、オブジェクトマスク、および回転と平行移動の量の真の平均からなる物体のポーズのラベルが含まれています。次に、合成データで学習したモデルを、LineMOD データセットから取った実世界の画像でテストします。またリアリティが与える影響を調べるために、ノイズモデルで変更を加えた合成深度画像を使った実験も行っています。加えたノイズは、LineMOD の深度画像に含まれるノイズに似せたものです。本記事執筆時点ではプロジェクトが進行中のため、結果はまだ出ていません。
合成深度トレーニングセットが実世界で満足のいく性能を発揮すれば、ユーザーは Unity の合成データパイプラインを、より多様なコンピュータービジョン問題に適用することができます。高品質の深度画像を収集するにはコストがかかり、しかも収集自体が難しいため、合成データは魅力的な選択肢となるのです。
リグの自動化とサイズ変更
Kathy Huynh さん(3D アートジェネラリスト専攻、ISART Digital Montreal)
コンピュータービジョンのトレーニングを成功させるには膨大な量のラベル付き画像が必要ですが、実世界のデータをラベル付けするプロセスは長くて面倒です。この問題を解決するために、私たちは Unity Perception パッケージ を利用してカスタムの合成データセットを顧客向けに作成しています。この技術を使えば、さまざまな物体や人が存在する多様な環境を作り出すことができます。Randomizer スクリプトを使用すると、オブジェクトの位置、回転、アニメーション、テクスチャ、ライティングなどのパラメーターをランダム化することができます。フレームと呼ばれる画像は、リアルな 3D シーンをリアルタイムにレンダリングすることで、ほぼ瞬時に生成されます。今回のプロジェクトでは、リグの自動化とリサイズをテーマに、Perception パッケージに継続的に機能を追加していっています。このプロジェクトでは、Blend Shape Randomizer スクリプトや、現在開発中のリギングツールとスキニングツールを用いて、デジタルヒューマンのブレンドシェイプをランダム化し、リグを自動的に適合させることを目指しています。私たちは、ある顧客と密接に協力して、顧客が必要とする合成データセットを 4 週間かけて作成しました。既存のランダマイザーを改造し、顧客のニーズに合わせて、人物やライティングにランダム化をかけた室内外のシーン環境を組み上げました。この作業を優先して行った後は、人間のリギングとスキニングの自動化ツールに集中することができました。インターンシップ終了時には、Skinning オートメーションツールの作業も進めつつ、Bones Placer ツールを完成させることができる見込みです。
この 2 つのプロジェクトでは合成データについてより深く学ぶことができただけでなく、マネージャーやメンター、同僚のサポートを受けながら、困難な問題にテンポの速い環境で取り組むことができたため、非常にエキサイティングでやりがいを感じることができました。顧客のプロジェクトに参加することは、最初はとても大変なことでしたが、結果的にはとても貴重な経験となりました。機械学習の分野には、私が経験のあるゲームの分野とは異なるニーズがあるため、顧客からのフィードバックを受けて繰り返し修正を重ねていくことが勉強になりました。さらに、ライティングやポストプロセッシングに関する作業、およびテクスチャの見た目をランダム化するシェーダーグラフの作成などを通じて、HD レンダーパイプラインとシェーダーグラフに関する知識を深めることができました。私はいち早く Perception パッケージ、特に Randomizer のロジックを理解して、ニーズに応じてこれらを修正できるように備えておきました。Blend Shape Randomizer は、ターゲットメッシュに新しいブレンドシェイプとしてメッシュを追加し、その重みをランダム化するものですが、これをゼロから書いて仕上げるためにこの新たに得た知識を活用しました。これにより、ブレンドシェイプや、Unity の API、Perception 固有の API について詳しく知ることができました。また、Houdini の Python スクリプティングについてもさらに掘り下げて調べ、Houdini のメッシュから頂点データを .json ファイルにエクスポートする作業を行いました。このファイルは Unity の Bones Placer ツールに渡され、頂点データから予想されるボーンの位置を計算し、事前にデータを収集したものと同じ頂点 ID を持つターゲットメッシュにボーンが生成されます。このツールは私が現在開発しているもので、前に述べたように、私のインターンシップが終わるまでに完成させる予定です。生成されたボーンは、現在私の同僚が開発しているスキニング自動化ツールを使って、メッシュのスキンを設定するために使われます。総合的に見て、膨大な量の技術的な知識を得ることができたので、とても感謝しています。また、合成データを使って Unity や同社の顧客が成功を収められるように、さらに学びを深められることを楽しみにしています。
3D キャプチャーシミュレーションのためのエンコード最適化
Priyanka Chandrashekar さん(修士(コンピューターサイエンス、ビジュアルコンピューティング専攻)、サイモンフレーザー大学)
リアルタイム 3D は今日の世界を変えています。また、没入型 3D 体験で使う非常にリアルなコンテンツを作成するにあたり、3D およびボリューメトリックキャプチャーがまるで本物のようなキャラクターを作り出すための基礎となっています。Volumetric Format Association の創設メンバーとして、Unity Simulation プラットフォームは、ボリュームおよび 3D キャプチャーシミュレーションによって、この成長市場に参入する道を開いています。3D キャプチャーはまだ比較的新しい技術であるため、3D キャプチャーのアルゴリズムを改善し、最適なキャプチャーシナリオを作成するための大規模なシミュレーションが必要とされています。シミュレーションによってリアルなコンテンツを作るためには、カメラのレイアウト、シナリオ、アクター、ライティングなどを徹底的にテストする必要がありますが、それには莫大な費用がかかります。このプロジェクトは、最適なソリューションを提示し、3D キャプチャーやボリューメトリックビデオシミュレーションについて十分な情報を得た上でプロジェクトを進めたいと考えている顧客にとって、参入障壁を低くするものです。
この 3D およびボリューメトリックキャプチャーシミュレーターは、顧客がユースケースに合わせてプロセス全体を最初から最後までよりよく理解し、プロセスの最後に最終的な 3D コンテンツのビジュアライゼーションを行う上で役立ちます。ボリューメトリックキャプチャーのシナリオに最適なカメラの配置や、バリエーションが無限にある物体のキャプチャーのシミュレーションなど、顧客が直面する問題を絞り込み、解決するために設計されています。シミュレーターでは、複数のセットアップのシミュレーションを行い、ハードウェアの配置を評価することができるため、3D やボリューメトリックキャプチャーなど、ハードウェアを多用する技術を大規模に使用する際に、十分な情報を得た上で長期的な判断を下すことができます。このような設定可能なシミュレーターは、プロセスに関する詳細な知見を提供するだけでなく、最適で高品質な 3D コンテンツ生成のための重要な要件である、さまざまな環境下におけるソース 3D データの生成を行うための、複数のランダム化された実験を実行する手段を提供します。
これまでにも Unity を使ってゲームを作ったことはありましたが、初めて 3D コンテンツのキャプチャーやシミュレーションを扱うことができ、非常にエキサイティングでやりがいがありました。このインターンシップでは、3D コンテンツをエンジンに統合する方法をすぐに習得しました。また、その統合は、より多様なデータを得るためのシナリオオプションの変更、メタデータやシミュレーションされたセンサーのデータセットの保存、修正可能な構成の提供など、シミュレーター特有の要件を満たすことで、顧客がさまざまな状況で 3D キャプチャーソリューションの品質を向上させることができるような形で行いました。世界的にボリューメトリックビデオの市場が拡大する中、このツールが顧客にどのように活用され、3D キャプチャーのニーズをどのように満たして、顧客の成功に役立っていくのか楽しみです。
私たちのチームに参加しましょう
Unity を使って挑戦的な人工知能プロジェクトに取り組み、実社会での経験を積むことに興味がある方は、大学生向けの採用ページをご覧ください。Unity Computer Vision の GitHub に上がっているデモやチュートリアルを見て、自宅で自分の届けたい体験を作り始めることができます。
[1] He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-CNN. In Proceedings of the IEEE international conference on computer vision (pp. 2961-2969).
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies