A Look Inside: Unity Release Management Series






I didn’t expect to be writing up this blog post. I initially wrote up an email congratulating the company on our release and highlighting changes during the 5.4 release cycle. However, Aras thought my email worthy enough to tweet and reveal a little behind the curtain. So, that became impetus for this series.
With the release of 5.4, there’s been a lot going on inside Unity at how we build things. There’s constant change going on for us, as we’ve been growing on all fronts. What used to be around 100 developers and QA folk when I started has grown to over 400. We did a lot of that growth during the 5.1 - 5.3 cycle, and keeping pace with the changes added strain.
We recognized during the previous year that while underlying code and systems were starting to improve, our usability, stability and perception were taking a pretty big hit. While we were always incrementally trying to improve, we took a couple more steps this round that I’d like to enumerate and talk about more in depth in this series.
Nothing here is necessarily ground-breaking in ideas, but these posts are hopefully illustrative of how scale and scope start requiring these changes. Simply put, this is a peek into our constant self-reflective improvement process and are the improvements Unity is implementing now.
Let’s start with some of the basic things and we’ll dive into bigger topics later.
A modest hardware upgrade to the build farm and faster build master server (katana) than previous rounds (with more to come!)
An odd issue to share is that our rather complex build farm (which has gotten the TeamCity to katana upgrade, and got far bigger and more complex) is currently limited to our Copenhagen office server room facilities. We are limited by physical space, cooling and power! There are technical architectural reasonings for the inability to move any time sooner, but we’re close to hitting our milestones in a project to shift out to an external data center. More on that another time.
With our heavy automation, numerous platform support, and distributed development, the build farm is a critical piece of infrastructure to support our development speed and quality. It is become nigh impossible for a single developer to do a full build and test locally due to the sheer number of platforms (maintaining, configuring, and simply the space). [ Aside: Every dev comes into Unity, including myself, thinking that “a build farm shouldn’t be that hard, at studio xxx or company yyy, we did it just fine.” Once they learn what’s going on here….it is that hard. ]
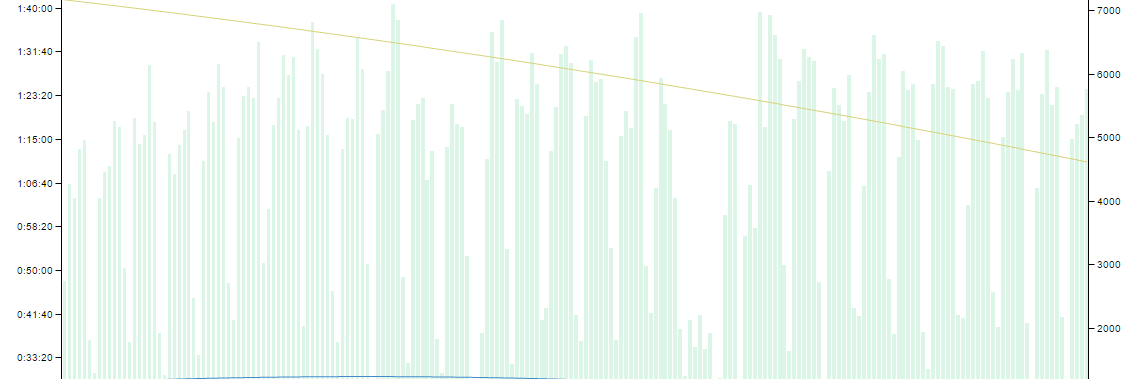
So, near the beginning of 5.4, we wrapped up upgrading the last of our rack servers to recent hardware, and pushed a new revision of our katana build master server yielding noticeable improvements in build times.

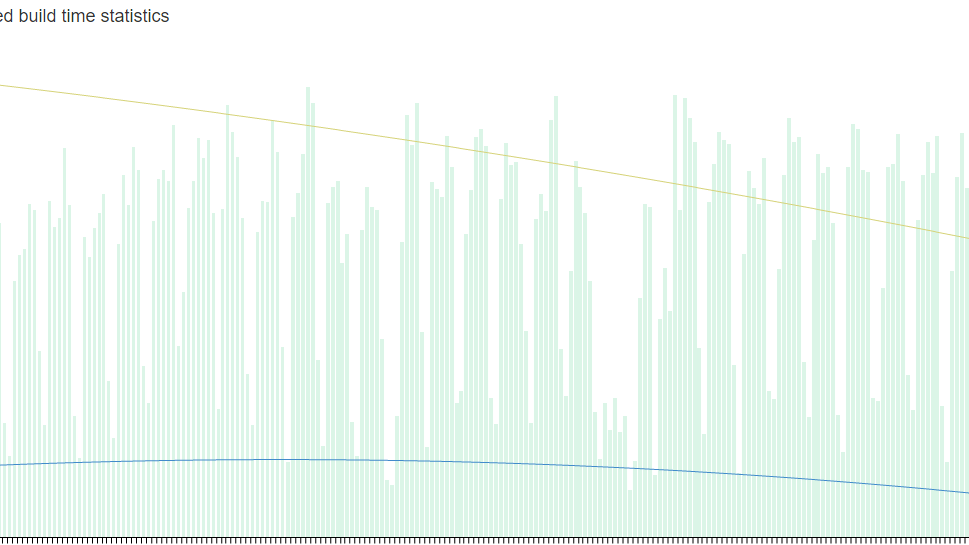
There’s a noticeable crevasse in that graph, which I can point out a longer maintenance window where some heavy debugging by our engineering tool operations team rooted out a bug in the CEPH cluster that since also helped streamline and improve overall farm performance by not causing nearly as many failures.
Every CPU cycle counts, as much as for you as it does for us. We are continuously investing in making the build farm more scalable and faster to serve not just ourselves, but ultimately all of you.
We minimized overlapping releases. 5.5 was iced for some time to give focus to 5.4
During the 5.0 - 5.3 cycle, we had to overlap pretty hard to keep a quarterly release schedule. Putting aside the development concerns, this put a multiplier strain on the whole organization from developers, QA, and support to build infrastructure. At the release of 5.3, we were managing 5 versions (4.7, 5.0 - 5.3) and had 5.4 already in the beginnings of development, so make that 6!
This caused a lot of split focus, let alone tracking concerns of what landed where.
During 5.4, we explicitly chose to defer 5.5 work further, only turning it back on recently and in limited scope. From the roadmap, you can see 5.5 has a number of things in it, but they’re fewer and more contained. By focusing on less quantity but more quality we intend to ramp back up the cycles, and also concern ourselves less about these overlaps.
We shifted more towards teams with inclusive QA yielding improved testing
While this seems like a trivial topic, and often some silly management-speak about agile or otherwise, we decided to experiment further with embedded QA. The reasoning was pretty simple: more often than not, developers would go off and “implement” and only present to QA when “done.”
By having QA more present and more engaged earlier in the process:
- We improved the schedule since the QA member has better overviews of what’s coming and can better overlap/interleave
- QA is never surprised by undiscovered work
- Workflow issues can be caught early
- Bugs are caught earlier as they’re made
- We can even have side-by-side usage and development, similar to sitting next to your game designer using a new tool
- We have much higher confidence when we bring the feature branch to a release branch
So far, we see the benefits outweighing any concerns thus far and more of our teams are happily embracing the shift. Again, nothing surprising about this. We’re just pointing out we’re doing more of it and that’s changed things.
One of the results out of this tighter teamwork are some great testing reports reviewing features and changes during their development. Check out a couple samples:
- Image Effect Bloom (available via bitbucket) during 5.4
- Particle Noise for upcoming alpha/beta
- Updated trail/line renderer for upcoming/beta

We opened the beta to the public, getting more pre-release feedback than ever before
Our early feedback has always been problematic. In the last year, we specifically identified the lack of beta participation. Our usage rates during 5.1 - 5.3 beta cycles didn’t even get close to 0.002% of our release usage, and it showed.
So, as the story went, we opened up beta for 5.4 to the public for any license.

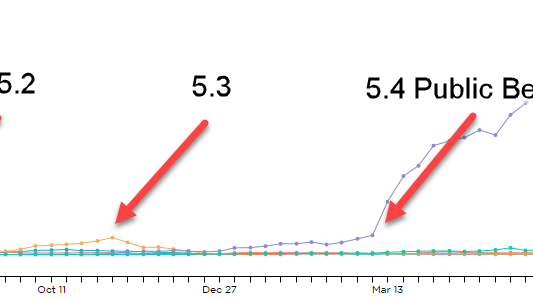
From the numbers, it’s clear that it had a staggering impact of increased usage, adoption and help us with getting more coverage for more of the pathways than ever before.
We upped our internal QA passes and improved test coverage
We can’t be pushing all our expectations of test coverage onto the beta. So, our QA group stepped up as well, increasing the number of passes and experimenting with new ways of going about testing to uncover what the users might run into. We redefined and re-focused our early test approach for new features into something internally dubbed the Feature Testing Framework - another topic for a future blog post.
In combination with the earlier mentioned QA embedding, we’ve been catching more of our issues earlier and fixing the either before they land or more quickly with a shorter reaction time.
Along with that, our test coverage has yet further expanded. Our current code coverage reports for automated tests show that our Editor and Runtime sources have ~70% function coverage now, with about 50% condition/decision coverage. We’re constantly adding further tests, which over time should reduce the introduction of future regressions.
We’re holding ourselves to higher standards
Unity’s grown a lot, and with that our users have also grown their expectations of us. We’d like to meet those expectations, so we’re buckling down and working on being more consistent and generally higher quality. We took some inspiration from Atlassian’s values about “Don’t #@!% the customer”, as well as take that to heart internally even amongst ourselves, “Don’t !@#$ on trunk.”
These may be crass phrasing, but everyone gets the idea quickly. Arguments can be settled pretty quickly by asking ourselves the question of on which side of the fence does a change fall?
Along with the shift in thought, we are also holding ourselves to higher review processes, attempting to quantify risks and better discipline. We’re also now valuing consistency, reliability and quality. We ask ourselves the question of how maintainable the code is, or what would the next developer say when they come across a given change.
We’re also currently digging pretty deep and re-factoring. The heavy leaning towards quality via bug fixes is also being proportionally matched with investments in fixing the underlying code base. The aim is to make it more modular and maintainable, which will make it easier to test. Of course, all this is ultimately for your benefit.
Future topics
That’s enough for now, but do stay tuned to as I will continue this blog series with the following topics:
- Changing our bug prioritization system to reflect "user pain"
- Keeping our release branch and trunk more stable and test "green" than any previous release
- More performance test coverage to watch the most dangerous of user complaints of regressions
- “Project Upgrade” focus to make sure users upgraded as cleanly as possible from previous version
- A crashes tracking tool letting us get some preliminary telemetry of our release
- Getting more information into the testers hands earlier
If you’re intrigued thus far, I hope you enjoy the series. Until next time (or release).
Is this article helpful for you?
Thank you for your feedback!
- Unity Labs
- Copyright © 2024 Unity Technologies