ML-Agents Toolkit v0.2 ― カリキュラム学習、新しい環境、その他の改良







Unity の機械学習チームより、Unity Machine Learning Agents Toolkit – v0.2 ベータ版の新バージョンのリリースをお知らせします!このリリースでは、あらゆる面でツールキットを改良しました([1]Unity SDK と Python API の両方に新機能を追加[2]新しいサンプル環境(開発のベースとして使用可能)[3]デフォルトの強化学習アルゴリズム(PPO)の改良、多数のバグ修正、その他の小さな改良)。本記事では大きな追加要素のいくつかを取り上げますが、完全なリストは GitHub のリリースノートでご確認いただけます。また最新版リリースは GitHub のページからダウンロード可能となっています。
約 2 か月前に v0.1 ベータ版がリリースされて以来、すでに Unity ML-Agents Toolkit を使って作成された様々なプロジェクトやゲームを拝見させていただいているほか、コミュニティーの皆様から有用なフィードバックをお寄せいただいており、大変嬉しく思っております。本記事では、機械学習をはじめ様々な分野でさらにクリエイティブな ML-Agents Toolkit のユースケースをインスパイアするための 第一回 ML-Agents Community Challenge の開催発表もお届けします。
新しい連続制御環境とプラットフォーム環境
皆様から寄せられた主なご要望のひとつは、開発のベースとして使用できるサンプル環境のバラエティーを増やして欲しいというものでした。今回のリリースでは 4 つの新しい環境を追加しました。このうち 2 つは新しい連続制御環境、もう 2 つは(新しいカリキュラム学習機能の紹介用に設計された)プラットフォーム環境(後述します)です。
[youtube id="vRPJAefVYEQ"]
新機能 ― カリキュラム学習、ブロードキャスト、より柔軟なモニター
カリキュラム学習 ― Unity の Python API に、トレーニングのプロセスにカリキュラム学習を使用するための標準的な方法が追加されました。カリキュラム学習とは機械学習モデルのトレーニング方法のひとつで、(モデルに常に最適なレベルの課題が与えられるような形で)問題のより困難な面が徐々に提供されるというものです。こちらのリンクで、この概念を詳細に解説した元々の研究論文をお読みいただけます。一般的に言えば、この概念は、かなり以前からあったものです。なぜならこれは人間の一般的な学習プロセスだからです。皆様の子供の頃の小学校の教育を思い出してみてください。クラスや教科は順序付けられています。例えば、代数の前には算数が教えられます。同様に、代数は微積分学の前に教えられます。より早期の科目で学習された技術や知識が、後続のレッスンの足場となります。これと同じ原理が機械学習にも応用可能で、より簡単なタスクのトレーニングをもって、より困難な後のタスクの足場とすることができます。


強化学習が実際に機能する仕組みを考えてみると、主要な学習信号は、トレーニング中に随時受け取られるスカラー報酬です。より複雑あるいは困難なタスクでは、この報酬が疎になってほとんど獲得されないことが往々にしてあります。例えば、エージェントが「壁を越えてゴールに到達するためにブロックを押して適切な場所に配置しなければならない」タスクを考えてみましょう。このタスクを達成するようにエージェントをトレーニングするに当たっての開始点は、ランダムな方策です。開始時の方策では恐らくエージェントが同じところをぐるぐる回るような状態となり、壁を適切に越えて報酬を獲得することはほとんど起こり得ません。「障害物のない状態のゴールに向かって移動する」などの単純なタスクから開始すれば、エージェントは簡単にタスクの達成を学習することができます。そこから、最初は不可能に近かった「壁を越える」というタスクを達成できるようになるまで、徐々に壁のサイズを大きくすることでタスクの難易度を上げていきます。Unity ML-Agents Toolkit v0.2 に含まれる環境『Wall Area』で、これを実際にご覧いただけます。


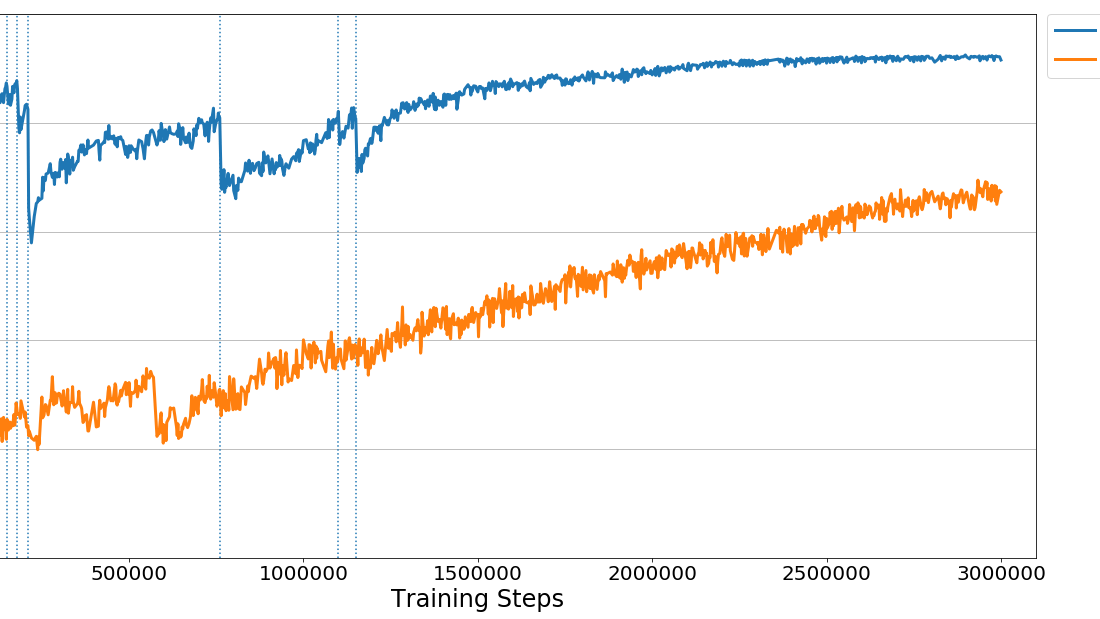
これを具体的にご覧いただけるのが、以下の 2 つの学習曲線です。それぞれの曲線は、32 体の同時エージェントから取得した同じトレーニングハイパーパラメーターとデータのセットを使用して PPO によってトレーニングされたブレインの累積報酬を示しています。オレンジ色の線は最大の高さの壁を使用したバージョンのタスクでトレーニングされたブレイン、ブルーの線はカリキュラムバージョンのタスクでトレーニングされたブレインです。ご覧の通り、カリキュラム学習を用いない場合では、エージェントは非常に苦心しており、3 百万ステップ後でもまだタスクを解決できていません。強化学習によるエージェントのトレーニングにおいては、精巧なカリキュラムを使用することで、元々は非常に困難なタスクも遥かに短時間で解決することができます。

では、これはどのような仕組みで機能しているのでしょうか。カリキュラムを定義する第一歩は、環境のどのパラメーターを変化させるかを決めることです。環境『Wall Area』の場合、変化するのは壁の高さです。これは、シーン内の Academy オブジェクト内でリセットパラメーターとして定義でき、これを行うことで、壁の高さを Python API で調整できるようになります。その上で(手動で調整するのではなく)カリキュラムの構造を記述した単純な JSON ファイルを作成します。このファイル内では、トレーニングプロセスのどの時点で壁の高さを変えるかを設定できます(これは、実行済みのトレーニングステップのパーセンテージに基づいて、あるいは、最近の過去にエージェントが受け取った報酬の平均に基づいて行われます)。これらの設定が完了したら、後は `–curriculum-file` フラグを、この JSON ファイルと、カリキュラム学習を使用してトレーニングする PPO にポイントして、ppo.py を起動するだけです。もちろん、現在のレッスンと進捗は TensorBoard でトラッキングできるようになります。
以下は、環境『Wall Area』のカリキュラムを定義する JSON ファイルの例です。
{
"measure" : "reward",
"thresholds" : [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5],
"min_lesson_length" : 2,
"signal_smoothing" : true,
"parameters" :
{
"min_wall_height" : [0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5],
"max_wall_height" : [1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0]
}
}コミュニティーの皆様で「環境を作成したが、エージェントが解決に苦心している」という方は、ぜひカリキュラム学習をお試しになり、ご意見をお聞かせください。
ブロードキャスト ― 内部ブレイン、ヒューリスティックブレイン、プレイヤーブレインの全てに「ブロードキャスト(Broadcast)」機能が追加されました。これはデフォルトでアクティブになっています。アクティブな場合、そのブレインにリンクされた全てのエージェントの状態・アクション・報酬が Python API からアクセス可能になります。これは、外部ブレインのみが Python API に情報を送信できる v0.1 とは対照的です。この機能は、これらのタイプのブレインからの情報を Python 上に記録・分析・格納するために使用できます。具体的に言うと、この機能によって模倣学習が可能になるということです(模倣学習では、プレイヤーブレイン、ヒューリスティックブレインまたは内部ブレインからのデータを、報酬機能を定義せずに別のネットワークをトレーニングするための管理信号として使用したり、トレーニング信号を強化するために報酬関数に追加することができます)。これは、ゲーム開発者が自らのシステムから知的挙動を引き出すに当たって、新しい手段を提供するでしょう。今後のブログ記事で、このシナリオのウォークスルーとサンプルプロジェクトをご提供します。


柔軟なモニター ― エージェントモニターを記述し直し、より一般的に使用できるようにしました。元々のモニターにはエージェントに関する固定の統計データセットが含まれており、それを表示することができましたが、新しいモニターでは、エージェントに関する任意の情報を表示できるようになりました。Monitor.Log() を呼び出すだけで、画面上またはシーン内のエージェントの上に情報を表示できます。


こちらはベータ版のリリースですので、恐らく一定のバグや問題が含まれています。GitHub の issues のページから、ぜひフィードバックをお寄せください。
Unity ML-Agents Community Challenge
最後に、Unity の開催する ML-Agents Community Challenge についてお知らせします。このチャレンジは、機械学習に詳しい方にも、ゲームへの機械学習の活用にただ興味があるという方にも、学習し、探求し、互いに刺激を与え合う素晴らしい機会となるでしょう。
この新しいカリキュラム学習のメソッドを皆様がどのようにお使いになられるか、拝見できるのを楽しみにしています。ジャンルやスタイルの制限はありませんので、自由にクリエイティビティーを発揮してください!最終的に最も多くの「いいね」を獲得したクリエイターの方々には、プレゼントとサプライズをご用意しています。
ML-Agents Challenge に参加する
第一回 Machine Learning Agents Challenge の応募期間は 2017 年 12 月 7 日~ 2018 年 1 月 31 日となっています。Unity の基礎的な知識と経験がある開発者の方ならどなたでもご参加いただけます。こちらをクリックしてチャレンジにご参加ください。 ML-Agents の仕組みについてお知りになりたい方は、メールまたは Unity Machine Learning チャンネルよりお気軽にお問い合わせください。
楽しい創作を!
[お勧めの参考文献]
Introducing: Unity Machine Learning Agents Toolkit
Using Machine Learning Agents Toolkit in a real game: a beginner’s guide
Is this article helpful for you?
Thank you for your feedback!
- Copyright © 2024 Unity Technologies