2020 年の AI@Unity インターン報告





毎年夏、AI@Unity ではインターンを迎え、人工知能と機械学習のツールやサービスを使って Unity の開発者に力を与えるという私たちのミッションを遂行するための、インパクトのある技術の開発に参加してもらっています。今年の夏も例外ではなく、AI@Unity グループは 24 名の素晴らしいインターン生を迎えることができました。この記事では、ML-Agents チームと Game Simulation チームに参加して、研究とエンジニアリングに取り組んだ 7 人のインターン生を紹介します。Yanchao Sun、Scott Jordan、PSankalp Patro、Aryan Mann、Christina Guan、Emma Park、Chingiz Mardanov(敬称略)です。この記事の続きにぜひ目を通していただき、7 人の Unity でのインターンの経験と成果に触れてください。
2020 年の夏を通して、AI@Unity の組織には合計 24 人のインターン生が在籍しましたが、この記事ではそのうちの 7 つのプロジェクトの概要をご紹介します。特に注目すべきこととして、7 つのプロジェクトがすべて実験的な性質のものであり、Unity の製品やサービスの限界を押し広げるのに役立ったことです。以下に挙げた 7 つのプロジェクトの成果はすべて、ユーザーに役立ててもらうための重要な機能として、今後数か月のうちにコア製品に何らかの形で寄与する見込みです。
このブログ記事でプロジェクトの概要を紹介している 7 人のインターンは、ML-Agents と Game Simulation のチームに所属して活動しました。
- ML-Agents チームは、オープンソースプロジェクトである ML-Agents ツールキットの開発と保守を行う応用研究チームです。ML-Agents ツールキットを使用すると、Unity のゲームやシミュレーションを機械学習アルゴリズムのトレーニング環境として利用することができます。開発者は ML-Agents を使用して、深層強化学習(RL)や模倣学習(IL)を用いてキャラクターの行動やゲーム AI をトレーニングします。これにより、従来の手作業やハードコード化された手法のような面倒な作業を回避することができます。ML-Agents については、GitHub のドキュメントのほか、こちらのブログ記事や研究論文で詳しく知ることができます。
- Game Simulation チームは、ゲーム開発者がクラウド上で複数のプレイスルーを並行して実行することで、ゲームのテストとバランスを取れるようにすることを使命とするプロダクトチームです。Game Simulation は今年の早い時期にローンチしました。パートナーである iLLOGIKA と Furyion の協力を得て公開したケーススタディをご覧になることで、より詳細な情報を得ることができます。
Unity の成長に伴い、インターンシッププログラムも大きくなっています。2021 年には、AI@Unity のインターンシッププログラムは採用するポジションの数を 28 に増やす予定です。さらに、オーランド、サンフランシスコ、コペンハーゲン、バンクーバー、ヴィリニュスなど、より多くの地域で、ソフトウェア開発から機械学習研究までのポジションを募集しています。2021 年のインターンシッププログラムに興味のある方は、こちらにご応募ください。それでは、2020 年の夏に活動した、優秀なインターン生の様々なプロジェクトの成果をご覧ください!
Yanchao Sun(ML-Agents):転移学習
ほとんどの場合、RL で学習された振る舞いは、トレーニングされた環境ではうまく働きますが、似ていても少し異なる環境ではほとんど使い物にならなくなります。その結果、ゲームのダイナミクスに単純な微調整を加えただけで、以前のポリシーを破棄して、すべてをゼロから訓練する必要が出てきます。2020 年の夏を通して、私はゲーム開発のインクリメンタルなプロセスに特化した新しい転送学習アルゴリズムを開発しました。
課題:ゲーム開発はインクリメンタルだが、RL はインクリメンタルではない
ゲーム開発はインクリメンタルなものです。通常、ゲームの開発は簡単なプロトタイプから始まり、徐々に複雑さを増していきます。しかし、RL はインクリメンタルではなく、ポリシーのトレーニングには時間がかかります。ゲーム開発に ML-Agents を使用すると、開発者が RL エージェントが修正にどのように反応するかを確認するために数時間、場合によっては数日待たなければならないため、コストが高くなる可能性があります。いくつかのアプローチでは、トレーニングのプロセスにおいてポリシーをより一般的なものにすることができますが、例えば、ドメインのランダム化は、トレーニング前に指定できるゲームのバリエーションにのみ適用することができるもので、将来のあらゆるゲームの進化に適応することはできません。
解法:表現と予測を切り離す
直感的には、ゲームのダイナミクスやエージェントがゲームとどのように相互作用するかを微調整しただけでは、ゲームの残りの部分はほとんど変更されません。例えば、エージェントに解像度の高い優れたセンサーを与えても、世界をどのように観察するかは変わりますが、世界がどのように動くかは変わりません。この洞察に基づき、私たちは、環境の次のイテレーションに転移できる、潜在的な環境の特徴量を抽出する新しい転移学習アプローチを編み出しました。転移学習アルゴリズムは、1 つの問題を解く際に得られた知識を利用して、別の関連する問題の学習を容易にします。問題の変更されていない側面の知識を転移させることで、新しいドメインでの学習速度を大幅に向上させることができます。
私たちの研究では、エージェントの観測の表現と環境のダイナミクスの表現を分離するモデルを提案しています。そのため、観測空間が変化してもダイナミクスが変化しない場合には、ダイナミクスの表現を再度読み込んで固定します。同様に、ダイナミクスは変化するが観測空間が変化しないときには、エンコーダーを再読み込みして固定します。どちらのシナリオにおいても、転移されたピースはモデルの他の部分を正則化させるものとして機能します。

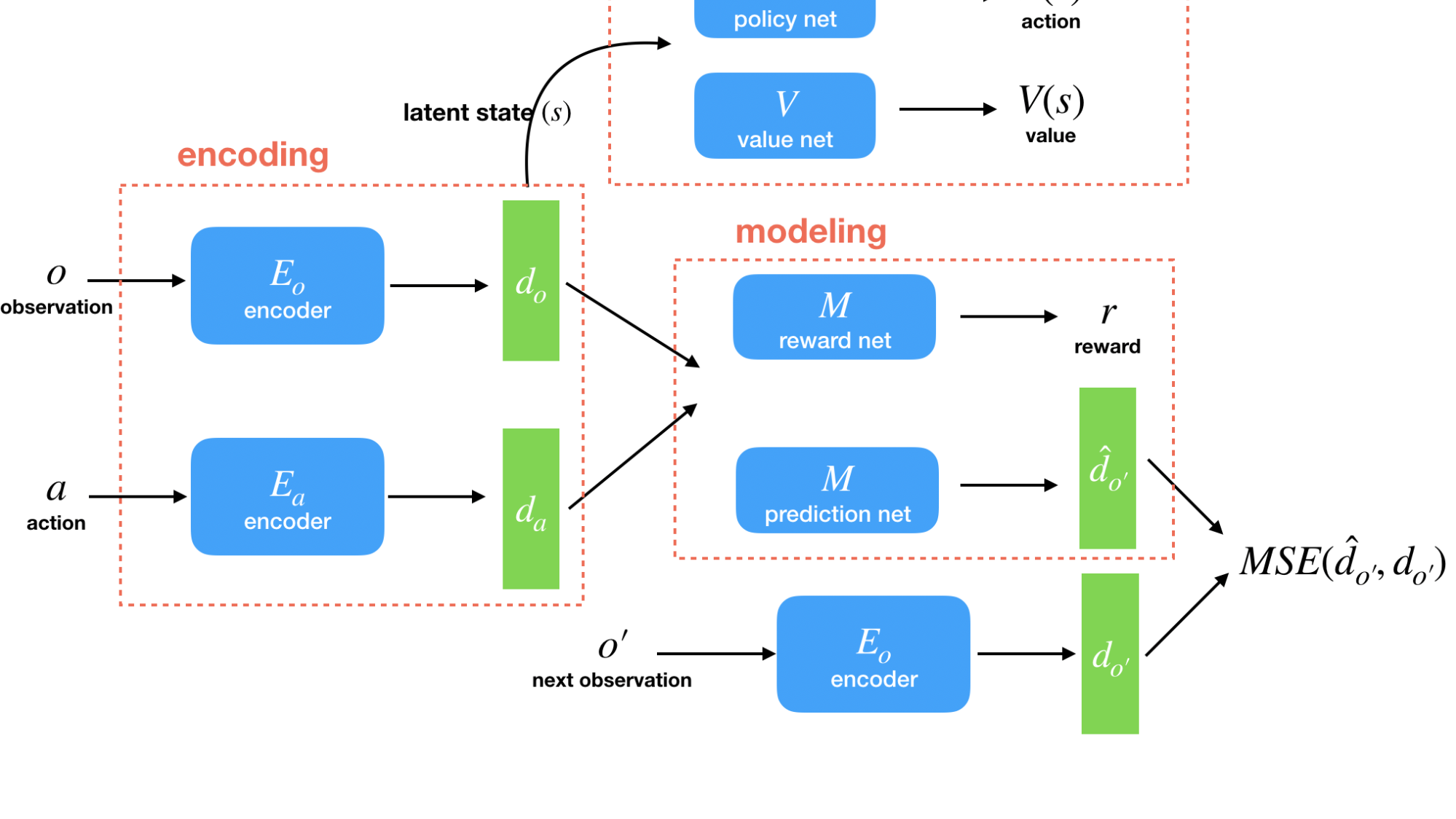
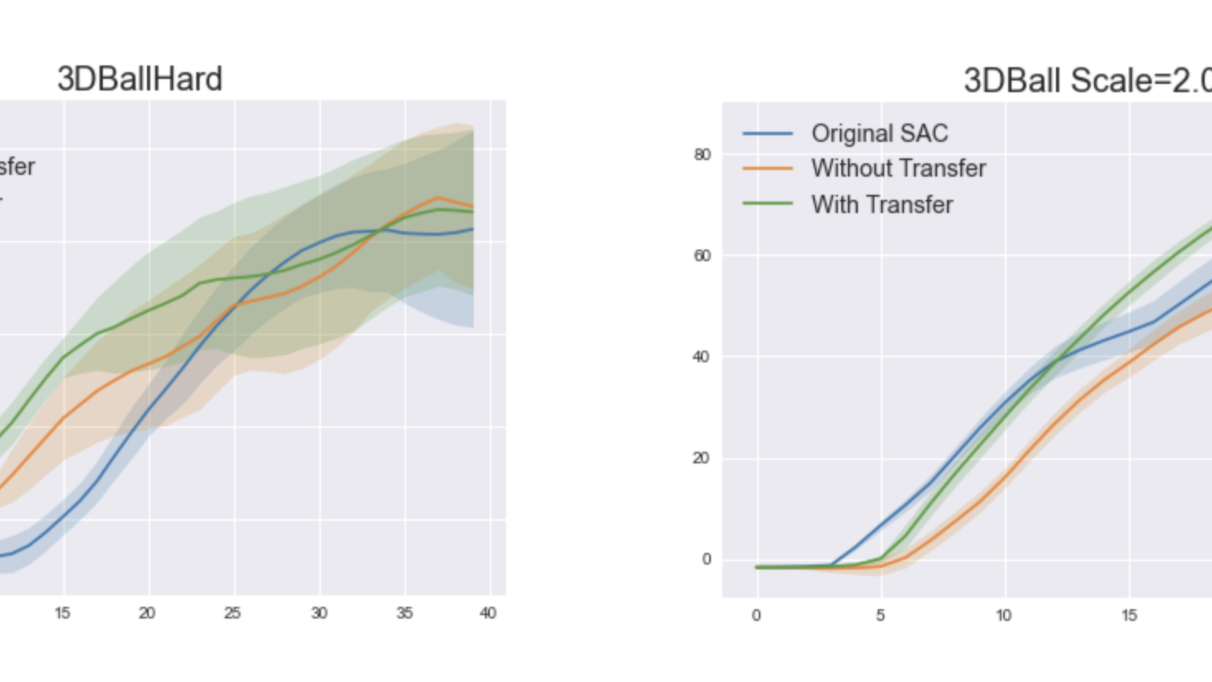
私たちの手法(ML-Agents の将来のバージョンで利用可能になる予定)のテストには、ML-Agents ツールキットの 3DBall と 3DBallHard 環境を選択しました。これらの環境は、ダイナミクスは同じですが、観測空間が異なります。また、エージェントの行動の大きさにペナルティを加えました。エージェントの目標は、最小限のエネルギー消費でボールのバランスをとることです。観測の変化をテストするために、まず 3DBall 上でモデルベースのポリシーを学習し、モデル化部分を 3DBallHard の学習に転移させました。その結果、標準的な Soft Actor-Critic アルゴリズムとシングルタスクモデルベースの学習システムと比較して、転移を使って学習を行う方法が最も高い報酬を得られることがわかりました。また、ボールの大きさを大きくして動的に変化させた場合の評価も行いました。その結果、転移学習はシングルタスク学習システムを上回り、より高い安定性を得られることがわかりました。

Scott Jordan(ML-Agents):タスクのパラメーター化と能動学習
RL の設定では、開発者は、特定の結果の望ましさを示す値を返すスカラー関数である報酬関数を定義することで、望ましい動作を指定します。報酬関数を明示することは難しく、開発者の意図を汲み取るように調整する必要があります。このような試行錯誤のワークフローは、RL がデータを要求するために、非常にコストがかかることがあります。このインターンシップでは、タスクのパラメーター化と能動学習アルゴリズムを用いて、このプロセスを改善する方法を検討しました。
課題:報酬関数のチューニングが必須
与えられた場所への移動というタスクをこなすエージェントを考えてみましょう。エージェントは、おそらく、目標とする場所まで可能な限り速く走ることを学習するでしょう。開発者にとって、この学習された行動は望ましくないものかもしれませんし、ゲームのシナリオで人間が競うことが難しすぎるエージェントになってしまうかもしれません。そこで、開発者は、エージェントの動きが速すぎるとペナルティを与えるように報酬関数を修正します。次に、開発者は、新しい報酬関数を使用してエージェントを再度トレーニングし、学習された行動を観察します。このプロセスは、ゲーム開発者が満足するまで繰り返されます。この反復プロセスは、エージェントのタスクが複雑になると、法外なコストがかかる可能性があります。
解法:タスク間の分布を解決することを学習させる
正確に正しい目的を指定する必要性を軽減するために、エージェントの目的関数のパラメーター化されたタスクの定義を使用します。この設定では、エージェントのタスクは、調整可能であるか、またはサンプリング可能ないくつかのパラメーターを持ちます。前の段落の例を使用すると、エージェントのタスクは目標の場所に移動することであり、 エージェントがこれを行う速度はパラメーターです。したがって、開発者は、学習すべき単一の動作を指定する代わりに、例えば、速度を変えながら目標の場所に向かって移動するなど、ある程度動作に幅を持たせて指定することになります。そして、学習後、タスクのパラメーターを調整して、目的の動作を最適な形で反映させることができます。ML-Agent ツールキットには、現在、速度を変化させて走行するというタスクを実行する、Walker エージェントのインスタンスが含まれています。さらに、速度を可変としたバージョンの Puppo も作成しました。これは、Puppo が物を取ってくる遊びをしている間にどれだけ速く走るかを伝えるもので、Puppo が後ろ足で飛び跳ねるようにトレーニングするための頭の高さのパラメータを与えます。
パラメーター化されたタスクは複数の行動を学習するのに便利ですが、どのパラメーター化をトレーニングに使うべきかという問題は自明なものではありません。ナイーブなアプローチはパラメーター化をランダムにサンプリングすることですが、これはいくつかの理由から非効率的です。そこで私たちは、能動学習のよりスマートな代替手法(Da Silva et al. 2014)を採用しました。能動学習は、トレーニング中にエージェントの改善の期待値を最大化するために、どのパラメーター化でトレーニングするかを学習する手法です。これにより、エージェントはより少ないサンプルですべてのタスクのパラメーター化を学習することができます。前述の頭の高さと複数の速度のパラメーターを持つ Puppo の例では、以下に示されるように、タスクのパラメーター化の一様ランダムサンプリングと能動学習を比較しています。


PSankalp Patro(ML-Agents):モデル出力の追跡
強化学習では、一般的なユーザがノートパソコンやデスクトップで利用できる計算リソースをはるかに超えるような重い計算リソースが必要とされます。ML-Agents チームは、ユーザーがより簡単にトレーニングを行えるように、ML-Agents の実験的なクラウドトレーニングサービスである ML-Agents Cloud を開発しています(Release 1 のブログ記事で発表しています)。
ML-Agents Cloud は、ユーザにいくつかの利点を提供します。開発者は、ローカルコンピューター上で単一の実験を行うのではなく、複数の実験を並行して実行できるようになりました。優れた計算能力により、トレーニングにかかる時間が短縮され、複雑な環境でも短時間で学習できるようになります。また、ML-Agents Cloud は、ML-Agents のトレーニングを実行するために必要な機械学習ライブラリやバージョン管理(Tensorflow や PyTorch など)のインストールやセットアップを不要にします。
課題:実験で生成されたモデルの追跡や提供をする方法がない
今回のインターンシップに参加する前は、ML-Agents Cloud には、実験で生成されたモデルをユーザーが扱うためのオプションがありませんでした。強化学習の実験は何時間もかかることがあるので、最終モデルの他にチェックポイントとなる中間モデルを生成するのは当然のことです。チェックポイントとして作ったモデルは、モデルの学習進捗状況を記録したり、特定のポイントから学習を再開したりするために使用することができます。トレーニング済みモデルは ML-Agents からの最も重要な出力であるため、ユーザーが自分のモデルを見たり追跡したりするための良い方法を提供したいと考えました。
解放:モデルの追跡と提供を行うバックエンドを構築する
この問題を解決するために、私は ML-Agents Cloud でトレーニングされたモデルファイルの追跡と提供を行うためのバックエンドを構築することにしました。これには以下が含まれます。
- ファイル追跡:モデルが生成されたトレーニングステップやエージェントの最近の報酬値の平均など、生成されたモデルに関するメタデータを収集しました。トレーニングの最後に、モデルのメタデータはデータベースに保存され、ユーザーがモデルの出力を簡単にソートしてフィルタリングできるように、実験に関連付けられます。
- API と CLI:次に、ML-Agents Cloud の API とコマンドラインインターフェースを拡張して、クラウドに保存されたモデルと対話するためのインターフェースを作成しました。
- ML-Agents Cloud の Unity エディターへの統合のプロトタイプ:前述のコンポーネントを用いて、ML-Agents Cloud と Unity エディターを統合するためのプロトタイプを作成しました。このコンポーネントの目的は、ML-Agents Cloud と Unity エディターを一貫した形で統合し、Unity エディターを RL トレーニングをワンストップで行える環境にできる可能性を提示することでした。さらに、このコンポーネントは、ML-Agents Cloud でシームレスなクラウド上でのトレーニングを実現し、ほとんどすべての設定のオーバーヘッドを排除することができることを示す概念実証となりました。
Aryan Mann(Game Simulation):ゲームのシミュレーションとプロシージャルなコンテンツ生成
やりがいのある、エキサイティングで多様なゲームプレイを生み出す仕組みの 1 つに、プロシージャルなコンテンツ生成を活用するものがあります。プロシージャルなコンテンツ生成システムの中核をなすのがプロシージャルな生成器です。これは、ランダムシードを使用して一連の出力を生成する機能です。ある入力の構成に対して、すべてのシードから生成されたすべてのワールドの集合が、その構成の生成空間となります。1 つ以上の入力を変更して構成を変更すると、異なるワールドの集合が作成され、その結果、異なる生成空間が作成されます。
課題:プロシージャルなコンテンツの QA が困難であること
プロシージャルな機能の大きな問題点の 1 つは、品質保証です。大量のコンテンツを生成することの欠点は、プレイテストが途方もなく困難になることです。生成されたコンテンツの品質やバランスを評価する技術はありますが、現在の技術のほとんどはエージェントに依存しないものです。つまり、ステージの大きさや敵の数、ドアの数など、レベル内の具体的な項目を測定しています。この方法には限界があり、プレイヤーが特定のシード(によって生成されたコンテンツ)にどのように触れるかについて、結論を出すことができません。
解法:ゲームをプレイするスマートなエージェントを使ったテスト
私たちが達成したいのは、エージェント間で完全な相互依存性が実現されている状況です。これには、プロシージャルな生成器の表現する範囲内であれば、どのようなステージでもプレイできるエージェントが必要です。そのようなエージェントがあれば、ステージのバランスや品質を測定することができます。クリア時間、難易度あるいは実現不可能性といったメトリクスの測定は、エージェントのプレイを通じて行うことができます。これにより、ゲームバランスの調整は数学的モデルの問題からブラックボックス関数としてゲームを実行することに変わります。この関数を測定するために、Unity Game Simulation のようなツールを使って、生成されたコンテンツのより大きく、より良くコンテンツを代表しているサブセットをシミュレートされた多数のプレイヤーに探索させることができます。この理論を証明するために、ML-Agents の Obstacle Tower 環境をプレイするシンプルなボットをトレーニングしました。Obstacle Tower はプロシージャルに生成された難易度の高い塔の環境で、昨年実施された深層強化学習コンテストのベンチマーク環境として使われました。
「Obstacle Tower」のケーススタディ

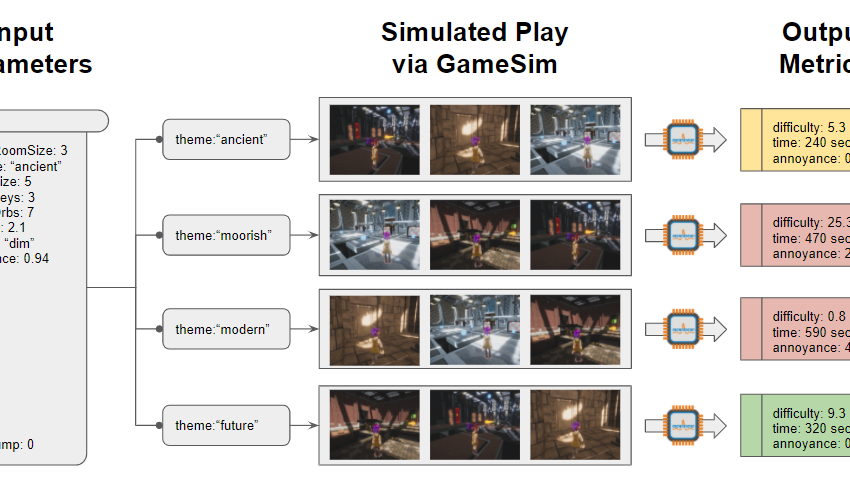
最初に考察するべき問題は、エージェントを訓練している間に、障害物を生成する入力パラメーターの種類と範囲をピンポイントで特定することが可能かどうか、それによってエージェントにあわせてプロシージャルに生成されたタワーのバランスをとることができるかということでした。Obstacle Tower には、柱、ドア、床など、ステージを構成するオブジェクトのスタイルとタイプを規定する 5 つの異なるテーマがあります。Unity Game Simulation を使用して、5 つの異なる外観のテーマすべてに対して、共通のステージ(シード)のセット上でのシミュレーションを実行し、生成されたメトリクスを相互に比較しました。これらには、最大パフォーマンスとエージェントの位置のホットスポットを示す分布が含まれます。モダンなテーマはパフォーマンスが悪く、ステージのドアの前に奇妙なホットスポットがありました。調査の結果、ドアの矢印記号が誤って反転していたことが、エージェントの進行を妨げる障害物となっていることを見出しました。合成データに基づいてコンテンツを測定することはなかなか難しい提案ですが、非常に価値のある提案だと感じています。サンプル環境に関すること、および Game Simulation でコンテンツを測定するためのテクニックについては、今後もブログで紹介していきます。
Christina Guan(Game Simulation):ゲームテストのためのシンプルなボット
Game Simulation を使用するための手順の 1 つに、テストしたいゲームやステージをプレイできるボットを作成するというものがあります。ゲーム AI を作成するためのツールはいくつか存在しており、そうしたツールは自然な形で拡張して、ゲームをプレイできるボットを作成するツールとすることができます。
課題:ボットの作成
今回のインターンシッププロジェクトでは、開発者が Game Simulation 上でゲームをテストするために使用できるシンプルなボットを作成するための Unity ツールについて実験したいと考えていました。これが使えるようになれば、Unity の新しい入力システムとシームレスに動作する Unity ネイティブのソリューションを提供することができます。新しい入力システムは、従来の入力システムよりもはるかに高い拡張性とカスタマイズ性を持つように設計されています。ユーザーはスクリプトに大きな変更を加えることなく、特定のアクションを迅速かつ簡単に複数のコントローラタイプにバインドすることができるようになり、ゲームをさまざまなプラットフォームやデバイスに対応させやすくなりました。また、コードから簡単に駆動させたり、追跡およびハンドルできるイベントで扱えたりできるという利点もあります。開発者にとっては、シンプルでありながら有用なボットをゲームのために構築するためのツールとなります。
解法:入力システムのボット
インターンシップの間、私は入力システムパッケージを使用する 2 つの別々のボットを作り、これを「monkey」と「replay」と名付けました。これらのボットは QA とバグテストを念頭に置いて設計しました。monkey ボットは、大量のランダムな入力の多様な組み合わせを連続的にテストすることができるものです。これは入力のエッジケーステストに役立ちます。replay ボットは、さまざまな QA テストの内容を記録して再生することにおいて特に有用に使うことができ、人間のテスターを同じテストを繰り返す作業から解放して、他の作業に集中できるようにするものです。さらに、どちらのボットも特定のゲームコードへ依存しないように設計されており、開発者が必要に応じてパーツを追加したり修正したりできるように構成されています。
monkey ボットは、開発者がコードを通して入力システムを駆動することで、入力コントロールをテストできるようにします。開発者はテストしたい入力を指定することができ、monkey ボットはそれらの入力のランダムなシーケンスを生成します。開発者は monkey ボットを使って、1 つの入力だけをテストすることもできますし、複数の入力を同時にテストすることもできます。
replay ボットは、開発者が一連の入力を記録して再生することを可能にします。このボットは、入力がトリガーされると入力システムからイベントトレースをキャッチし、ゲームに影響を与える入力とそれらのイベントを照合します。ボットは、入力とタイムスタンプのリストを作成し、JSON オブジェクトに格納します。JSON オブジェクトは、ボットを通してそのまま修正したり、再生したりすることができます。現在、このボットはキーボード入力デバイスのみに対応しています。
私の夏のインターンシップの目的に照らして、これらのボットは新しい入力システムの機能について考察し、私がその機能をより深く理解するために役立ちました。その上で、ゲームチームのテスト負担を軽減するためのすぐに使えるソリューションとして、これらのボットをどのように使用できるかの概念実証を構築しました。
Emma Park(Game Simulation):Virtual Player Manager でゲームを最適化する
ゲームテストは、ゲーム開発プロセスの中でゲームの品質を向上させる上で重要な役割を果たしています。しかし、そのためには反復的で時間のかかる手作業が必要で、開発者は別々のコードブランチを管理したり、さまざまなプレイヤーがテストを行うたびにコードのアーキテクチャを変更したりする必要があります。この問題を解決するために、私の夏のインターンプロジェクト「Virtual Player Manager」では、ゲームを調整するための貴重な情報を提供できるワークフローを確立するためにゲーム開発者を支援することを目的としました。この文脈における「バーチャルプレイヤー」とは、ゲームのテストや最適化に使用できるボットや自動化されたプレイヤースクリプトのことを指します。Virtual Player Manager は、大きく 2 つの機能で構成されています:バーチャルプレイヤーの管理と、さまざまなプレイヤーのシミュレーションです。
課題:ゲームでバーチャルプレイヤーを管理することが難しい
現在のところ、ゲーム開発者が Unity プロジェクトでバーチャルプレイヤーを管理するための構造化された方法はありません。ゲーム開発者は、管理を容易にするためにスクリプトを異なるカテゴリに整理したり、プレイヤー間のパフォーマンスを測定するためにゲームをプレイしたりするために、かなりの時間を費やしています。このプロセスは、バーチャルプレイヤーを使って複数のテストを実行することを難しくしています。
解法:ゲーム開発者がバーチャルプレイヤーを使ったシミュレーションを管理、実行できるインターフェースを提供する
バーチャルプレイヤーマネージャーは、すべてのプレイヤースクリプトを管理し、バーチャルプレイヤーを使って複数のシミュレーションを実行するためのクリーンで構造化された方法を提供します。
Unity エディターの Virtual Player Manager の UI コンポーネント
Unity エディターでは、Virtual Player Manager は UI コンポーネントを提供し、ゲーム開発者が簡単に複数のバーチャルプレイヤーを切り替えて、各バーチャルプレイヤーの挙動を観察できるようにしています。
下の動画のように、自分のプレイヤースクリプトを作成して、すべてのスクリプトを Virtual Player Manager にドラッグするだけです。別々のコードブランチを管理したり、プレイテストのたびに調整したりする必要はありません。

Game Simulation のダッシュボード内の Virtual Player Manager の UI
Game Simulation のダッシュボードでは、複数のプレイヤーのボットによる反復作業を管理しながら、様々な変化をシミュレーションすることができます。Unity Remote Config を活用して、シミュレーションごとに「バーチャルプレイヤーボットの設定」をクラウドから保存して、取得することができます。
シミュレーションが完了したら、プレイヤーログをダウンロードしてシミュレーション結果を分析したり、プレイヤー間でパフォーマンスを評価したりすることができます。
Chingiz Mardanov(Game Simulation):自動的なゲーム内パラメーターチューニングに関する考察
Unity Game Simulation チームの一員として、私はテストとゲームバランス調整の自動化を可能にするための仕事を手助けしました。現在、私たちのサービスでは、開発者が調整可能なゲーム内パラメーターに設定する値を選択し、作成された出力メトリクスを追跡しながら、可能なすべての組み合わせをクラウド上で実行することができます。
課題:望ましい結果を得るための最適なパラメーターを見つけることが困難であること
私たちは Game Simulation サービスの開発における次のステップを常に模索しています。そうした中で考えられるものの 1 つとして、開発者が望むゲームの振る舞いを実現するためのパラメーターの組み合わせを提案することで、開発者を支援するというものがあります。例えば、あるステージを必ず 3 分以内にクリアできるようにしたいとします。プレイヤーの移動速度はどのように設定すればよいでしょうか。この時間の目標を達成するために、ステージに敵を何体配置するべきでしょうか。
解法:ブラックボックス最適化
このような疑問に効率的に答えるために、ブラックボックス最適化を使用することができます。ブラックボックス最適化アルゴリズムが達成するべき主な目標は、可能な限り少ない評価回数で関数を最小化または最大化することです。ゲームを入力パラメーターの組み合わせを出力メトリクスにマッピングする関数と考えれば、ゲームの構成が希望のメトリクスからどれだけ離れているかに基づいてスコアを付け、この情報を最適化アルゴリズムに提供することができます。これにより、すべての可能性を試すよりもはるかに速く最適なパラメータの組み合わせを検索することができます。ブラックボックス最適化アルゴリズムを便利に使えるフレームワークはたくさんありますが、今回のインターンシップでは主に Google Vizier を使用しました。
多くの最適化アルゴリズムは、1 つの値を返す関数しかサポートしていません。つまり、ゲームが複数の出力メトリクスを追跡している場合、それぞれを個別に評価し、それらのスコアを 1 つの値に集約する必要があり、集約ステップの後にバイアスが生じる可能性があります。メトリクスとスコアリング関数の規模によっては、いくつかのメトリクスの影響が大きくなりすぎてその他のメトリクスの影響が無視されてしまい、予期しない結果につながる可能性があります。
私の仕事の 1 つは、スコアリング関数を解析し、最適化へのこのようなバイアスの影響を最小限に抑えることでした。そのために、私は多くの関数を設計してテストし、さまざまなデータセットでの挙動を観察しました。最良のスコアリング関数は、目的の領域に徐々に近づいていき、特定のメトリックに偏らないようになりました。


その後、私は動的な正規化アプローチの実験も行いました。これはもう少し複雑ですが、素晴らしい結果が得られました。

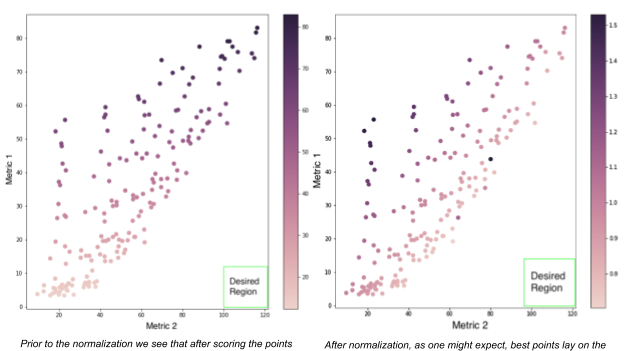
ゲームのビルドについては、Vizier フレームワークを使用したことで、メトリクスを所望の範囲に収めるために必要なパラメーターの組み合わせの実行数は、ランダム検索と比較して 65% 削減され、網羅的なグリッド検索と比較して 81% 削減されました。また、この性能の差はパラメーター空間の大きさに応じて大きくなる傾向があり、複雑なゲームの効率的な探索が期待できることがわかりました。この実験の結果、ターゲットとする複数のメトリクスからのバイアスを最小化するパラメーターの組み合わせを Vizier が選択するのに役立つスコアリング関数を特定しました。また、将来的には、より堅牢なサービスの設計に役立つと思われる、基礎的な Vizier アルゴリズムの特性を特定しました。
Unity の 2021 年のインターンシッププログラム
私たちが 2020 年の夏に迎えたインターン生は、ML-Agents と Game Simulation チームに加わってくれた素晴らしい仲間でした(その中には、来年フルタイムのチームメンバーとしてジョインしたり、別のインターンシップに参加したりする予定の方もいます)。2021 年の夏に向けて、私たちのインターンシッププログラムはさらに規模を拡大していく予定です。何百万人ものプレイヤーの体験に影響を与えるような意欲的なプロジェクトで働いてみたい方は、ぜひご応募ください。
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies