Data-centric AI with Unity Computer Vision Datasets





Developing production AI systems is challenging, but the return on investment is so appealing that many companies are including machine learning (ML)-based computer vision capabilities in their production applications and systems. Unity is reducing customers’ time to market and improving the quality of computer vision systems, further increasing data-centric AI development capabilities. Read more about how we quickly improved an ML model for which we had limited training data to achieve a 28% relative improvement in our baseline metric with Unity Computer Vision Datasets.
Unity Computer Vision Datasets is our solution for data-deficient computer vision applications. We work with you to build a custom data generator specifically designed to increase your training dataset sizes, enable you to conduct data experiments, improve your target metrics, and reduce your time to market.
In a previous blog post, we explained why computer vision features that operate in home environments can have data availability challenges due to privacy restrictions. To put our product to the test, we tasked ourselves with the challenge of improving the performance of a model that was initially trained on a limited real-world dataset.
The use case we selected was detecting dogs in a home environment as an example feature for a smart camera application. We used a subset of the COCO and OIDSv6 image datasets containing dogs in conjunction with common household items such as couches, microwaves and hair dryers since we were specifically interested in dogs that appeared in home environments. The resulting dataset was 1,538 dog images labeled with bounding boxes, which was then split into 1,200 training, 200 testing, and 138 validation images.
Establishing the baseline model and metrics
Our first objective was to produce a baseline model and baseline measurement using real-world data alone. We used the Faster RCNN architecture from Detectron2, pretrained with ImageNet weights, since it was readily available. Our metrics for this single-class object detection task were average precision (AP) and average recall (AR), averaged across IoU (Intersection over Union) from 0.5 to 0.95 with a step size of 0.05. We chose average precision/recall over mean average precision/recall because we were detecting only a single class. With such limited training data available, as is often the case with edge cases, we measured a performance baseline of 51.16 AP and 50.3 AR. At this stage, we did not perform any model optimization, and our top objective was to improve this baseline by keeping the model fixed and iterating only on the data.
Step 1: Improving our metrics using Unity Computer Vision Datasets
We used our Unity Computer Vision Datasets service, which allowed our content creation team to build and publish the environment, with exposed parameters such as lighting and placement randomization, for the ML developers to configure and produce data for their experiments. Once this data generator was published, the ML development team generated a dataset and retrained their model. We followed a practice that has shown positive outcomes in many projects of pretraining on the synthetic dataset and fine-tuning on the real dataset. The new results were 56.83 AP and 55.1 AR, which was an improvement for both metrics.


Step 2: Quickly producing an improved synthetic dataset
We started with some basic distribution analysis to compare the distribution of the synthetic and real datasets on a few dimensions to see if we could find any concerns that may lead to poor performance. Comparing the distribution of dog position within the 2D image, we found that there were some noticeable differences between the real and synthetic datasets, as seen in the figure below.
Dog positional distribution heatmap
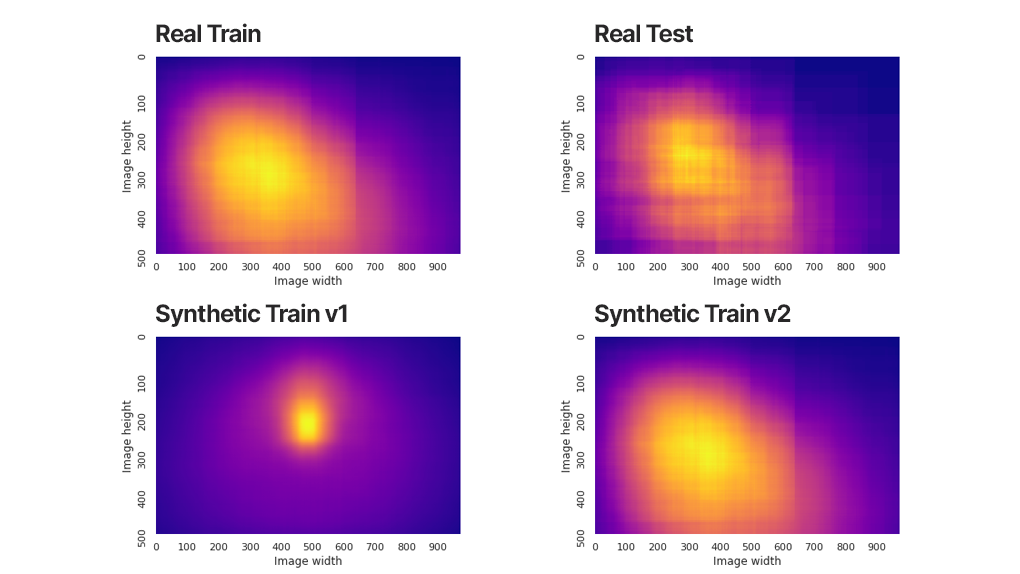
With this information alone, we could not conclude that the narrow distribution of dog positions in the synthetic training data was impactful to our target metrics. We quickly tried an experiment to see if broadening this distribution would have an impact. Because the synthetic data generator in Unity Computer Vision Datasets exposed a parameter involving 3D positional placement relative to the camera, the ML developers were able to generate a new dataset within about 30 minutes that results in higher diversity in dog position within the 2D image – without making any changes in the Unity project itself.
The team then retrained the model based on this new dataset (v2), which resulted in a small improvement to 57.18 AP and maintaining the same AR.
Step 3: Rapid experimentation with larger datasets
At this point, we were comfortable with the data generation strategy and parameters and decided to increase the dataset size. With Unity Computer Vision Datasets, creating a bigger dataset with the same configuration was easy. We decided to create two datasets, one consisting of 40,000 images and one of 100,000 images.
Unity Computer Vision Datasets, powered by Unity’s real-time rendering engine, scaled data generation horizontally in the cloud, which allowed us to create a realistic dataset of 100,000 images in less than 90 minutes. After retraining the model, we can see progressive improvements with the larger datasets.

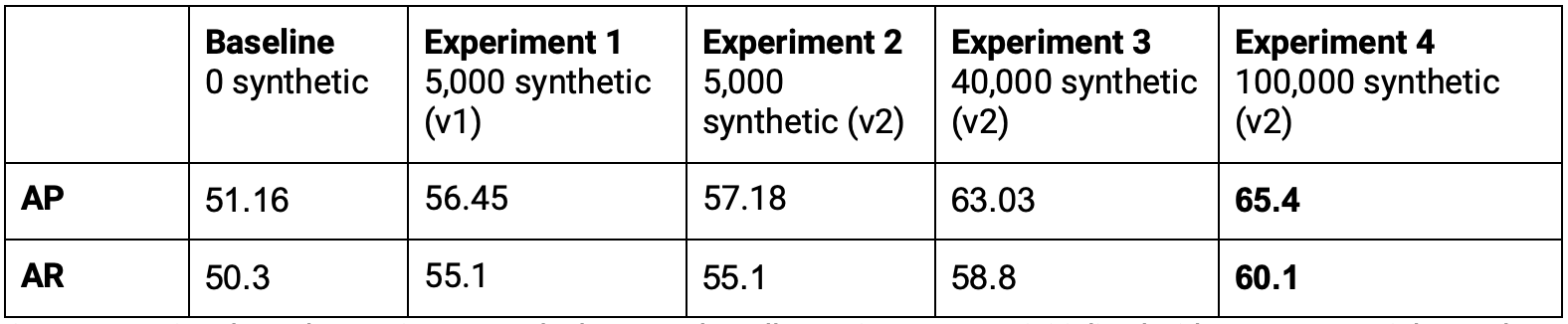
While this model is not quite ready to deploy into a production system, we were able to quickly move our key metrics by over 14 absolute AP and almost 10 absolute AR, by only iterating quickly on the data, and keeping the model fixed. We were able to complete the entire process of generating a 100,000-image dataset and training an updated model in under 5 hours. This is data-centric AI in action!
Github Sample Project
Please refer to this project which we used majorly for training the above mentioned experiments. The project provides scripts necessary for the specific use case of dog detection in an indoor home environment, as well as instructions on how to generate synthetic data for it using Unity Computer Vision Datasets. And after generating the required datasets, how to train & evaluate a model.
We have all the model checkpoint released, which were used for running our experiments, with different strategies around the amount of synthetic data. You can find all the experiments with their results for each checkpoint here.
If you want to try it out yourself please check out our space here.
Conclusion
Unity Computer Vision Datasets greatly facilitates collaboration between synthetic data developers and machine learning teams, improving the speed of iteration on synthetic data experiments. As teams iterate faster on experiments with synthetic data, they are able to more quickly create the best dataset that produces the best results.
Unity Computer Vision Datasets currently supports the following features:
- Custom “data generator” – Unity’s real-time 3D and machine learning experts build a custom data generator specific to your use case and made available only to your organization. For more information on this offering, contact us.
- Parametric synthetic dataset generation – Create datasets for prebuilt parametric environments for continued iteration and experimentation.
- Synthetic dataset hosting – Managing multiple synthetic datasets for a single project
- Dataset visualization – Visualize your dataset with ground truth labels.
- Download or transfer – Download the dataset to your local storage or to your Google Cloud Storage bucket.
- Free data generation – Generate up to 10,000 images for pre-built environments (General Object Detection, Home Interiors, and Retail).
Sign up for Unity Computer Vision Datasets today to explore our sample datasets and generate your own sample datasets with our pre-built environments!
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies