ドッジボールをプレイする ML-Agents





最近、ML-Agents に MA-POCA アルゴリズムが追加されたことで、誰にでもエージェントのグループに協調行動を学習させることができるようになりました。この新しいアルゴリズムは、中央集権的な学習を分散的に実行するものです。中央の評価器(ニューラルネットワーク)がグループ内の全エージェントの状態を処理してエージェントの状態を推定し、複数の分散されたアクター(エージェントごとに 1 体)がエージェントを制御します。これにより、各エージェントは、局所的に認識したものだけに基づいて意思決定を行い、同時に、グループ全体の文脈の中で自分の行動がどれだけ優れているかを評価することができます。下の図は、MA-POCA の中央集権型学習と分散実行を表しています。

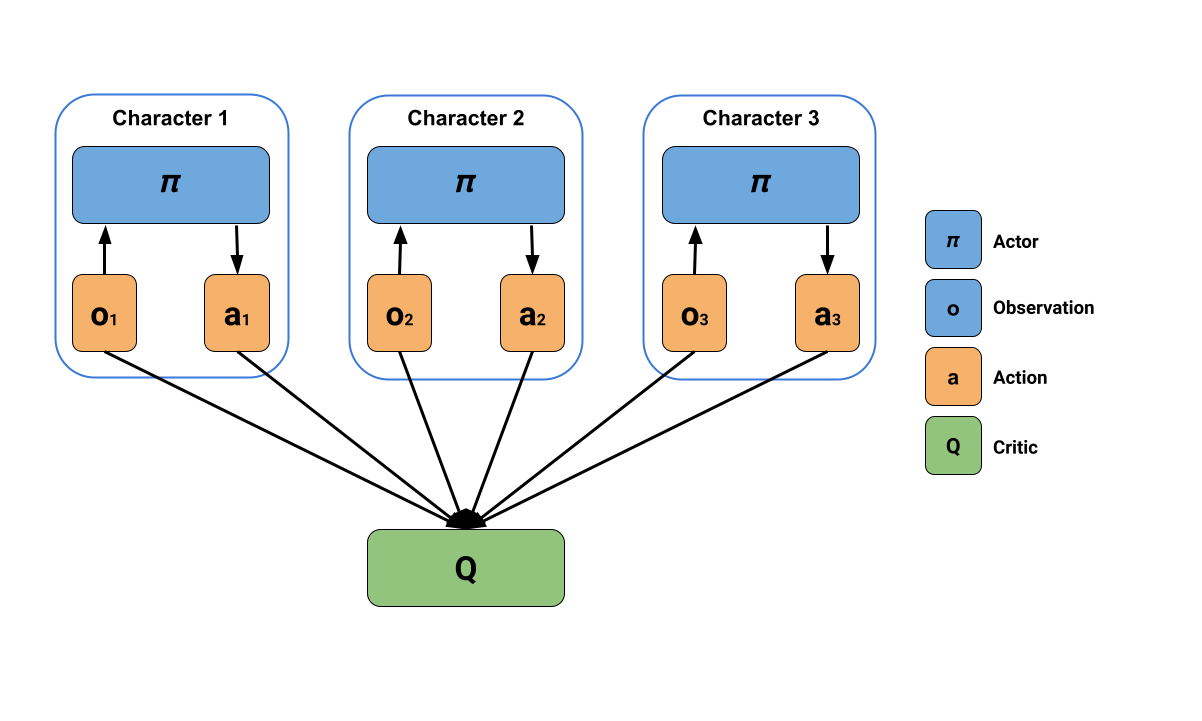
MA-POCA アルゴリズムの新規性の 1 つは、アテンションネットワークと呼ばれる、数が固定されていない入力を処理できる特殊なタイプのニューラルネットワークアーキテクチャを使用していることです。これは、中央の評価器が任意の数のエージェントを処理できることを意味しており、そのため、MA-POCA はゲームにおける協調行動に特に適しているとされます。ビデオゲームのキャラクターがチーム戦の途中で脱落したり、途中参加したりするのと同じように、エージェントを任意のタイミングでグループに追加・削除することができます。また、MA-POCA は、エージェントが自分の不利益になっても、チームの利益のためになるような意思決定ができるように設計されています。このような利他的な行動は、手作業でコード化された行動では実現が難しいものですが、エージェントが最後に取った行動がグループ全体の成功にどれだけ役立ったかに基づいて学習することが可能です。最後に、多くのマルチエージェント強化学習アルゴリズムは、すべてのエージェントが同時に次の行動を選択することを前提としていますが、実際のゲームではものすごい数のエージェントが存在するため、フレームドロップを避けるために、通常は異なるタイミングで意思決定をさせた方が良いでしょう。そのため、MA-POCA はこのような前提を持たず、1 つのグループ内のエージェントの意思決定が同期していなくても機能するようになっています。MA-POCA がゲームでどのように機能するかをお見せするために、私たちは DodgeBall 環境を作りました。ML-Agents を使って完全な学習を行った AI を使い、楽しいチーム対戦型ゲームを行う環境です。
DodgeBall 環境
DodgeBall 環境では、プレイヤーができるだけ多くのボールを拾い、それを相手に投げつけるという三人称視点のシューティングゲームが行われます。このゲームにはせん滅戦(Elimination)とフラッグ戦(Capture the Flag)の 2 つのモードがあります。せん滅戦での各グループの目的は相手グループのメンバー全員をアウトにすることです。2 回ボールを当てられるとアウトになります。フラッグ戦は、相手チームの旗を奪って自陣に持ち帰ることを目的としたゲームです(自陣の旗が自陣で安全な状態でなければ得点できません)。このモードでは、プレイヤーはボールに当たると旗を落として 10 秒間行動不能になり、その後ベースに戻ります。どちらのモードでも、プレイヤーは最大 4 つのボールを持つことができ、ダッシュで飛んできたボールをかわしたり、垣根をくぐったりします。
強化学習では、エージェントは環境を観測し、報酬を最大化するために行動します。エージェントが DodgeBall 環境でのプレイができるように訓練するための観測、行動、および報酬について、以下に説明します。
DodgeBall 環境では、エージェントは以下の 3 つの情報源から環境を観測します。
- レイキャスト:レイキャストにより、エージェントは自分の周りの世界がどのように見えるかを感じることができます。エージェントはこの情報をもとに、ボールを検知してつかみ、壁を避け、相手を狙います。様々な色で表現されたレイキャストのセットは、それぞれ異なるオブジェクトクラスを検出するために使用されます。

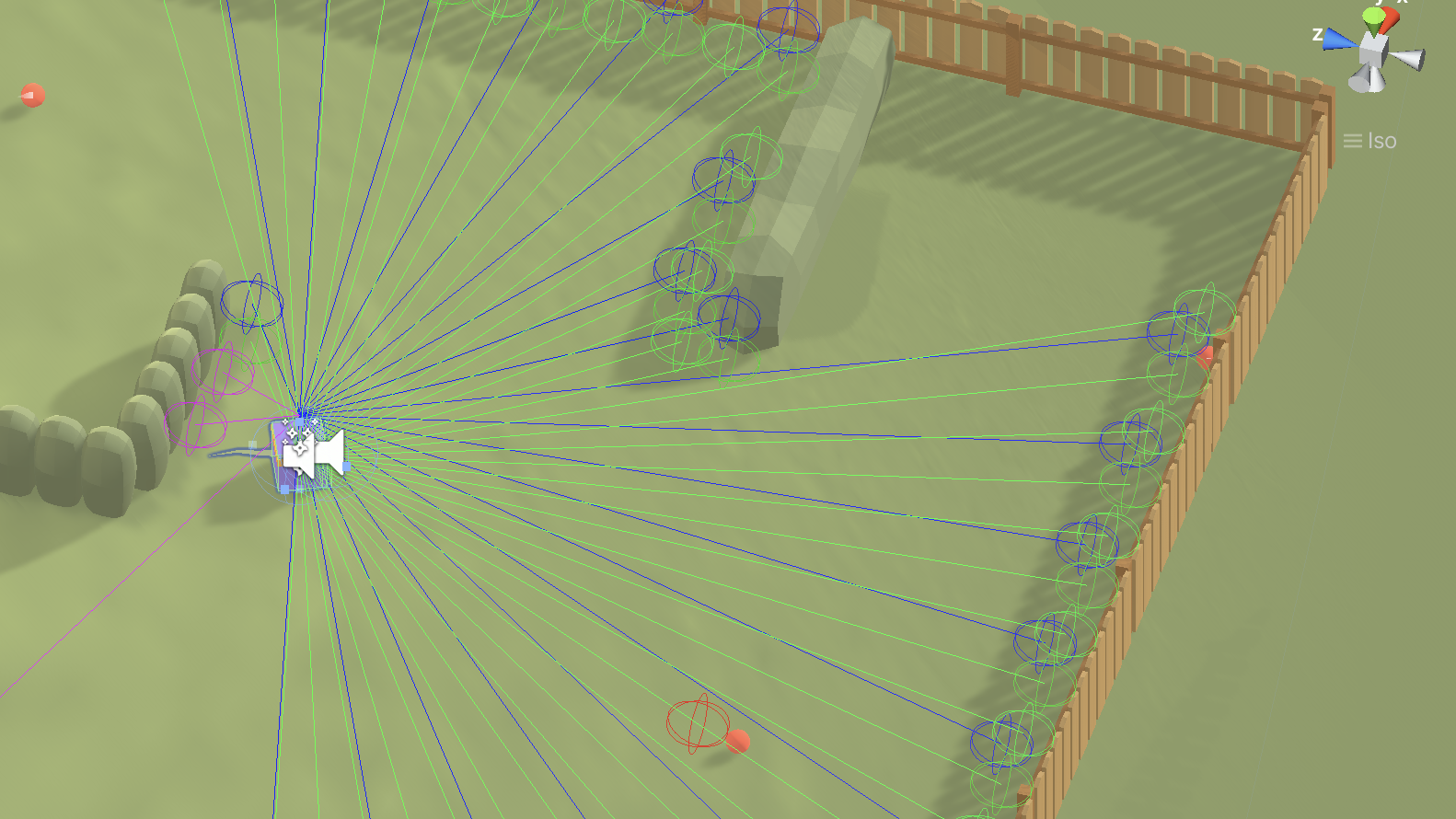
- 状態データ:エージェントの位置、現在持っているボールの数、アウトになるまでに受けられるボールの数、フラッグ戦モードで旗を持っているかどうかの情報などです。エージェントはこの情報をもとに戦略を練り、勝利の可能性を判断します。
- 他のエージェントの状態データ:この情報には、エージェントのチームメイトの位置や残りアウト数、旗を持っているエージェントがいるかどうかなどが含まれます。なお、エージェントの数は固定ではないため(エージェントはいつでもアウトになる)、エージェントに Buffer Sensor を使用して、可変数の観測データを処理しています。ここで、観測の数とは、ゲームに残っているチームメイトの数を指します。
DodgeBall 環境では、連続的な行動と離散的な行動が混在するハイブリッドな行動も使われています。エージェントは、移動のために 3 つの連続した行動を取ります。1 つは「前に進む」、もう 1 つは「横に進む」、そして最後は「回転する」です。同時に、2 つの離散的な行動があります。ボールを投げる動作と、ダッシュする動作です。この行動空間は、フラッグ戦とせん滅戦の両シナリオにおいて、人間のプレイヤーが取ることのできる行動に対応しています。
一方で、エージェントに与えられる報酬は、意図的に単純なものにしています。勝っても負けても大きな最終報酬を与え、ゲームのやり方を学んだことに対して、中くらいの報酬を与えます。
せん滅戦の場合の報酬は以下の通りです。
- エージェントは、相手にボールを当てると +0.1 の報酬が与えられます。
- チームは、ゲームに勝てば(相手をすべてアウトにすれば)+1、負ければ -1 の報酬が与えられます。
- 早く決着がついた場合、勝利チームにタイムボーナスとして、1 *(残り時間)/(最大時間)の報酬が与えられます。
フラッグ戦の場合の報酬は以下の通りです。
- エージェントは、相手にボールを当てると +0.02 の報酬が与えられます。
- 勝利した(相手の旗を自陣まで持ち帰った)チームには +2、敗北したチームには -1 の報酬が与えられます。
エージェントに小さな報酬をたくさん与えて目的の行動を取らせるアプローチは魅力的ですが、エージェントが追求すべき戦略を過剰に規定することは避けなければなりません。例えば、せん滅戦ルールでボールを拾うと報酬がもらえるようにしたら、エージェントは相手にボールを当てることよりもボールを拾うことに集中するようになるかもしれません。報酬を可能な限り「疎」にすることで、エージェントを学習させる時間は長くなるかもしれませんが、エージェントにゲームの中で独自の戦略を発見させる余裕を与えることができます。
エージェントが先に挙げた報酬を得るための戦略には非常に多くの種類があるため、最適な行動はどのようなものかを決定する必要がありました。例えば、ボールを貯めておくのがベストな戦略なのか、それとも後で便利に使えるように移動させておくのがベストな戦略なのか、チームとして団結するのが賢明なのか、それとも早く敵を見つけるために散らばる方が良いのか、といったことです。これらの質問に対する答えは、ゲームデザインの選択によって決まります。ボールが少ないなら、エージェントは敵にボールを奪われないようにボールを長く保持するようになるでしょう。また、エージェントが常に敵の居場所を知っているのであれば、できるだけ集団で行動するようになるでしょう。そのため、ゲームに変更を加える時に、AI にコードの変更を加える必要はありませんでした。新しい環境に適応するために、新しい振る舞いを再度学習させただけです。
エージェントに協調した行動を取らせる
単一のエージェントにタスクを解決するための学習をさせることに比べて、複数のエージェントに協調して動くように学習させるのはより複雑です。エージェントのグループを管理するのに役立つように、DodgeBallGameController.cs スクリプトを作成しました。このスクリプトは、プレイ空間の初期化とリセットを行います(ボールの配置とエージェントの位置のリセットが含まれます)。また、エージェントを SimpleMultiAgentGroup に割り当て、各グループが受け取る報酬を管理します。例えば、DodgeBallGameController.cs スクリプトでは、エージェントが他のエージェントにボールを当てる処理を行っています。

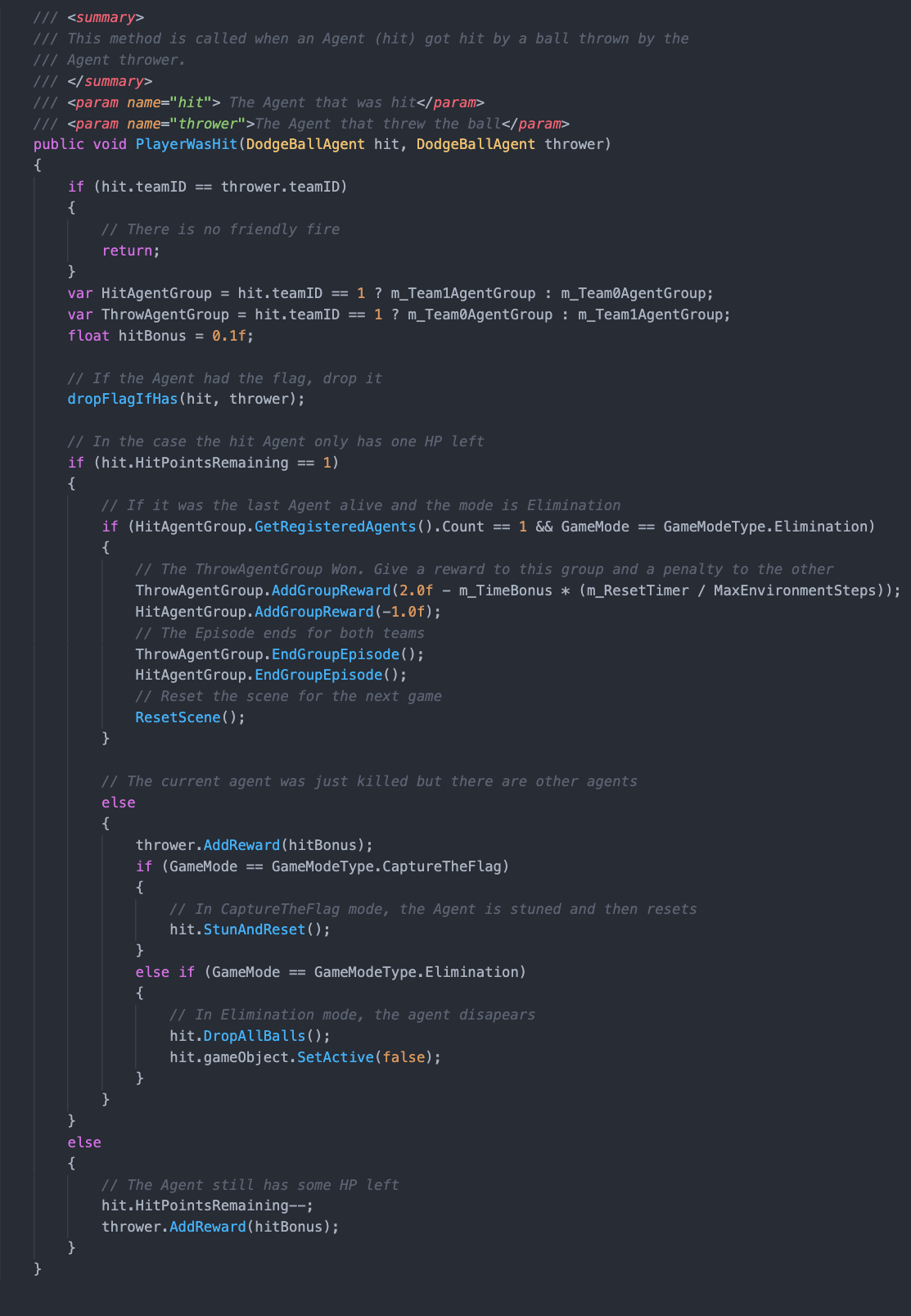
このコードでは、ボールを投げたエージェントが相手にボールを当てたときに小さな報酬を得るようになっていますが、最後の相手をアウトにして初めて、グループ全体で累積した分の報酬を得られるようになっています。
MA-POCA では、SimpleMultiAgentGroup の中のエージェントを、個別のエージェントとは異なる方法で処理します。MA-POCA は、その観測結果をプールして、中央集権的に学習を行います。また、グループへのエージェントの参加や離脱がどれだけあっても、個人への報酬に加えてグループ全体への報酬も扱うことができます。TensorBoard では、エージェントがグループとして受け取る累積的な報酬を監視することができます。
各要素を組み合わせる
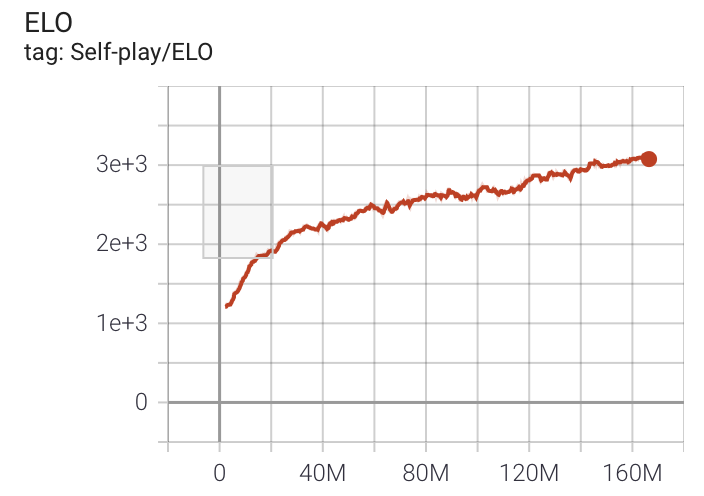
せん滅戦とフラッグ戦はどちらも敵対的なゲームなので、MA-POCA とセルフプレイを組み合わせて、エージェントを古いバージョンの自分と対戦させ、どうやったら勝てるかを学習させました。ML-Agents をセルフプレイを使って実行させるたびに、ELO が増加し続けているかどうかを確認すれば、エージェントの学習進捗を監視することができます。何千万回ものステップを経て、エージェントは人間と同じようにプレイすることができます。

この動画はエージェントがせん滅戦シナリオを学習する際に、時間経過とともにどのように学習を進んでいくかを示したものです。学習の初期段階でエージェントを相手にボールを投げることを覚えますが、狙いが甘く、でたらめに投げてしまっていることがわかります。4,000 万タイムステップを経てエージェントの狙いは改善されましたが、敵と出会うことを狙ってでたらめに動き回ってしまう問題を残しています。対戦相手と出会う時は、普通 1 対 1 のシチュエーションになっているものです。さらに 1 億 2,000 万タイムステップ学習させて、エージェントはより積極的な行動を自信を持って取るようになり、集団で敵地に突入するなど、高度な戦略を身につけていきます。
次に、フラッグ戦のプレイ方法を学習するエージェントの場合を示します。学習の初期段階である 1,400 万タイムステップの時点で、エージェントはお互いに向かってボールを投げ合うことを覚えますが、旗を取りに行こうとはしません。3,000 万タイムステップの段階では、敵の旗を取って自陣に戻る方法を学びますが、旗を持っているエージェント以外のエージェントがどのようにチームに貢献しているかはわかりません。しかし、8,000 万タイムステップの段階で、エージェントは興味深い戦略を示します。
敵の旗を持っていないエージェントは、自分の基地を守ったり、自分の旗を持っている敵を追いかけたり、敵の陣地で旗を持っている相手が戻ってくるのを待ち、戻ってきた相手をボールで攻撃したりするようになります。自チームに旗を取ったメンバーがいれば、そのチームメイトが旗を持って帰ってくるまで自陣で待機して、得点できるようにすることもあります。下の動画では、エージェントが自発的に学習した興味深い戦略の一部を紹介しています。これらの動作は、人間が明示的に指定したわけではなく、エージェントが何百回もセルフプレイを繰り返しているうちに学習したものです。
次のステップ
DodgeBall 環境はオープンソースです。こちらのレポジトリからダウンロードできます。ぜひ試してみてください。 機械学習とゲームが融合するこのエキサイティングな分野で働いてみたいとお考えの方は、いくつかのポジションで採用を行っておりますので、ご応募をご検討ください。ご応募はこちらのサイトから行っていただけます。
皆様からのフィードバックをお待ちしております。Unity ML-Agents ツールキットに関するご意見・ご感想は、こちらのアンケートフォームからご送信いただくか、直接 ml-agents@unity3d.com までメールでお寄せください。何か問題が発生した場合は、遠慮なく ML-Agents の GitHub issues ページにご投稿ください。その他、一般的なコメントや質問については、Unity ML-Agents のフォーラムでお知らせください。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies