Machine Learning Agents Toolkit のゲームへの使用 ― ビギナーズガイド







こんにちは。Unity のテクニカルエバンジェリスト、Alessia Nigretti です。私の仕事は、Unity の新機能を開発者の皆様にご紹介することです。同じくエバンジェリストである Ciro Continisio と協力して、新しい Unity Machine Learning Agents Toolkit を使用した初めてのデモゲームを開発し、DevGamm Minsk 2017 で発表しました。本記事ではこの講演をベースに、デモの制作を通して私達が学んだ事をご紹介します。また、ML-Agents Challenge への参加を募集中です ― ぜひ本ツールキットのクリエイティブなユースケースをご発表ください。
昨年 9 月、機械学習チームによってMachine Learning Agents Toolkit が公開され、これに併せて 3 つのデモとブログ記事も公開されました。このニュースは、人工知能(AI)分野の技術的なエクスパートから、機械学習が私達の世界とゲームの開発形態・プレイ形態にもたらす変化に純粋に興味がある方々まで、非常に多くの開発者の注目を集めました。これを受け機械学習チームは最近、ML-Agents Toolkit の新しいベータ版(0.2)を公開し、Unity の機械学習エージェントに焦点を当てた初めてのコミュニティーチャレンジ企画を発表しました。
Ciro と私は機械学習のエキスパートではありません ― このことは、講演においても強調しました。Unity の基本的な理念のひとつはゲーム開発の民主化ですので、この新機能を試してみたい全ての方にご使用いただけるようしたいと私達は考えました。私達はまず、機械学習チームと協力し、この機能の根本的な仕組みを理解するために、いくつかの小さなデモを作成しました。私達はここで数々の疑問に直面しました ― そして、機械学習エージェントを初めて扱う開発者の方々もまた同じ疑問に直面するであろうと考えました。そこで私達は、これらの疑問を全てリストアップし、講演で取り上げました。本記事をお読みの皆様で機械学習やその機能する仕組みに馴染みのない方は、Unity Machine Learning Agents Toolkit の世界を通して理解することができるでしょう!
デモ『Machine Learning Roguelike』は、プレイヤーが賢くて獰猛なスライムと戦う 2D アクションゲームです。機械学習によって制御される敵は、プレイヤーを絶え間なく攻撃し、自らの命が危険にさらされたと判断すると逃亡します。
機械学習とは?
まずは、機械学習についてご説明しましょう。機械学習とは人工知能の応用であり、手作業で明確に設計された手順に沿ってではなくデータから自立的に学習できるシステムを提供するものです。これは、パターンを検知して未来の結果を予測するための材料となる情報と観測をシステムに供給することによって機能します。概して言うと、システムは入力―出力の適切なマッピングを学習する必要があります。それによってシステムは、最良の結果を得るために次に実行すべきアクションを選択できるようになります。
これを行う方法は複数あり、システムにどのような観測を供給できるかに応じて選択できます。この文脈で使用されているのは強化学習です。強化学習は「何を実行すべきかではなく、何が正しくて何が間違っているのみをシステムに教える」ことを基本とする学習方式です。つまり、システムにランダムなアクションを実行させ、それらのアクションが正しいと見なされれば報酬を、間違っていると見なされれば罰を与えます。そのうちにシステムは、正の報酬を得るためには特定のアクションを実行しなければならないことを理解します。これは、犬におすわりを教えるのに例えることができます。犬は私達の意図は理解しませんが、正しい行動を取った時にご褒美を与えれば、そのうちにその行動をご褒美と結び付けて理解します。

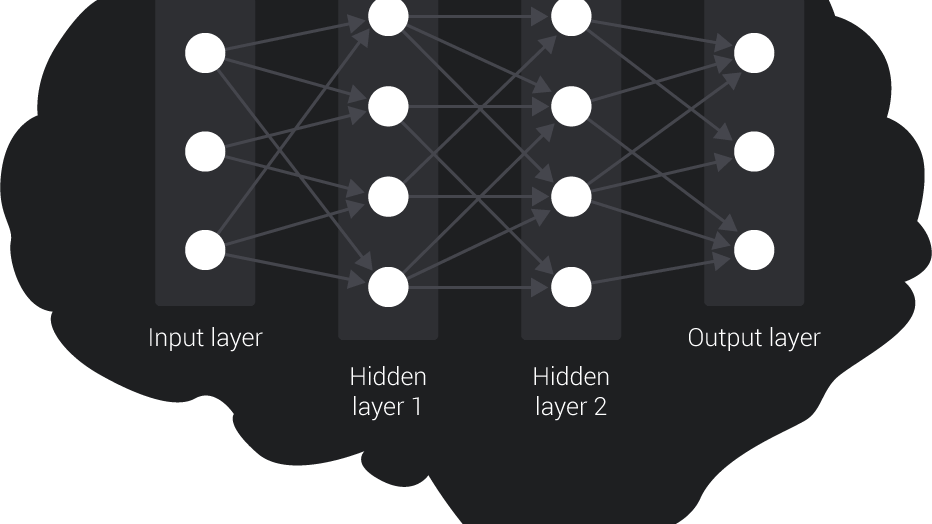
強化学習はニューラルネットワークのトレーニングに使用されます。ニューラルネットワークとは神経系をモデルにしたコンピューターシステムで、これはユニット(あるいは「ニューロン」)で構成されます。ニューロンは複数の層に分割できます。外部の環境とインタラクトして全ての入力情報を収集する層は「入力層」と呼ばれます。その逆である「出力層」には、ネットワーク内の特定の入力の結果に関する情報を格納する全てのニューロンが含まれています。入力層と出力層の間の層である「隠れ層」には、全ての計算を実行するニューロンが含まれています。これらが入力データの複雑で抽象化された表現を学習し、これによって最終的に出力が「知的」なものとなります。ほとんどの層は「完全に繋がって」います。つまり、ある層の中のニューロンは、直前の層の中の全てのニューロンと繋がっています。それぞれの繋がりは「ウェイト」で数値によって定義され、これによってニューロン間のリンクを強めたり弱めたりすることができます。
Unity における「エージェント」(学習を行うエンティティ)は強化学習モデルを使用しています。エージェントは環境に対してアクションを実行します。アクションは環境内に変化をもたらし、それが結果的に報酬または罰とともにエージェントにフィードバックされます。アクションは「Learning Environment(学習環境)」と呼ばれる環境内で起こります。これは実質的な意味においては通常の Unity のシーンに相当します。
Learning Environment 内には、トレーニングのプロパティー(フレームレート、タイムスケールなど)を定義するスクリプト「Academy」が 1 つあります。Academy はこれらのパラメーターを、トレーニングするモデルを含んだエンティティ「Brain」に渡します。最後にエージェントが Brainと接続され、そこからアクションが取得され情報がフィードバックされることで学習プロセスが促進されます。システムは、トレーニングを実行するために追加的なモジュールを使用します。このモジュールは、Brain が TensorFlow Machine Learning ライブラリを使用した外部の Python 環境と交信できるようにするものです。トレーニングが完了すると、この環境は、学習プロセスを「モデル」(Unity に再インポートされてトレーニング済み Brain として使用されるバイナリファイル)へと変換します。
機械学習を実際のゲームに使用する
私達は、単純なサンプル(『3D Ball』その他、私達が数時間で作成した小さなプロジェクト[GIF 画像参照])を触ってみて、この技術の可能性に魅了されました。
 |  |
 |  |
私達はこれを素晴らしい形で 2D ゲーム『Machine Learning Roguelike』に適用することができました。また、シーンを構築するために 2D Tilemap や Cinemachine 2D などの新機能も使用しました。
デモ『Machine Learning Roguelike』は「全てのエンティティが機械学習エージェントである簡単なアクションゲーム」として作成されました。こうすることで、プレイヤーとその遭遇する敵の両方が使用できる共通のインタラクション言語が確立されました。ゲームの目的は「動き回って敵との遭遇を生き残る」という非常に単純なものです。
トレーニングを設定する
全ての優れたトレーニングはトレーニングアルゴリズムに関する大まかなブレインストーミングから始まります。このアルゴリズムは各フレームをエージェントのクラスに対して実行するコードで、入力がエージェントに及ぼす影響と、それらがが生み出す報酬を決定します。私達はまず「ゲームの基本アクション(移動、攻撃、回復など)は何であるか」「各アクションの相互関係」「各アクションに関してエージェントに何を学習させたいか」「何に対して報酬と罰を与えるか」を定義することから始めました。
最初に決定しなければならないことのひとつは、状態とアクションに離散(Discrete)空間と連続(Continuous)空間のどちらを使用するかです。Discrete の場合、状態とアクションは一度にひとつの値しか持てません ― これは実際の環境の単純化されたバージョンなので、エージェントはアクションを報酬をより簡単に関連付けることができます。私達の例では Discrete アクションを使用しており、6 つの値(0=静止、1~4=一方向へ移動、5=攻撃)を持てるようにしています。Continuous の場合、同時に複数の状態やアクションが起こり得、その全てが浮動小数点値を持ちます。しかし、可変性によってエージェントが混乱する場合があるので、Continuous の使用は難易度が高くなります。『Machine Learning Roguelike』では、体力・ターゲット・ターゲットからの距離などの確認に Continuous の状態を使用しています。
報酬関数
私達が最初に思い付いたアルゴリズムは、エージェントが危険な状態になく、かつターゲットからの距離が減少している場合に、報酬を獲得させるというものでした。これに対し、危険な状態にある場合には、ターゲットからの距離が増加している(エージェントが「逃げている」)場合に報酬を獲得します。また、このアルゴリズムには、許可されていない時に攻撃した場合にエージェントに与えられる罰も含まれていました。


この最初のアルゴリズムは、連日にわたるテストを経て大幅に変わりました。私達は、目標の挙動を再現するための最良の方法は「試行、失敗、失敗からの学習、その繰り返し」という単純なパターンに従うことであると学びました。これは、提供した観測から機械に学習させようと試行錯誤を繰り返す私達自身と同じことです ― 私達もまた、トライアル・アンド・エラーによって得られる観測から学習することができます。例えば私達が気付いたことのひとつは、「エージェントは必ず報酬を搾取する方法を見付ける」ということです。私達のケースでは、エージェントは前進する度に報酬を獲得したため、前後に行ったり来たりし始めました。つまりエージェントは、報酬を最大限に得るためにアルゴリズムを利用する術を見い出したのです!
私達の学んだこと
私達は、適切なソリューションを求める研究を通して様々な事を学び、それらを最終的なプロジェクトにうまく取り入れることができました。ひとつ覚えておくべき重要なことは「報酬は、エージェントの行動が正しいと見なされる時にはゲームプレイのどの時点においても割り当てられる」ことです。
トレーニング用シーン

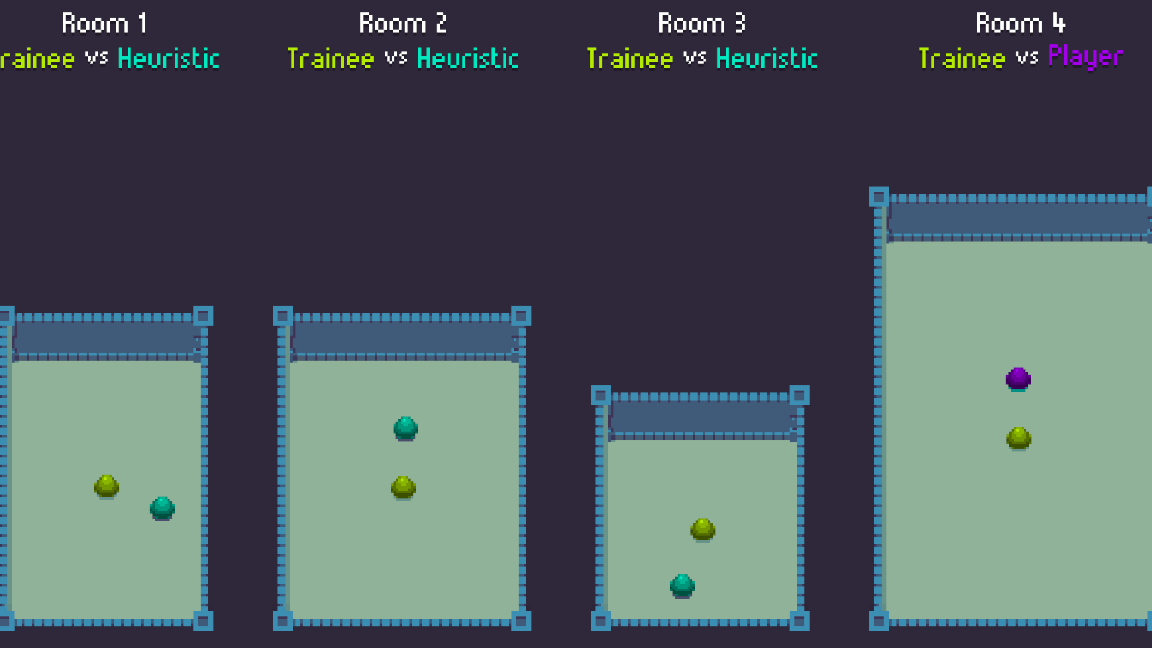
アルゴリズムの設定に続くステップは、トレーニングシーンの設定でした。私達は、トレーニング環境として機能する小さなシーンを設定した上で、別のより大きなシーンにトレーニング済みのモデルをエクスポートし、ゲームプレイでは後者のシーン内でエージェントを使用することにしました。エージェントが(特定のタイプの部屋に慣れてしまうことなく)考えられる全てのパターンを考慮するようにするために、長さと幅のパラメーターがそれぞれ異なる 4 つの部屋を作成することにしました。
トレーニング用シーンには、エージェントの位置、エージェントと Brain の繋がり、そして Academy とパラメーターを設定する役割があります。
私達の学んだこと
トレーニング用シーンの設定から私達が学んだのは「同じ状況を単純に何度も繰り返すのではなくトレーニングを並行させれば、エージェントが扱い学習できるデータの量が多くなるので、トレーニングの密度がより濃くなる」ということです。これを行う場合は、簡単なアクションを実行するヒューリスティックなエージェントをいくつか設定することで、エージェントに間違った理解を促すことなくその学習を促進することができます。例えば私達は、「ダメージを受けると何が起こるか」の例をエージェントに提供するために、簡単な Heuristic スクリプトを設定してエージェントがランダムに攻撃するようにしました。
環境の準備が完了すれば、トレーニングを起動できます。非常に長いトレーニングを起動する場合は、アルゴリズムのロジックに整合性があることを入念に確認することをお勧めします。これはコンパイル時間エラーの問題でも、あなたが有能なプログラマーかどうかという問題でもありません。前述の通り、エージェントはアルゴリズムを搾取する術を発見するので、ロジックに穴がないことを確実にしてください。さらに念のために、1 倍速のトレーニングを設定して各フレームで何が起こるか確認しましょう。エージェントが意図した通りに行動しているか観察してください。
トレーニング
トレーニングの準備が全て整ったら、Python 上で TensorFlow 環境とインタラクトするビルドを作成する必要があります。
まず、外部的に「External」としてトレーニングされるべき Brain を設定し、ゲームをビルドします。これが完了したら、Python 環境を開き、ハイパーパラメーターを設定してトレーニングを起動します。機械学習に関するReadme のページで、トレーニング用のビルド方法とハイパーパラメーターの選択方法をご確認いただけます。
トレーニングの実行中に、エージェントが獲得している報酬の平均値を観察できます。これはゆっくりと増加し、エージェントが学習を止めた時に安定するはずです。
目標のモデルが完成したら、それを Unity にインポートし戻して確認してみましょう。

この GIF 画像は 1 時間以内のトレーニングの結果を示しています。スライムは、私達が意図した通りに、別のエージェントに近付いて行って攻撃を続け、反撃されて体力の大部分を失うと、回復する時間を得るために敵から遠ざかり、再び攻撃するために敵に近付いて行きます。
テスト
このモデルを『Machine Learning Roguelike』に適用すると、同様に機能することが確認できます。スライムは、知的に行動し、自らがトレーニングされたものと異なるシナリオにも適応することを学習しました。
未来に向けて
本記事では、機械学習に関する技術的な知識のない方でも Unity の Machine Learning Agents API を使用することでどんな事が可能になるかをご紹介しました。上述のデモをご覧になりたい方は、エバンジェリズムチームの作成したレポジトリからご入手ください。
開発中のゲームに機械学習を実装するためにできることは、これ以外にも沢山あります。例えば、Trained と Heuristic を併用すること ― つまり、トレーニングで実現するには複雑過ぎる挙動をハードコード化しながらも、ML-Agents の使用によってゲームにリアリズムを与えることも可能です。
トレーニングの精度をより高くしたい場合は、クローズドベータ版あるいは内部プレイテストを通して得た、実際のプレイヤーのゲームスタイルやその戦略、目的に関する情報を取り入れることも可能です。こうしたデータを入手できれば、エージェントのトレーニングを洗練させて AI 複雑性を高めることができます。そしてさらに高みを目指したい方は、独自の機械学習モデルとアルゴリズムを構築することで、より高い柔軟性を実現することも可能です!
以上、ML-Agents の使い方をご紹介しました。ぜひ ML-Agents Challenge へ参加ください!
皆様のご応募をお待ちしています!
お勧めの参考文献
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies